
一文上手用Pandas给数据加标签
数据标记是把信息标记分配给数据子集的过程。有许多标记数据集的例子。包含癌症和健康肺部的x射线图像以及相应的标签的数据就是标记数据的一个例子。
另一个例子是消费者信贷数据,它指定了消费者是否拖欠贷款。在获得标记数据集后,机器学习模型可以在标记数据上进行训练,并用于预测新的未标记样本。拥有良好的标记数据对于构建高性能机器学习模型至关重要。
在这篇文章中,我们将讨论使用python Pandas库生成有意义的标签的过程。我们将考虑标记数字数据的任务。出于我们的目的,我们将使用可以在这里找到的红酒质量数据集。
首先,让我们将数据读入一个Pandas dataframe:
import pandas as pddf_wine = pd.read_csv("winequality-red.csv")
接下来,使用’ .head() ‘方法读取前五行数据。
print(df_wine.head())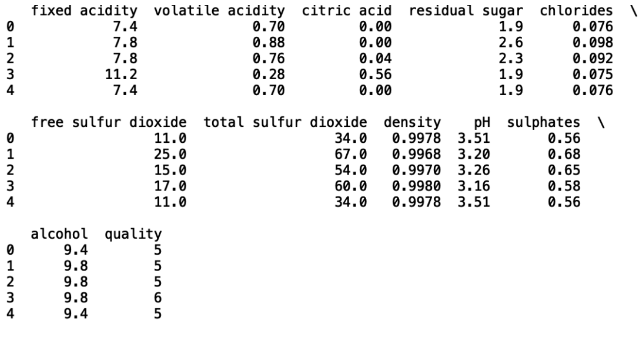
这些数据对应的是质量分数在0到10之间的葡萄酒。让我们看看数据中的值:
print("Quality values: ", set(df_wine['quality']))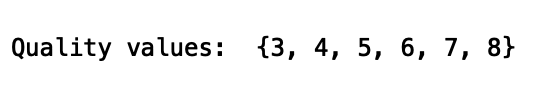
假设除了对葡萄酒质量进行分类,我们还对另一个分类问题感兴趣。让我们来考虑一下酒的酒精含量是否高于10%的问题,看看酒精百分比的最大值和最小值:
print("Max Alcohol %: ", df_wine['alcohol'].max())print("Min Alcohol %: ", df_wine['alcohol'].min())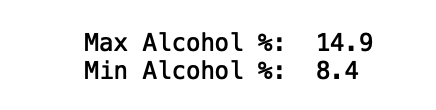
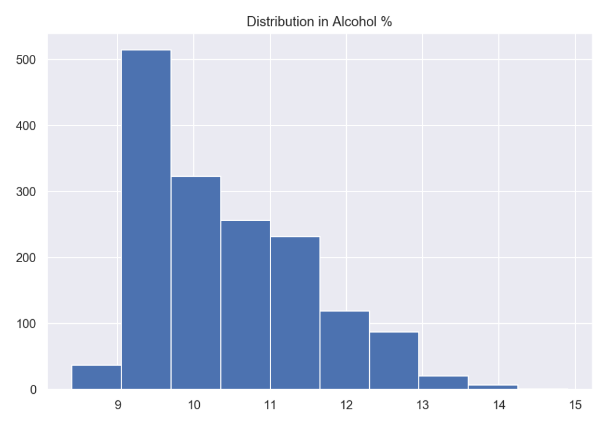
我们再画一下分布:
import matplotlib.pyplot as pltplt.title("Distribution in Alcohol %")df_wine['alcohol'].hist()
如果酒精百分比高于或等于10%,我们将用“1”标记数据,否则为“0”:
import numpy as npdf_wine['alcohol_class'] = np.where(df_wine['alcohol']>=10.0, '1', '0')
我们现在可以可视化二进制标签的分布:
from collections import Counterplt.title("Distribution in Alcohol Class Labels")plt.bar(dict(Counter(df_wine['alcohol_class'])).keys(), dict(Counter(df_wine['alcohol_class'])).values())
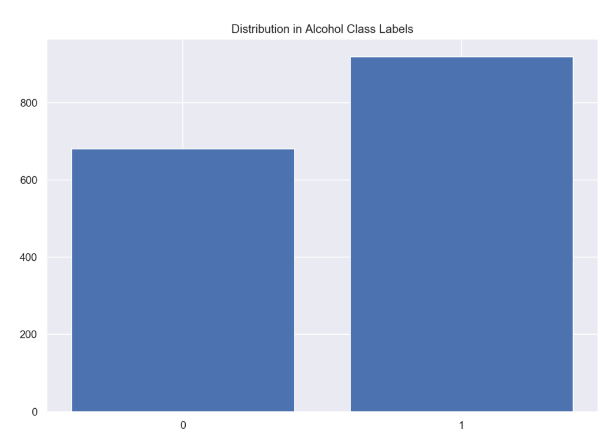
数据被适当地标记用于训练一个二分类模型。现在让我们来考虑一下二值分类之外的问题。如果我们看一下“固定酸度”的最大值和最小值,我们会发现这个值的范围比酒精的值更大:
print("Max fixed acidity %: ", df_wine['fixed acidity'].max())print("Min fixed acidity %: ", df_wine['fixed acidity'].min())

我们可以用Pandas中的‘.loc[]’方法为数据分配标签,将数据分成三组。标签‘0’将被赋值(4-7),‘1’将被赋值(7-9),‘2’将被赋值(9-16):
df_wine.loc[(df_wine['fixed acidity']>4.0) & (df_wine['fixed acidity']<=7.0), 'acidity_class'] = 0df_wine.loc[(df_wine['fixed acidity']>7.0) & (df_wine['fixed acidity']<=9.0), 'acidity_class'] = 1df_wine.loc[(df_wine['fixed acidity']>9.0) & (df_wine['fixed acidity']<=16.0), 'acidity_class'] = 2
我们现在可以可视化三元标签的分布:
plt.title("Distribution in Alcohol Class Labels")plt.bar(dict(Counter(df_wine['acidity_class'])).keys(), dict(Counter(df_wine['acidity_class'])).values())
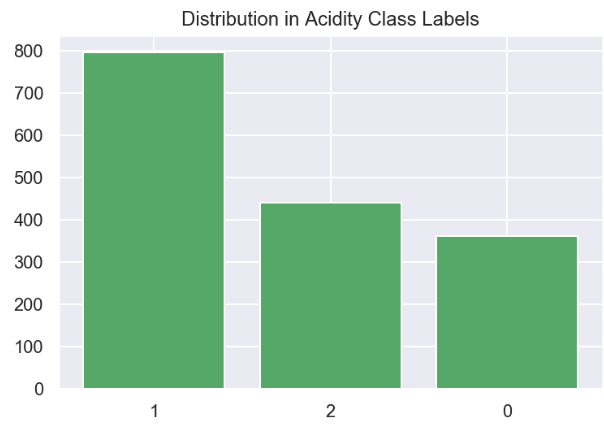
为了训练三元分类模型,数据被适当地标记了。这很容易扩展到四元、五元等等。我就讲到这里,但我鼓励你们自己去倒腾一下数据和代码~
结论
总结一下,在这篇文章中,我们讨论了如何使用Pandas来标记数据。首先,我们考虑了为葡萄酒数据分配二进制标签的任务,该任务指出葡萄酒的酒精含量按体积计算是否高于10%。然后,我们看了如何给酒标上标明固定酸度的三元标签。本文的代码可以在GitHub上找到。
原文作者:Sadrach Pierre, Ph.D.
翻译作者:Sophie Li
美工编辑:过儿
校对审稿:Dongdong
原文链接:https://towardsdatascience.com/labeling-data-with-pandas-9e573ce59c42




