
每个机器学习工程师都应该知道的线性代数!!
在数据科学的世界里,有一个概念使机器学习模型具有良好的数据表示、优化和操作,它就像机器学习模型的支柱。
是的,它正是线性代数。数据科学中建立和发展机器学习模型的基础。
在本文中,我们将探讨线性代数如何为数据科学中的机器学习做出贡献。它们有助于以图形化的方式理解机器学习模型,而我们人类擅长通过视觉几何来理解机器学习模型。如果你想了解更多关于机器学习的相关内容,可以阅读以下这些文章:
2023年面向开发者的十大机器学习(ML)工具
打好数据科学和机器学习的基础——6本书带你学数学
数据科学面试中的机器学习问题类型以及如何准备这些问题?
七个实用的Python机器学习库
因此,让我们深入了解使数据科学如此强大的基本线性代数。
首先,我们可以弄清楚什么是数据科学?
标题本身解释了你,利用数据和应用科学概念,如统计,概率和微积分,从中得出有意义的见解。
数据科学是理解过去的信息和预测未来的信息。
例子:
数据科学帮助我们预测未来,就像天气预报告诉我们明天是否下雨一样。这不是魔法,它使用了数字和机器学习。而是在数据中发现真相。它帮助我们回答问题和解决问题。
现在我们可以开始讨论什么是线性代数以及为什么我们需要在数据科学中使用线性代数。
线性代数是研究向量空间、矩阵和每个向量的线性关系的数学分支。它使我们能够解决不同领域的复杂问题,从工程和物理到数据科学和计算机图形学。
现在让我们看看为什么它在数据科学中很重要。
在数据科学的背景下,特别是在机器学习中,当处理具有众多特征的数据集时,线性代数的意义变得明显,这使得可视化和人工判断具有挑战性。虽然我们可以很容易地在二维或三维笛卡尔空间中可视化和绘制线条,但现实世界的数据集通常涉及高维空间(n维),这是不切实际的可视化。这就是线性代数发挥作用的地方。它允许我们将数学原理应用于机器学习模型,从而能够在n维空间中创建决策边界或平面,以进行准确的数据分类和分析。
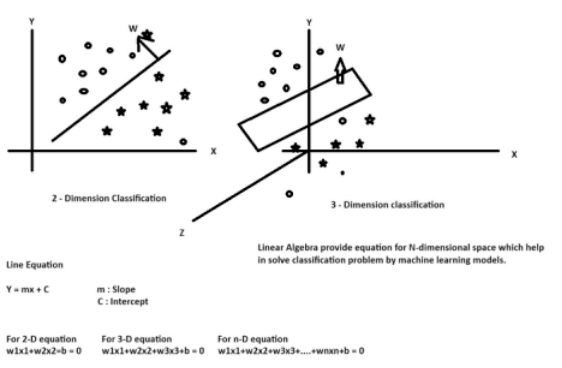
线性代数是数据科学中机器学习模型算法的主干。
它在数据科学的发展过程中占据重要的角色,例如:
✅数据表示中的线性代数
✅数据预处理中的线性代数
✅降维中的线性代数
✅特征工程中的线性代数
✅机器学习算法中的线性代数
✅推荐系统中的线性代数
✅模型解释中的线性代数
让我们就上述话题逐一讨论。
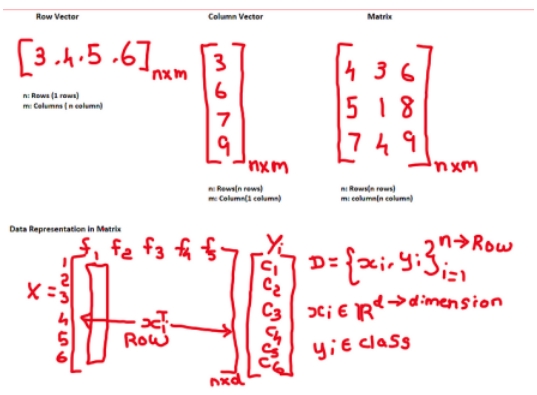
01 数据表示中的线性代数
数据表示包括将数据转换为向量和矩阵,这些向量和矩阵是结构化的数学对象,可以通过操作来执行加法、乘法和变换等操作。
➡️向量-它表示来自整个数据的单个数据点。
➡️矩阵-它用多个特征列表示,简称为数据集。
➡️矩阵运算-如加法,减法和乘法的矩阵运算,有助于各种转换和建模技术。
➡️矩阵转置-它创建一个新的矩阵,其中行成为列,列变成行。
➡️稀疏矩阵-稀疏矩阵是一个矩阵,其中大多数元素为零。它用于处理大多数值为零的大型数据集或高维数据,例如文本数据(术语-文档矩阵)或某些科学模拟。
➡️密集矩阵-密集矩阵是一个矩阵,其中大多数元素是非零的。当你有一个相对较小的矩阵,大多数条目都是非零的,或者计算效率比内存使用更重要时使用。
➡️奇异矩阵-奇异矩阵是一个没有逆矩阵的方阵(具有相同行数和列数的矩阵)。
02 数据预处理中的线性代数
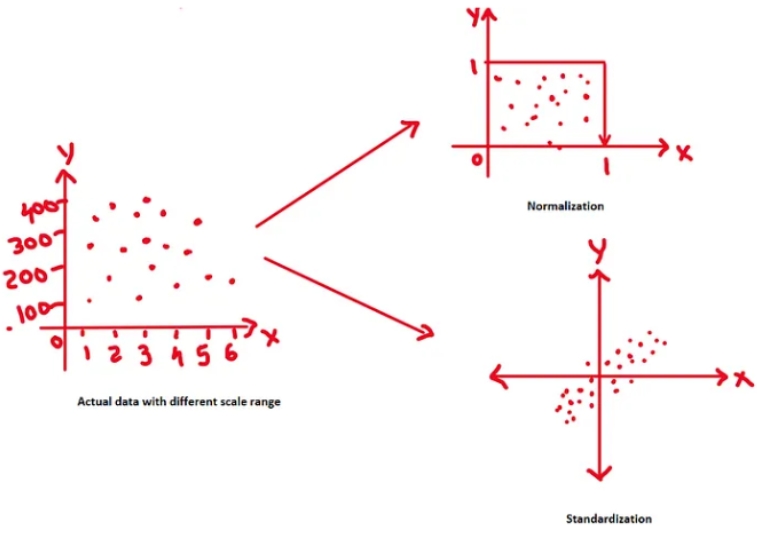
线性代数背景下的数据预处理涉及应用于原始数据的各种技术和操作,以使其适合使用线性代数进行分析、建模或其他数学运算。
➡️数据缩放-它用于将数据集的数字特征转换和标准化到一个通用的规模,并确保所有特征对分析和建模过程的贡献相同。
➡️归一化——它将数据缩放到一个特定的范围,通常在0到1之间。
公式:(X – X_min) / (X_max – X_min)
➡️标准化-它将数据缩放为平均值为0,标准差为1。
公式:(X – mean(X)) / std(X)
➡️健壮缩放-它通过减去中位数并除以四分位数范围(IQR)来缩放数据。与最小-最大缩放和标准化相比,它对异常值不太敏感。
公式:(X – median(X)) / IQR(X)
03 降维中的线性代数
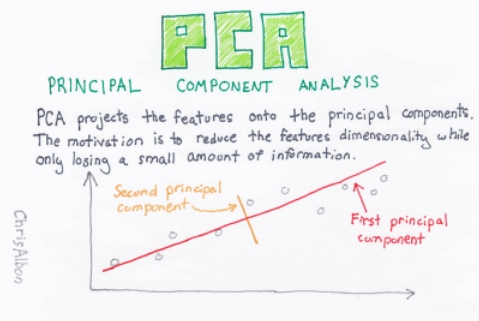
线性代数在降维技术中起着基本的作用,它用于减少数据集中的特征(维度)数量,同时保留尽可能多的相关信息。线性代数技术如PCA和特征分解在这些方法中常用。
➡️特征值-特征值(λ)是与方阵(通常表示为a)相关的标量。它们表示矩阵如何沿着某些方向缩放或拉伸空间。
➡️特征向量-特征向量(v)是对应于特征值(λ)的非零向量。当与矩阵A相乘时,特征向量仅缩放,特征值为缩放因子:A * v = λ * v。
➡️主成分分析(PCA)- PCA是一种流行的线性降维技术,它使用线性代数将数据转换为新的坐标系统。
它计算数据协方差矩阵的特征向量和特征值。
使用特征向量计算原始特征的线性组合以创建新特征(主成分)。
这些主成分按特征值大小排序,允许你选择保留一个子集,同时丢弃信息较少的成分。
➡️奇异值分解(SVD)—SVD是一种线性代数技术,可以应用于术语文档矩阵来执行降维或特征提取。
通过将TDM分解为三个矩阵(U,Σ,V^T),
其中U和V是正交矩阵,Σ是奇异值的对角矩阵,你可以提取数据中最重要的维度(主题)。
04 特征工程中的线性代数
线性代数在特征工程中扮演着重要的角色,特征工程是创建新特征或转换现有特征以提高机器学习模型性能的过程。
➡️特征变换-线性代数允许你对特征应用各种变换。例如,你可以取特征的平方根或对数来改变其分布,使其更适合某些算法。特征变换还可以帮助减少偏度或使数据更加线性,这对线性模型是有益的。
➡️特征组合-线性代数允许通过现有特征的交叉积创建新特征。例如,在多项式回归中,可以通过将两个或多个特征相乘来生成交互项。
➡️特征选择-特征选择中的正向选择和向后消除等技术通常涉及线性代数计算。这些方法的目的是根据特征对模型性能的影响来识别信息最多的特征子集。
➡️编码分类变量-分类变量的One-hot编码和其他编码技术涉及线性代数操作。例如,one-hot编码创建二进制向量,将分类值表示为数字特征。
05 机器学习算法中的线性代数
在数学中,尤其是线性代数,构成了许多机器学习算法的基础。
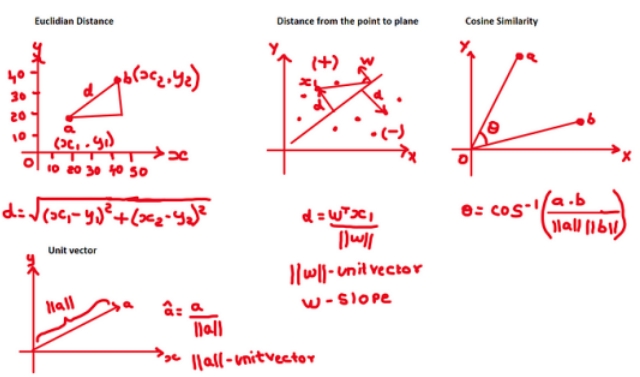
➡️欧几里得距离-欧几里得空间中两点之间直线距离的度量。这个概念主要用于K-NN机器学习算法。
➡️曼哈顿距离——这是一个基于网格的系统中两点之间距离的度量,比如城市网格,在那里你只能水平或垂直移动(不能对角线)。这个概念被用于K-NN、层次聚类和基于密度的聚类算法。
➡️单位矢量-单位矢量,也称为归一化矢量,是一个大小(或长度)为1的矢量。它的方向和原来的向量一样,但是被缩小了,长度是1。这个概念被用于支持向量机算法。
➡️从点到平面的距离-这是从点到平面的最短距离,意思是沿着垂直线从点到平面的距离。如果结果是正的,这意味着该点和法向量在平面的同一侧如果结果是负的,它在平面的另一侧。这个概念主要用于线性和逻辑回归以及支持向量机算法。
➡️核函数-这种转换允许线性算法解决非线性问题。通过在原始特征空间中工作,可以有效地执行复杂的计算。这个概念主要用于支持向量机。
- 线性核:表示原始数据没有任何转换,本质上是执行线性计算。
- 多项式核函数:使用多项式函数将数据映射到高维空间,例如K(x,y)=(x⋅y+c)d,其中d是多项式的度。
- 径向基函数(RBF)核:通常用于类高斯变换,K(x,y)=exp(−γ∥x−y∥2),其中γ是一个正常数。
06 推荐系统中的线性代数
线性代数在推荐系统中起着重要的作用,推荐系统是一种算法,旨在根据用户的偏好和行为向他们推荐商品(例如,产品、电影、音乐、文章)。
➡️矩阵分解-矩阵分解技术,包括奇异值分解(SVD)、非负矩阵分解(NMF)和梯度下降矩阵分解,广泛应用于推荐系统。这些技术将用户-物品交互矩阵分解为表示用户和物品潜在因素的低维矩阵。
➡️用户-物品交互矩阵——在推荐系统中,用户行为和偏好通常在用户-物品交互矩阵中表示。这个矩阵以用户为行,以项目为列,条目表示用户与项目的交互(例如,评级、购买历史记录、点击)。线性代数运算,如矩阵乘法,被用来分析和处理这个交互矩阵。
➡️基于内容的过滤——基于内容的推荐系统使用线性代数来表示项目和用户配置文件作为特征向量。像向量点积和相似度计算这样的线性代数操作可以帮助找到基于特征向量的与用户个人资料匹配的项目。
➡️协同过滤——协同过滤方法,如基于用户和基于项目的协同过滤,利用线性代数来计算用户或项目之间的相似性。这种方法有助于识别彼此相似的用户或项目,并根据相似用户的偏好推荐项目。
➡️余弦相似度-它是两个向量之间夹角的余弦值的度量,提供了它们的相似度的度量,而不管它们的大小。
07 模型解释中的线性代数
使用线性代数的模型解释涉及对机器学习模型的系数、变量之间的关系以及单个特征对模型预测影响的详细分析。
➡️系数解释-在线性回归中,模型可以表示为:
y^ =β0 +β 1×1 +β 2×2 +…+β pxp
Y ^是预测的目标变量。
β0是截距或偏置项。
β1,β2,…,βp是预测变量x1,x2,…,xp的系数。
这些系数表示在保持所有其他预测变量不变的情况下,对应预测变量发生一个单位变化时预测目标变量的变化。
➡️正交化-线性代数允许你正交化预测变量,使它们不相关。这简化了解释,因为你可以独立分析每个特性的影响。
➡️残差分析-线性代数帮助计算残差,即实际值和预测值之间的差异。残差图可以用来评估模型的拟合和检测模式或非线性。
➡️特征重要性-要了解哪些特征是重要的,你可以检查系数的大小。绝对值越大,表示对目标变量的影响越大。
综上所述,线性代数是基础数学框架,是数据科学的核心原理。从数据操作和转换到机器学习模型解释,线性代数是每个数据科学家都应该知道的不可或缺的工具。通过理解关键概念,如矩阵、向量、特征值和特征向量,数据科学家可以有效地处理、分析和提取复杂数据集的见解。
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Dhilip Maharish
翻译作者:过儿
美工编辑:过儿
校对审稿:Chuang
原文链接:https://pub.aimind.so/linear-algebra-that-every-data-scientist-should-know-eb585e0ef18d




