
Linear regression 5道经典必考题自测
Linear regression 一直都是数据分析岗的必备技能,我们数据应用学院的往届学员也反映,经常在面试中被考察到linear regression的相关知识。那么,正在求职的你们是否能hold住线性回归面试题的轰炸呢?先搬个小板凳,来回答下面的问题试试。
1. State the assumptions in linear regression model
2. How to avoid overfitting in linear regression?
3. Explain gradient descent with respect to linear regression
4. How to choose the value of the parameter learning rate α?
5. How to choose the regularization parameter l?
感觉怎么样?
如果你觉得轻松无压力,那祝贺你,你可以跳过这篇文章了。否则,赶紧拿出一杯咖啡的时间,坐下认真学线性回归!
上周六的公开课,我们请到了kenan老师为大家详解线性回归。
所谓线性回归,指的就是自变量x和函数值y之间存在线性相关关系。自变量x可以有很多,但y只有一个,它们之间满足下图中的公式。
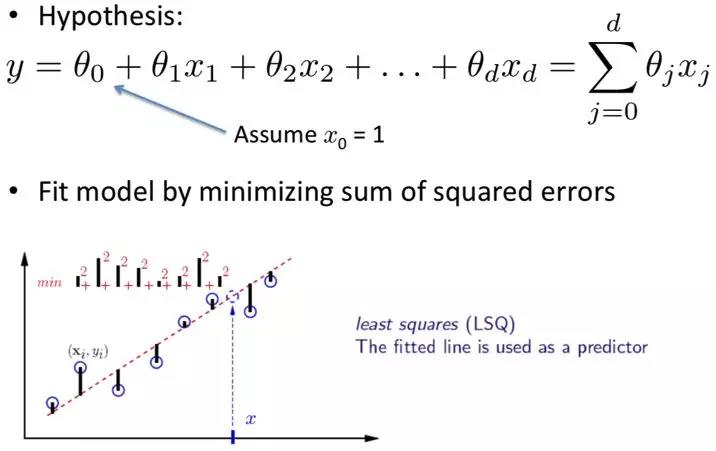
在什么情况下可以使用linear regression进行分析呢?
其实很简单,绘制散点图,如果发现数据有明显的线性关系,就可以使用线性回归了。那么怎么才能pick出那条心仪的直线呢?
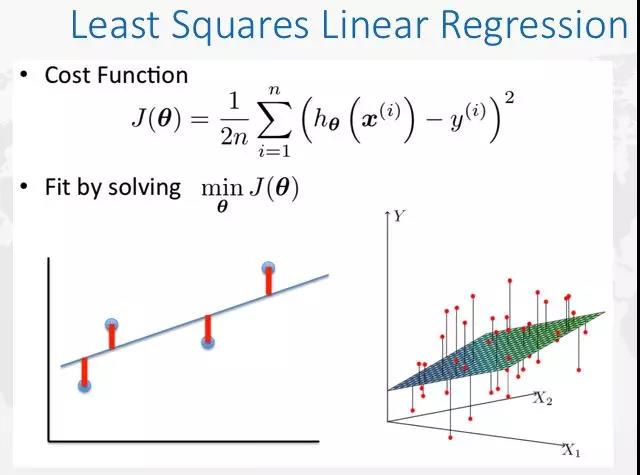
满足残差平方和最小的那条直线就是啦!
也就是说,每个预测值与真实值之间都是有误差的,将这些误差的平方和加起来再平均,就得到了它的cost function(如下图)。接下来要做的,就是求cost function的最小值。
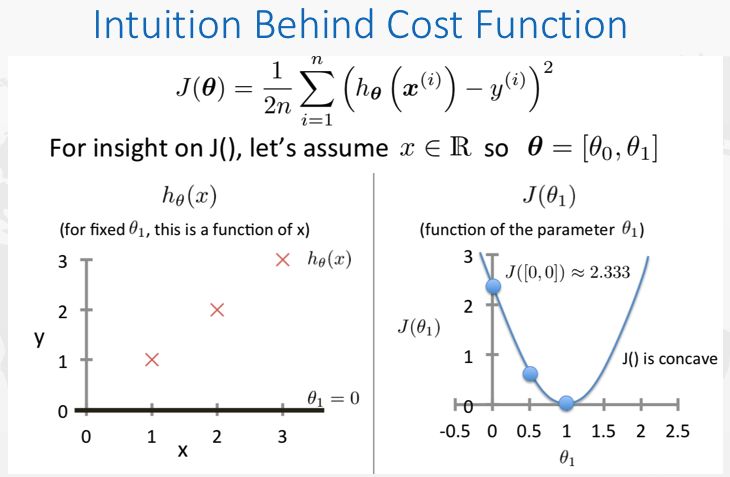
如果说只有单变量x1的话,数据在一个二维的平面上,问题就变得非常简单,直接求这个二次函数的极值就可以。
然鹅,如果有多个变量,比如三个变量,问题就变成了求下面这个图平面的最小值,就没有那么容易了。
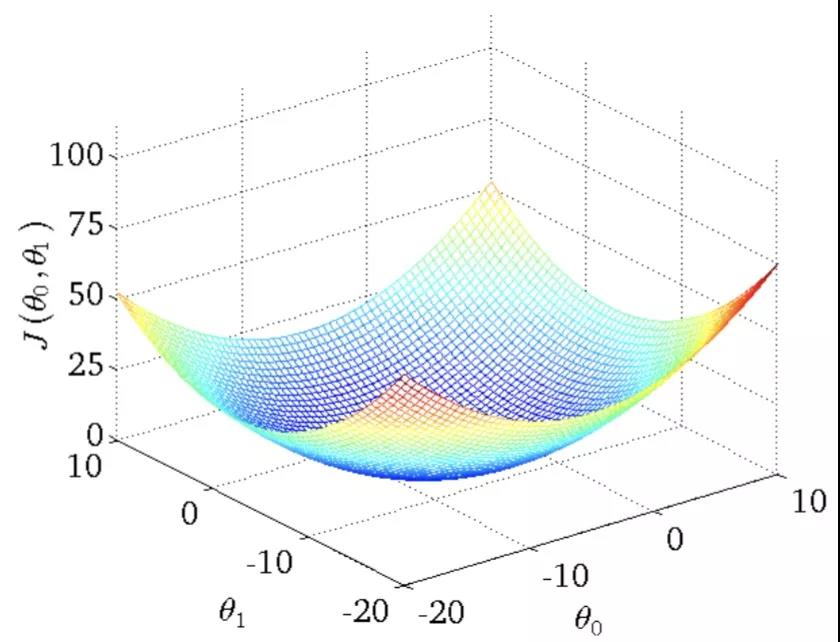
这时候就要用到著名的gradient descent 算法啦。
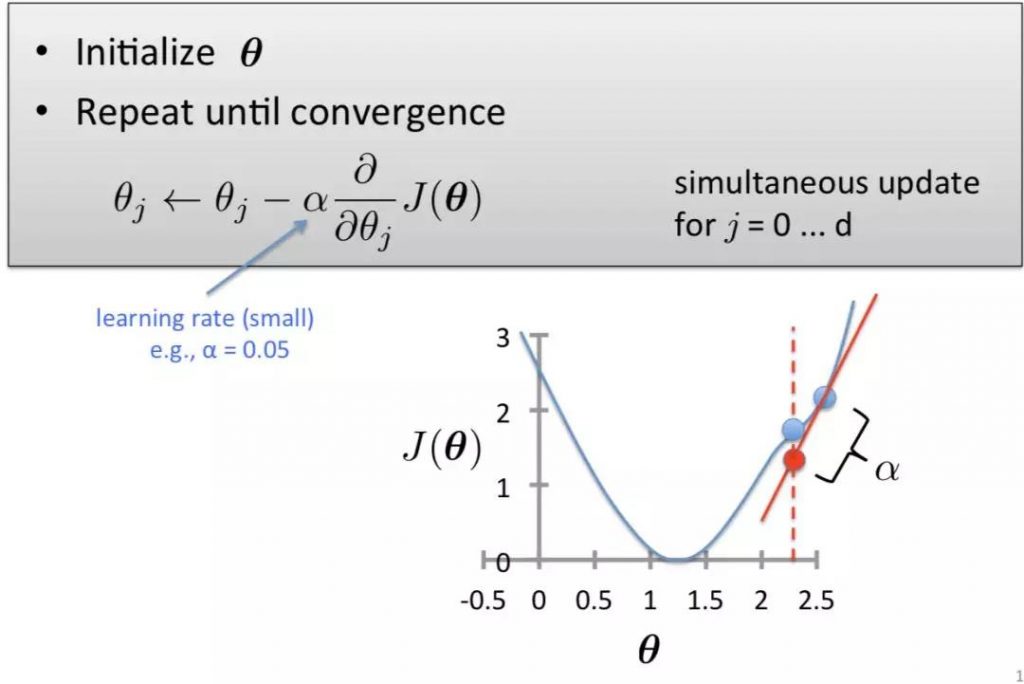
简而言之就是,先初始化一些θ值,然后用上图的公式,对θ进行迭代,θ会逐渐到达最低点。

在实际分析的过程中,我们是不知道什么时候θ已经接近最低点了的,应该如何判定呢?
设定一个e,当满足下面的条件时,gradient descent就会自己停止下来。厉害不 ?Python线性回归分析背后的代码其实就是这么写的。

可能有细心的同学会问了,上面公式中的α是什么呢?
α就是模型的learning rate,它决定了θ converge的快慢。如果α太小,converge速度就会很慢;如果α太大,θ就会无法取到最小值。
所以,要提升模型的performance,就要多尝试,选出合适的α。
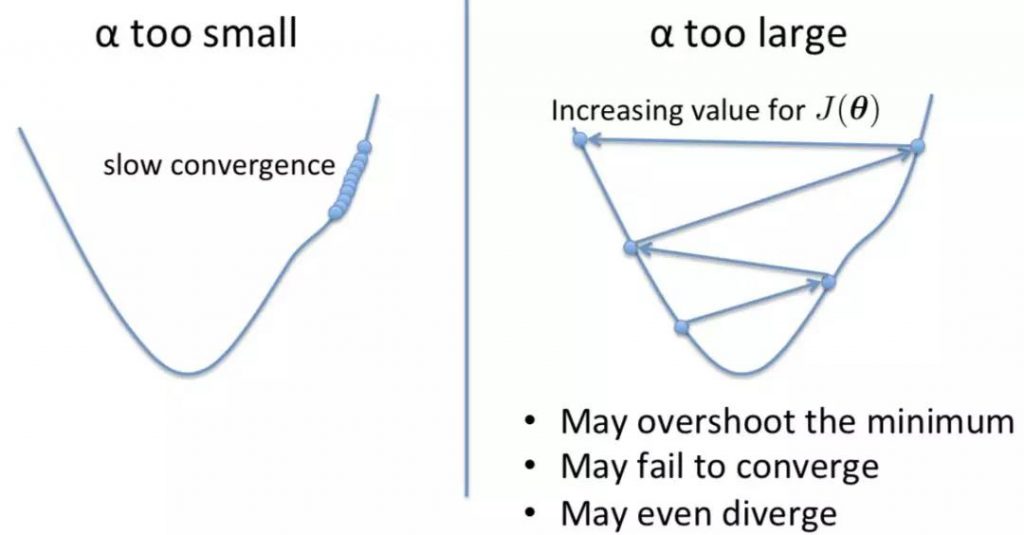
除此之外,feature scaling也可以提高模型学习速度哟

不过要注意,在这之前要先清除outlier,因为outlier会对数据集的平均值有非常大的影响。而且,feature scaling必须保证训练集和测试集有类似分布才可以进行。都是面试考点鸭!
在数据拟合的过程中,可能会underfitting,也可能会overfitting。
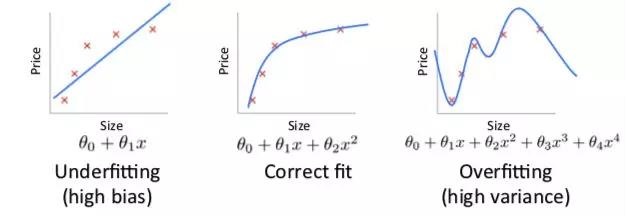
Underfitting很好理解,就是模型太简单,所以应该让模型更复杂一些。所谓overfitting呢,就是模型过于复杂,过于完美的拟合了训练集,但却无法拟合新的测试集。
面对这种模型过于复杂的情况,你们知道怎么做么?
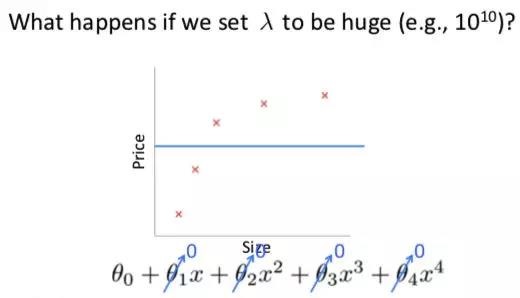
可以减小每个自变量前面的系数,也就是减少自变量的权重,从而控制模型的复杂度。也就是所谓的regularization。

需要注意的是,l和α一样,都需要经过多次地尝试,取到合适的值,否则会影响模型的performance。l太小的话,可能起不到明显的效果;l太大的话,有可能本来模型过于复杂,这一下子模型一夜回到解放前,又变得过于简单了️。
有没有觉得受益匪浅?





