
机器学习工作流程第一步:如何用Python做数据准备?
—— 来自Matthew Mayo, KDnuggets
然而,有些苦活累活你自己做也是有价值的,即便是作为一种教育性的努力。我不是要推荐你们从零开始通过自己深度学习练习写出一个程序框架,至少不能一直这样,但哪怕只有一次通过不断的试验和失败,从头开始写出和自己的算实现它们的支持工具也是非常好的。我可能说的不对,但我认为如今在学习机器学习能力、数据科学、人工智能等方面的大多数人都没有在这么做。
所以让我们从头开始,来学习在Python里建立一些机器学习能力的相关知识。
我们需要从一个点入手,那就让我们从一些简单的数据准备任务开始吧。开始的时候我们会慢一点,但当我们对(要学习的东西)有了一点感觉以后,我们会逐渐加快速度。除了数据准备,我们还需要数据转换、结果演示和呈现工具——更不必说机器学习能力算法了——来达成我们我们即将要完成的目标。
我们的想法是手动拼接任何我们需要的重大功能,以便完成我们的机器学习能力任务。当序列展开的时候,我们可以添加新的工具和算法,同时我们也能重新思考我们以前的假设(是否正确),使整个过程尽可能重复迭代,就像它会渐近一样。慢慢的,我们会集中精力在我们的目标上,制定策略来完成目标,把它们运用到Python里,再检验它们是否能够运行。
最终的结果,就想我们现在预期的一样,会是有序排列在我们自己的简易的机器学习数据库中的一系列简单的Python模型。对于初学者,我相信这是理解机器学习过程、工作流和算法如何运行的非常宝贵的经验。
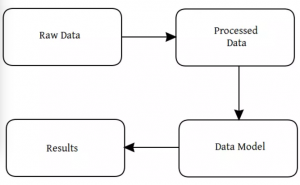
- 获取数据
- 处理/准备数据
- 建立模型
- 解释呈现结果
在我们真正做的时候我们可以拓展,但是这是我们现在自己设计的简单的机器学习的过程框架。同时,“输送管(小箭头)”暗含了把工作流中各功能聚集在一起的能力,所以让我们把这些记住然后继续向前。
让我们来看一看:
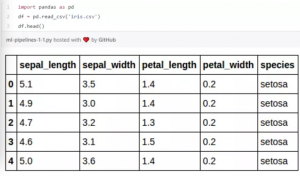
- 数据需要储存成CSV格式的文件
- 实例大部分由有数字属性的值组成
- 组别是经过分组的内容
到目前为止,以上没有一种是对所有的数据集都适用的,但是也没有任何一个是只能适用于某一种数据集的。这使得我们能够有机会编写我们可以以后重复使用的代码。好的编程练习会让我们集中于重复利用性和模块性。
一些简单的探索性数据分析被罗列如下:
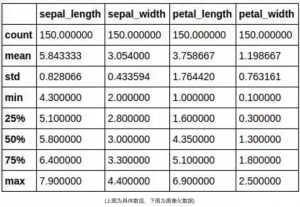
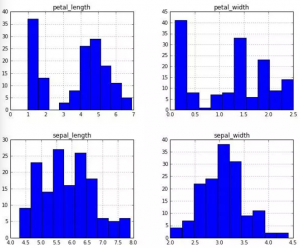
最终,我们也需要一个对我们自己的算法的更好的数据呈现,所以我们在继续向前进行之前会确保我们最终呈现的是一个矩阵——或者numpy nadarry。我们的数据准备工作流接下来会做一下的表格:
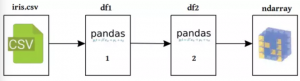
首先,让我们写一个简单的函数,把一个CSV文件上传到DataFrame。当然,这在内网做很容易,但是再往前想一步我们可能想再加一些额外的步骤到我们自己的数据集里以便我们以后上载函数。


有一些错误检查存在,但它还并不是很健全,所以我们或许可以晚一点再回来说这个话题。此外,逐条读文件再逐条决定要对这些行做什么,比直接用内置功能把处理干净的一致的cs一文件直接读到DataFrame中要慢,但权衡之后我们发现允许更多的灵活性,在这一阶段是值得的(但读大的文件可能会发花费很久的时间)。不要忘了,如果一部分内置操作不是最好的方法,我们可以晚一些再做调整。
在我们尝试运行自己的编码之前,我们需要来写一个函数,把名字类数值转化成数字类数值。为了推广函数,我们需要使它能够用于数据集中的任何属性的数值,不仅仅是运用于不同的类别。我们还应该跟踪属性名称最终是否成为了整数。有了之前把csv或ts me的数据文件上传pandas的DataFrame的步骤经验,这个函数应该同时接受一个pandas DataFrames以及被转化为数字的属性名称。
我们还要注意,我们回避了关于使用单热编码的话题,这涉及到分类的非分类属性,但我认为我们以后还会回到这个话题。

现在我们可以从文件中加载一个数据集,然后把分类属性值转换成数字属性值(我们也可以保留这些映像在字典中供以后使用)。就像之前提到的,我们希望我们的数据集最终是以numpy ndarry的形式存在,这样我们可以在自己的算法中很简单的使用。同样的,这是一个简单的任务,但写一个函数会让我们在以后需要的时候还可以以此为准。
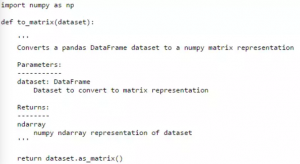
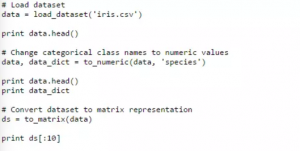
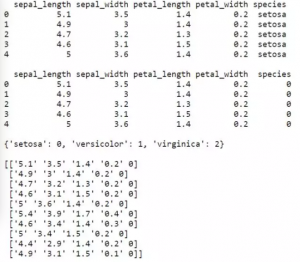
练习机器学习就是理解机器学习的最好方法。运用我们的工作流中需要的算法和支持工具最终会被证明是有用的。





