
数据届Cosmo大赏第一名的包是谁?

如果你要使用Python学习Machine Learning的话,Scikit Learn 无疑是最核心的工具了。它提供了非常多的监督学习和非监督学习的算法,而且它也是最简单最容易上手的机器学习工具包了。
Scikit Learn是基于软件工程的思想创建的,它的API的核心设计理念就是要易于上手且功能强大,方便工业界使用的同时,也适用于学界做研究。这种设计理念让Scikit Learn非常适合端到端的机器学习的项目,从学界的研究一直到产品的落地。

Scikit Learn是在很多Python常见的数据计算的工具包的基础上创建的,这就很容易将它们整合起来,在使用Scikit Learn分析建模的过程中直接调用NumPy Arrays或者pandas Dataframe等数据结构。
Scikit Learn 使用了如下这些工具包:
– NumPy: 数字运算和矩阵运算
– SciPy: 科学和数据运算
– Matplotlib: 数据可视化
– IPython: 交互式Python
– Sympy: 符号数学
– Pandas: 数据处理和分析
Scikit Learn主要聚焦于机器学习和分析建模,它并不精通数据导入,数据分析和数据可视化。所以,上面提到的各种工具包就派上用场了,尤其是Numpy。这些工具包都是相辅相成的。
Scikit Learn内置的算法有:
– Regression: 拟合线性与非线性模型
– Clustering: 无监督分类
– Decision Trees: 决策树的推导和修剪,解决分类问题与回归问题
– Neural Networks: 针对分类与回归问题的端对端的训练
– SVMs: 判定决策边界
– Naïve Bayes: 概率模型
除此之外,它还有由其他工具包提供的更方便高级的功能:
– 集成方法:Boosting, Bagging, Random Forest, Model voting and averaging
– 特征操作:Dimensionality reduction, feature selection, feature analysis
– 异常值检测:For detecting outliers and rejecting noise
– 模型挑选和检测:Cross-validation, Hyperparameter tuning, and metrics

为了让大家明白Scikit Learn有多容易上手,这里就为大家演示一个决策树分类器的调用流程。

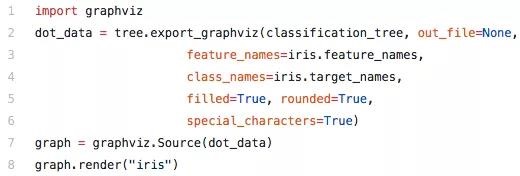
用决策树解决分类和回归问题非常简单,只需要调用内置的tree模型就好了。首先将Scikit Learn工具包中自带的数据集引入进来,然后调用决策树分类器。每一步都只需要一行而已。然后,把数据集里的数值X和目标值Y都fit到分类器中,就可以得到你想要的决策树了。
Scikit Learn还可以使用graphviz工具包把得到的决策树绘制出来,这样一来,也方便了我们数据分析部门和其他部门进行交流,解释我们的模型。它还提供了很多参数,让使用者根据实际需求调节决策树的表现形式。
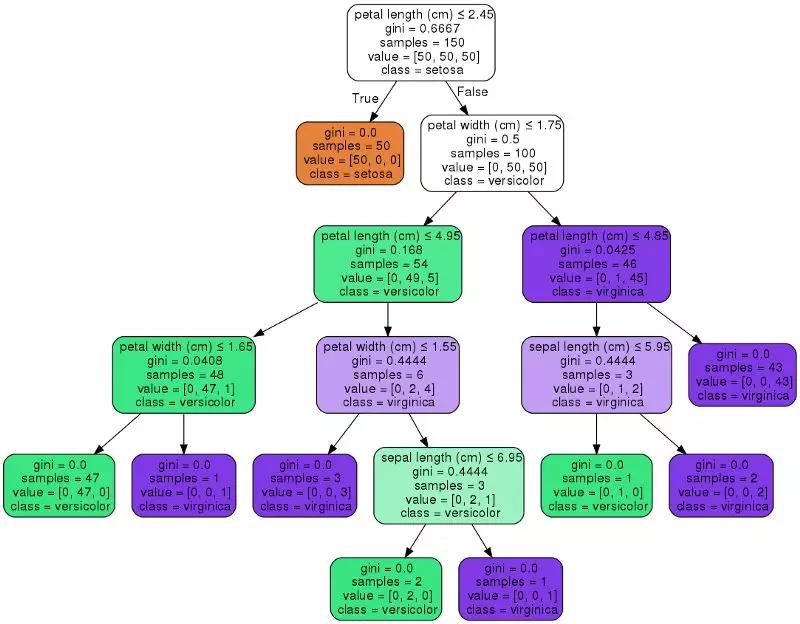
除此之外,Scikit Learn的官方文档也是不可多得的学习工具!每一个算法的参数都有清晰合理的命名和解释。而且,每一个模型都有详细的解释、样例及其源代码、模型的优缺点和适合使用的场景。
原文作者:George Seif
翻译作者:唐唐
美工编辑:Miya
校对审稿:卡里





