
Nvidia数据科学家超级工作台——32 CPU线程,96G GPU显存,192G内存,自带所有ML&DL包
在过去的几年里,人们对数据科学的兴趣激增,以至于许多公司正在重新定位他们的商业战略,并将自己定义为“数据驱动”的公司。
这么做的理由很简单: 更多的数据可以为我们提供了更大的机会来分析见解和创造更大的商业价值。
而大数据集的处理是需要强大的计算能力的。你将需要一个很好的CPU,理想情况下具有许多核心,比如Intel Xeon类型的处理器。大量的RAM是一个明确的需求——数据科学家使用64甚至128GB的RAM并不少见,有时甚至还不够!The Nvidia Quadro RTX 8000 GPU has 48GB of VRAM
更重要的是,随着Deep Learning的流行,GPU现在正在向数据科学进军。GPU可以被用来加速大型数据流的运行和可视化速度(与Pandas相似)。一直流行的XGBoost就自带内置的GPU加速。
Nvidia最近发布了他们的数据科学工作台,这是一台将所有数据科学的硬件和软件集成到一个程序包中的计算机。这个计算机是一个强大的机器,包含了所有的计算能力和软件。这对于处理数据是非常有用。
我最近有机会测试和检查数据科学计算机,所以我们将在本文中详细讨论它。
规格
我测试的计算机是由Boxx构建的。它预装了所有的硬件和软件,外加一些额外的电缆以防万一。让机器预先构建是伟大的,因为这可能需要好几个小时。以下是主要硬件规格:
· CPU – 2 Intel Xeon SP Gold 5217, 8核/ 16线程各@ 3.0Ghz
· RAM – 192GB DDR4-2933 MHz ECC
· 存储- 1.0TB SSD M.2 PCIe驱动器
· GPU – 2 NVIDIA Quadro RTX 8000的,每个有48GB的VRAM
加上鼠标、键盘和3年保修。
当你想让你的钱花得更值的时候,定制一台机器总是最好的选择。这台机器附带的部件挑选得恰到好处:32个线程来自用于并行处理的CPU,大量的高速RAM,一个PCIe SSD (比标准SATA驱动器快得多) ,以及2个具有48GB的VRAM的GPU。
Boxx的数据科学工作站。虽然它是为数据科学而设计的,但它仍然带有所有标准端口,包括USB、音频、麦克风和磁盘驱动器
然后是经常被低估的部分:软件。计算机预装了Ubuntu 18.04和几乎所有你想要安装的数据科学和机器学习库以及软件。举几个例子:
· Data and ML — pandas, numpy, scipy, numba, matplotlib, xgboost, dask, scikit-learn, h5py, cython
· Deep Learning — TensorFlow, Keras, PyTorch, NLTK
· Nvidia — GPU Drivers, CUDA 10, cuDNN, RAPIDS
所有这些Python库都打包在Python虚拟环境中,以避免将来发生任何冲突。
从源代码安装TensorFlow可能是一个主要的挑战。让GPU驱动程序和CUDA与上述任何库一起工作可能会更加困难。因此,预先安装所有的软件是避免大麻烦的一大解脱。
那么这些听起来很棒的硬件和软件能做什么呢?
让我们来具体了解一下。
XGBoost基准
XGBoost是一个开源库,它提供了梯度增强决策树的高性能实现。底层C++代码库与位于其上的Python接口相结合,使其超级快速且易于使用。它是数据科学家的首选库,尤其是在Kaggle竞赛中。
我们将运行一个基准测试,看看在使用XGBoost处理非常庞大的数据集时,计算机是如何执行的。我们将使用Rapids.ai的Demo notebook来运行测试。
Rapids是一套软件库,旨在利用GPU来加速数据科学计算。它使用底层的CUDA代码来实现快速、GPU优化的实现算法,同时在顶层仍然有一个易于使用的Python层。
Notebook用Numpy’s random.rand() function 生成了一个dataframe。为了真正突破限制,我将dataframe大小设置为5000列,1,000,000行,由32位小数组成。这是我在Notebook上能写的最大的内存了。如果你能更有效地读取数据,你可能能够挤进更多的内存。不过一旦运行开始,机器上的RAM使用似乎就确定了。
然后Notebook根据数据运行XGBoost模型的训练。
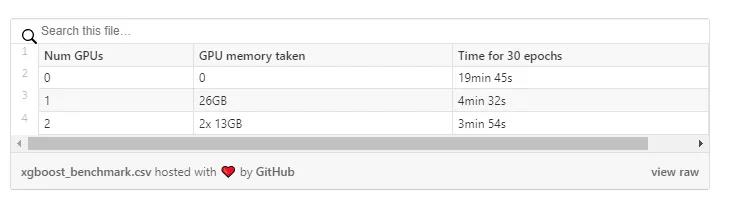
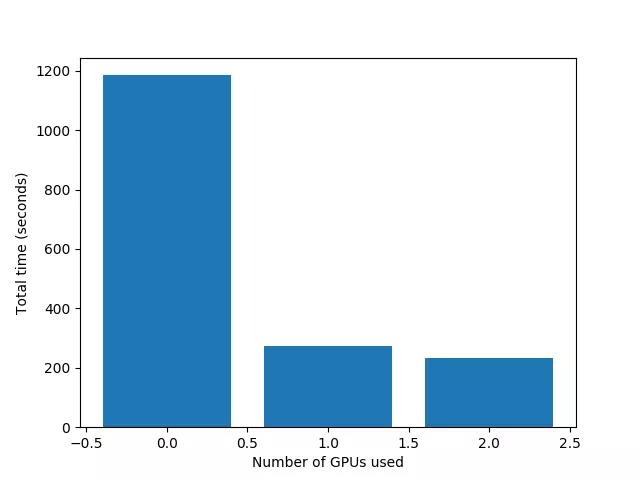
即使使用如此庞大的数据集,仅使用CPU,总共16个核/ 32个线程的2个Xeon处理器也能很好地处理它。
一旦开始运行,所有32个线程的使用率都将达到100%。不过,我们还有大量的RAM,如果我们愿意,还可以运行另一个较小的数据集。
一旦我们添加了GPU, XGBoost的速度在单GPU下无缝加速约4.5倍,在双GPU下无缝加速约5倍。
深度学习的基准
深度学习在数据科学中占据一席之地。在计算机视觉和自然语言处理领域,几乎所有的挑战都由最先进的深度网络所主导。
人们想要购买具有这种GPU能力的机器的一个重要原因是为了训练深度学习模型。
随着大的深度学习数据集的出现,你有越多GPU内存越好。那些几百层的深层网络需要大量的内存空间,特别是如果你想增加成批处理的规模来帮助加快训练速度。
高端消费级的GPU,如2080 Ti和1080 Ti,内存为11GB。它们是非常强大的,但是11GB通常不足以在内存中容纳一个大的神经网络。你可以使用更强大的东西,比如云计算上的V100 GPU,但每小时要花费3.06美元!
为了测试我们能从这些RTX 8000中得到多少,我们将使用TensorFlow的官方benchmark:tf_cnn_benchmark。存储库包含脚本,这些脚本在ImageNet分类数据集上运行标准图像分类模型的训练。训练进行一定次数的迭代,平均速度以图像/秒为单位测量。
为了真正测试计算机的能力,我们将使用各种不同批量大小和不同GPU的数量来运行基准测试。我在这个基准测试上训练一个ResNet152时得到的结果如下表所示。
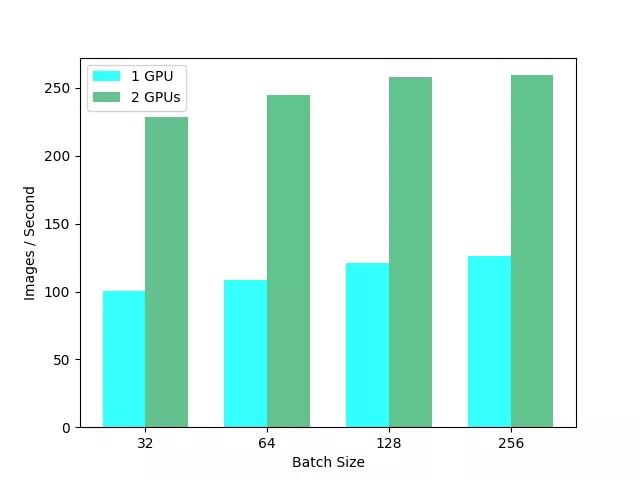
即使是单个RTX 8000也可以每秒处理100多张图像,对于ResNet152来说速度非常快。我们还有足够的空间来增加批量大小,从而进一步加快速度,达到256个。
由于我们能够充分利用我们的计算能力,更大的批处理大小已经被证明能够持续地减少训练时间。在一些需要大量内存的应用程序中,比如用于视频处理的3D CNNs,即使批量大小为1,也无法在标准的11GB GPU上使用!RTX 8000中的48GB提供了大量的喘息空间和足够的空间来处理批量大小和模型大小。
总结
总之,数据科学计算机是一台伟大的机器。对于它来说,真的很难不使用所有高质量的硬件。
最妙的是,一切都是“正常工作”。所有库和软件都被更新到最新版本并完全安装。令人惊讶的是,当你打开电脑电源,你会发现你可以不需要任何麻烦的运行TensorFlow代码,而这些代码通常需要安装源代码。这是一个巨大的时间和金钱的节省!
硬件选择是正确的。拥有这么多RAM和GPU内存带来的灵活性非常方便。没有因为运行许多的GPU而带来额外的工作或问题。获得越来越多的GPU也有递减的回报,因为你得到超过4卡。如果你喜欢不同的硬件设置,你可以订购机器时定制你的CPU, RAM和GPU选择,以满足你的需要。
获得一个内部计算机可能是一个相当大的前期投资-你一次购买了很多硬件。但是,在没有云空间成本的情况下,在本地工作的便利性,以及让所有东西都完美地设置起来的便利性,都超过了前期的价格。这是一个“正常工作”的数据科学计算机。
原文作者:George Seif
翻译作者:Holly Kong
美工编辑:Miya
校对审稿:冬冬





