
OpenAI刚刚证明了人类并没有为即将到来的事情做好准备
2016年,一个名为AlphaGo的人工智能终于向世界证明了人工智能可以超越我们的能力,击败了围棋比赛的人类冠军。
第一个超人类的AI。
那以后,人类又取得了一个里程碑式的成就,创造了第一个通用的人工智能模型,比如ChatGPT。
有趣的是,到2024年,我们可能会看到两个世界发生碰撞,第一个通用型超人类模型的出现。
然而,OpenAI最近的一篇论文认为,我们还没有准备好控制这些模型,这对人类构成了相当大的、甚至可能是灾难性的风险,以至于需要投入数十亿美元来解决这个问题。
幸运的是,他们也展示出了希望的迹象,这要归功于他们所谓的从弱到强的概括,并且他们提供了很多关于这是什么以及它如何潜在地拯救我们的见解。如果你想了解更多关于人工智能的相关内容,可以阅读以下这些文章:
2024年每个开发人员都需要掌握的生成式人工智能技能
Google的Gemini AI模型:揭开人工智能的未来
世界上最好的人工智能模型:谷歌DeepMind的Gemini已经超过了GPT-4!
我尝试了50种人工智能工具,以下是我的最爱
超对齐问题
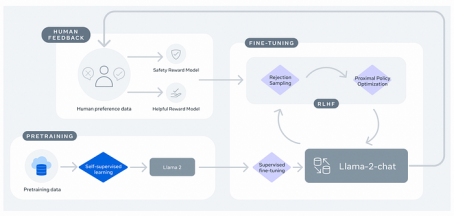
在创建像ChatGPT这样的自然语言模型助手时,对其进行对齐是至关重要的。
但是我们所说的对齐是什么意思呢?
引导的重要性
生成预训练转换器(GPT)是一种以无监督方式训练的自然语言模型,有时也称为自监督,其中转换器可以看到数万亿个单词,并从其词汇表中的所有单词中预测哪个单词似乎最适合继续文本序列。
然而,在这样的训练之后,模型(也称为基础模型)在预测序列的连续性方面非常出色,但无法遵循指令或进行简单对话。
因此,我们首先创建一个指令调优版本(通常称为SFT模型),通过给它提供一个经过策划的数据集,其中包含{用户问题:回答}的示例,以便模型不仅能够正确预测下一个单词,还能学习模仿理想的行为,如遵循指示。
这个过程中的这一步被OpenAI定义为“行为克隆”。
最后但并非最不重要的是,模型要经历最后一个训练阶段,即从人类反馈中强化学习(RLHF)阶段。
在这个阶段,我们训练模型以最大化有用性和安全性。用外行人的话来说,该模型不仅学会了有效地响应,而且在平衡有用性和安全性之间的权衡的同时,给出了可能的最佳响应。
但为什么要权衡呢?
如果只是最大化有用性,那么无论任务或问题如何,模型都倾向于始终有用。如果你需要它来帮你造炸弹,它会的。
因此,我们还包含了安全优化,这样模型就可以学会承认什么时候不应该帮助用户,从而以安全的名义“牺牲”效用。
整个过程支撑了ChatGPT这样的模型的成功,所以可以肯定地说它是有效的。然而,它也基于一个关键的假设:
我们人类有能力识别一个模型的反应是好是坏,从而引导它的行为。
这个假设今天仍然成立,因为GPT-4或Gemini Ultra,我们今天最强大的模型,绝不是超人类的,他们给我们的每一个反应都可以被衡量为积极或不积极。
但是,当我们创造出超人类的通用模型时,会发生什么呢?
到那一天,我们今天的主要对齐方法很有可能将不再有效。
最近,这个问题一直在引导OpenAI的大部分努力和工作。
当对齐变成超对齐
今年7月5日,OpenAI宣布成立一个“超对齐”团队,这是一个由他们最有才华的研究人员组成的团队,致力于解决超级对齐问题。
OpenAI很快就把钱花在了刀刃上,因为它还宣布其20%的计算能力将用于解决这个问题。
但什么是超对齐呢?
简单地说,就像我们今天调整我们的前沿模型一样,超对齐是指导未来超人类模型的行动。
如果你仔细想想,这是完全有道理的。
超人类模型是指远远超过人类能力的模型。在这种情况下,如果这样的模型能够生成代码,那么很有可能这些代码太复杂,人类无法理解。
在这种情况下,如果我们不能分辨出正确的反应和错误的反应,我们如何能够调整这些模型呢?
我来回答你:我们无法做到。
在这种情况下,我们变成了研究人员所定义的“弱监督者”,试图控制和引导一个客观上更优越的“存在”。
这个问题?
我们不能想当然地认为到时候我们会解决这个问题。
这不是一个选择,因为那就太晚了。换句话说,我们需要在创建超人类模型之前学习如何对齐它们。
否则,正如人工智能安全中心在2022年概述的那样,人类将面临“灾难性”风险。该中心由一些最著名的人工智能研究人员和思想家组成,如Yoshua Bengio或Geoffrey Hinton,谷歌Deepmind的联合创始人兼首席执行官Demis Hassabis,以及Elon Musk创建的的xAI公司Grok的联合创始人Igor Babushkin。
人类解决这个问题的第一步来自OpenAI,它以弱到强的泛化范式的形式出现。
但这是什么,为什么它会引起如此大的反应?
比老师优秀的学生
由于通用的超人类模型目前还不存在,我们没有办法使用它们来找出如何最好地调整它们。
因此,OpenAI建议使用一个类比:
我们能否将像GPT-4这样的模型与客观上较差的模型(如GPT-2)相结合?
在这种情况下,你猜对了,GPT-2正在扮演人类的角色,一个客观上处于劣势的人,试图告诉一个它甚至无法理解的超人类模型,如何表现。
在人类的引导下产生超人类的结果
提出的问题很清楚:
我们如何确保在引导具有弱监督信号的超人类模型的同时,仍能激发它们的超人类行为?
通俗地说,我们的目标是训练超人类模型按照预期行事,同时不强迫它像低等生物那样行事,从而使它变得愚蠢。
为了进一步理解这一点,让我们看看下面的例子:

在这种描述中,软弱的老师能够提供需要绘制的草图,从而调节模型以赋予绘画特定的结构(在这种情况下,迫使学生绘制蒙娜丽莎)。
自然地,由于强大的学生模型的能力远远超过教师,强大的模型比弱教师所能画的更详细和细致入微。
这是弱到强泛化的本质,能够引导更强大的模型(在这种情况下,通过“强迫”它沿着我们期望的结构绘制),同时不会在过程中使其变得愚蠢。
另一方面,如果强模型受到弱教师的影响太大,弱到强的泛化反过来会使强模型变笨,从而失去其超人类的能力。

但真正的问题是,从弱到强的泛化是否有效?
嗯,有点。
不伟大,也不可怕
获奖的《切尔诺贝利》系列中最精彩的台词之一发生在阿纳托利·迪亚特洛夫收到4号反应堆爆炸释放的辐射为3.6伦琴的通知时。
著名的是,他简单地说,“不伟大,也不可怕”,这恰好适用于OpenAI的结果。
长话短说,在评估了几个任务中从弱到强的泛化范式后,结论是,总的来说,它是有效的。
他们训练了三种模型:
- 弱监督器:这个模型是通过微调基于真实标签的小型预训练模型而创建的。弱监督器的性能被称为弱性能,弱标签是通过对一组样本进行弱模型的预测而生成的。
- 强学生模式:这种模式是在弱监督下训练的。它使用弱监督器生成的弱标签进行微调。该模型的最终性能被称为弱到强的性能,表明它在使用较弱的标签进行训练时的表现如何(这种情况类似于人类调整超人类模型)。
- 具有基础真值标签的强模型(强天花板性能):为了比较,也使用基础真值标签训练了一个强模型。该模型的最终性能被称为强天花板性能,它表示强模型在获得最准确和最可靠的信息时的全部能力。
考虑到这三个模型的结果,他们创建了一个衡量不同研究结果的尺度(PGR)。
- 如果PGR为0,这意味着对于特定任务,弱到强泛化使得强模型与弱监督器一样愚蠢,这意味着该任务的过程失败。
- 如果PGR为1,这意味着弱到强的泛化方法不仅对齐了模型,而且还能够激发强模型的全部能力,即在对齐过程中不会使模型变笨。
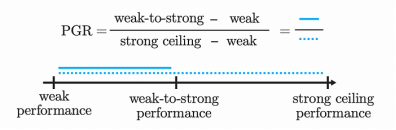
结果,你猜对了,不是很好,也不是很糟糕。
乐观但明确的结论
长话短说,在大多数情况下,比如国际象棋或NLP任务,从弱到强的泛化与强模型保持一致,同时仍然激发出远远优于主管所能产生的行为。
如下图所示,一些弱到强的模型(紫色),使用弱标签进行微调的模型,确实超过了弱监督器(哑模型,浅灰色)的能力,但它们仍然落后于没有弱标签的强模型(强模型处于最佳状态,因此,没有使用弱对应)。
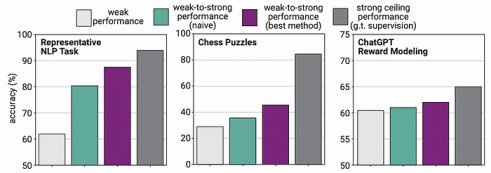
这意味着,虽然弱到强的泛化方法是有效的,从某种意义上说,它使模型保持一致,同时仍然保留了一些优越的能力,但有一个明显的权衡,因为强模型在被操纵的过程中失去了能力。
雪上加霜的是,在象棋谜题等情况下,该方法严重影响了强模型(中间图)的能力,而在构建ChatGPT奖励模型时,弱到强泛化的效果几乎不存在。
因此,我们可以得出结论,该方法显示了一些令人鼓舞的结果,但也清楚地表明,我们目前最好的对齐方法并不是对齐超人类模型的完全成熟的答案。
简而言之,人类还没有找到一种方法来确保PGR的结果是1(如果这种方法存在的话),或者非常明确地说,我们目前还没有准备好调整一个超人类模型。
因此,我们应该担心吗?
从1986年至今
与1986年4月的切尔诺贝利灾难相比,人类并没有创造一个超人类模型的特权,当试图引导它的行为时,得到一个“不伟大,也不可怕”的结果。
如果处理不当,超人类人工智能确实是一个令人担忧的问题。
另一方面,超人类人工智能有可能将我们的存在提升到新的高度:治愈不治之症,解决身体缺陷……甚至有可能消除人类对工作的需求!
但就像它能带来繁荣一样,它也能带来灾难性的后果。
具有超人类能力的不一致的模型打开了一个场景,人类不得不处理他们不理解的模型,这些模型远远超出了他们的能力,令人担忧的是,它们不一致,因此不可预测。
因此,研究实验室跟随OpenAI的努力,在这个问题成为问题之前优先解决它是非常重要的。
因为我们想生活在一个美好的未来,而不是一个我们的存在可以总结为“不伟大,也不可怕”的未来。
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Ignacio de Gregorio
翻译作者:过儿
美工编辑:过儿
校对审稿:Jason
原文链接:https://medium.com/@ignacio.de.gregorio.noblejas/openai-superhuman-models-2712639da9e6





