
只会Pandas?来学习这25种Pandas变SQL的方法,让你的数据分析更得心应手!
为什么要学习这些?
毫无疑问,SQL和Pandas都是数据科学家处理数据的强大工具。一般来说,SQL是一种用于管理和操作数据库中数据的语言,而Pandas是Python中的数据操作和分析库。如果你想了解更多关于SQL的相关内容,可以阅读以下这些文章:
使用SQL总结A/B实验结果
数据科学面试中你应该知道的10个高级SQL概念
SQL & NoSQL,掌握这7点就够了
SQL数据清理及准备 – 看这一篇就够了
此外,SQL通常用于从数据库中提取数据,在Python中进行分析(主要使用Pandas)。它的工具和功能齐全,能很好地处理表格数据,如数据操作、数据分析和可视化等。
将SQL和Pandas一起使用,我们就能清理、变换和分析大型数据集,创建复杂的数据管道和模型,这对作为数据科学家大有裨益,也因此,我们必须精通它们。在本文中,我将带你一步一步走,一起将最常见的Pandas操作变为SQL查询。
我们开始吧!
数据集
出于演示目的,我使用Faker创建了一个虚拟数据集:
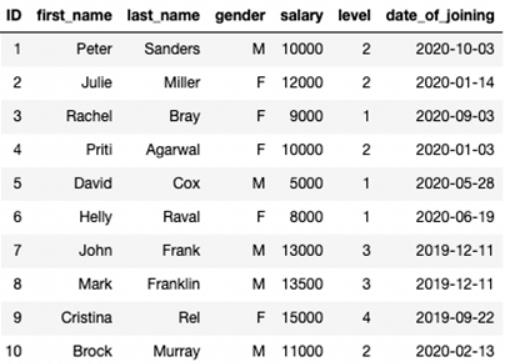
#1读取CSV文件
Pandas
CSV是最常用的用于读取Pandas数据帧的文件格式,我们需要用好Pandas中的pd.read_csv()。
file = "data.csv"
df = pd.read_csv(file)SQL
要想在数据库中创建表,我们首先要创建一个空表,定义其框架。
%%sql
drop table if exists employee;
CREATE TABLE employee
(
ID integer,
first_name varchar(20),
last_name varchar(20),
gender varchar(2),
salary integer,
level integer,
date_of_joining date
);然后,我们将CSV文件的内容(如果第一行是标题,则从第二行开始)转储到上面创建的表中。
%%sql
LOAD DATA INFILE 'data.csv'
INTO TABLE employee
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
IGNORE 1 ROWS;输出
完成此数据帧/表后,我们将获得以下输出:
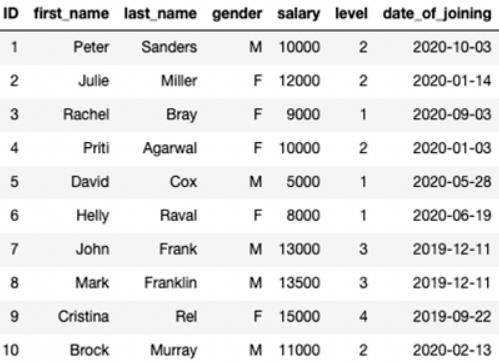
#2显示前X行
Pandas
我们可以在Pandas中使用df.head()。
df.head()
ID first_name last_name gender salary level date_of_joining
0 1 Peter Sanders M 10000 2 2020-10-03
1 2 Julie Miller F 12000 2 2020-01-14
2 3 Rachel Bray F 9000 1 2020-09-03
3 4 Priti Agarwal F 10000 2 2020-01-03
4 5 David Cox M 5000 1 2020-05-28SQL
在MySQL语法中,我们可以在select之后使用limit,并指定要显示的记录数。
%%sql
select * from employee limit 5;
* sqlite://
Done.
ID first_name last_name gender salary level date_of_joining
1 Peter Sanders M 10000 2 2020-03-10
2 Julie Miller F 12000 2 2020-01-14
3 Rachel Bray F 9000 1 2020-03-09
4 Priti Agarwal F 10000 2 2020-03-01
5 David Cox M 5000 1 2020-05-28#3输出尺寸
Pandas
根据表的shape属性输出行数和列数。
df.shape
(10, 7)SQL
我们可以使用“count”来输出行数。
%%sql
select count(1) from employee;
* sqlite://
Done.
count(1)
10#4输出数据类型
Pandas
在这里,我们可以使用dtypes参数输出所有列的数据类型:
df.dtypes
ID int64
first_name object
last_name object
gender object
salary int64
level int64
date_of_joining object
dtype: objectSQL
接着,我们可以按如下方式输出数据类型:
%%sql
DESCRIBE employee;#5修改列的数据类型
Pandas
在这里,我们可以使用如下的astype():
df.ID.astype(str)
0 1
1 2
2 3
3 4
4 5
5 6
6 7
7 8
8 9
9 10
Name: ID, dtype: objectSQL
使用ALTER COLUMN更改列的数据类型。
%%sql
ALTER TABLE employee
ALTER COLUMN ID varchar(5);以上操作将永久修改表中列的数据类型。如果你只希望在过滤时执行此操作,请使用cast。
%%sql
select cast(ID as string)
from employee
* sqlite://
Done.
cast(ID as string)
1
2
3
4
5
6
7
8
9
10#6–11过滤数据
在Pandas中有多种过滤数据帧的方法。
#6:你可以按如下方式过滤一列:
print(df[df.gender == "M"])
ID first_name last_name gender salary level date_of_joining
0 1 Peter Sanders M 10000 2 2020-10-03
4 5 David Cox M 5000 1 2020-05-28
6 7 John Frank M 13000 3 2019-12-11
7 8 Mark Franklin M 13500 3 2019-12-11
9 10 Brock Murray M 11000 2 2020-02-13可以将上述内容变换为SQL,如下所示:
%%sql
select *
from employee
where gender = "M";
* sqlite://
Done.
ID first_name last_name gender salary level date_of_joining
1 Peter Sanders M 10000 2 2020-03-10
5 David Cox M 5000 1 2020-05-28
7 John Frank M 13000 3 2019-11-12
8 Mark Franklin M 13500 3 2019-11-12
10 Brock Murray M 11000 2 2020-02-13#7:此外,你还可以在多个列上进行过滤:
print(df[(df.gender == "M") & (df.level == 2)])
ID first_name last_name gender salary level date_of_joining
0 1 Peter Sanders M 10000 2 2020-10-03
9 10 Brock Murray M 11000 2 2020-02-13同样地,我们变换为SQL:
%%sql
select *
from employee
where gender = "M" and level = 2;
* sqlite://
Done.
ID first_name last_name gender salary level date_of_joining
1 Peter Sanders M 10000 2 2020-03-10
10 Brock Murray M 11000 2 2020-02-13#8:你还可以使用isin()从值列表中筛选:
print(df[df.level.isin([3,4])])
ID first_name last_name gender salary level date_of_joining
6 7 John Frank M 13000 3 2019-12-11
7 8 Mark Franklin M 13500 3 2019-12-11
8 9 Cristina Rel F 15000 4 2019-09-22为了模拟上述情况,我们在SQL中使用了“in”:
%%sql
select *
from employee
where level in (3,4);
* sqlite://
Done.
ID first_name last_name gender salary level date_of_joining
7 John Frank M 13000 3 2019-11-12
8 Mark Franklin M 13500 3 2019-11-12
9 Cristina Rel F 15000 4 2019-09-22#9:在Pandas中,你还可以使用点运算符选择特定的列。
df.first_name.head(3)
0 Peter
1 Julie
2 Rachel
Name: first_name, dtype: object在SQL中,我们可以在select之后指定所需的列。
%%sql
select first_name
from employee
limit 3;
* sqlite://
Done.
first_name
Peter
Julie
Rachel#10:如果要在Pandas中选择多个列,可以执行以下操作:
df[["first_name", "date_of_joining"]].head(3)
first_name date_of_joining
0 Peter 2020-10-03
1 Julie 2020-01-14
2 Rachel 2020-09-03在SQL中的select之后选择多个列,也同样如此:
%%sql
select first_name, date_of_joining
from employee
limit 3;
* sqlite://
Done.
first_name date_of_joining
Peter 2020-03-10
Julie 2020-01-14
Rachel 2020-03-09#11你还可以根据Pandas中的NaN值进行过滤
df[df.first_name.isna()]
Empty DataFrame
Columns: [ID, first_name, last_name, gender, salary, level, date_of_joining]
Index: []我们没有NaN值,因此看不到行。
如果是SQL,如下所示:
%%sql
select *
from employee
where first_name is NULL;
* sqlite://
Done.
ID first_name last_name gender salary level date_of_joining#12我们还可以尝试一些复杂的字符串过滤
df[df.first_name.str.startswith("J")]
ID first_name last_name gender salary level date_of_joining
1 2 Julie Miller F 12000 2 2020-01-14
6 7 John Frank M 13000 3 2019-12-11在SQL中,我们可以使用LIKE语句。
%%sql
select *
from employee
where first_name LIKE "J%";
* sqlite://
Done.
ID first_name last_name gender Employee_Salary level date_of_joining full_name
2 Julie Miller F 12000 2 2020-01-14 Julie Miller
7 John Frank M 13000 3 2019-11-12 John Frank#13你还可以搜索其中的子字符串。假设现在我们要查找“last_name”包含子字符串“an”的所有记录
在Pandas中,我们可以执行以下操作:
print(df[df.last_name.str.contains("an")])
ID first_name last_name gender salary level date_of_joining
0 1 Peter Sanders M 10000 2 2020-10-03
6 7 John Frank M 13000 3 2019-12-11
7 8 Mark Franklin M 13500 3 2019-12-11在SQL中,我们可以再次使用LIKE语句。
%%sql
select *
from employee
where last_name LIKE "%an%";
* sqlite://
Done.
last_name gender Employee_Salary level date_of_joining full_name
1 Peter Sanders M 10000 2 2020-03-10 Peter Sanders
7 John Frank M 13000 3 2019-11-12 John Frank
8 Mark Franklin M 13500 3 2019-11-12 Mark Franklin#14–16排序数据
排序是数据科学家用来对数据分等级的另一个操作。
Pandas
使用df.sort_values()对数据帧进行排序。
df.sort_values("salary")
ID first_name last_name gender salary level date_of_joining
4 5 David Cox M 5000 1 2020-05-28
5 6 Helly Raval F 8000 1 2020-06-19
2 3 Rachel Bray F 9000 1 2020-09-03
0 1 Peter Sanders M 10000 2 2020-10-03
3 4 Priti Agarwal F 10000 2 2020-01-03
9 10 Brock Murray M 11000 2 2020-02-13
1 2 Julie Miller F 12000 2 2020-01-14
6 7 John Frank M 13000 3 2019-12-11
7 8 Mark Franklin M 13500 3 2019-12-11
8 9 Cristina Rel F 15000 4 2019-09-22你还可以对多个列进行排序:
print(df.sort_values(["salary", "level"]))
ID first_name last_name gender salary level date_of_joining
4 5 David Cox M 5000 1 2020-05-28
5 6 Helly Raval F 8000 1 2020-06-19
2 3 Rachel Bray F 9000 1 2020-09-03
0 1 Peter Sanders M 10000 2 2020-10-03
3 4 Priti Agarwal F 10000 2 2020-01-03
9 10 Brock Murray M 11000 2 2020-02-13
1 2 Julie Miller F 12000 2 2020-01-14
6 7 John Frank M 13000 3 2019-12-11
7 8 Mark Franklin M 13500 3 2019-12-11
8 9 Cristina Rel F 15000 4 2019-09-22最后,我们还可以使用ascending(升序)参数为不同的列指定不同的条件(升序/降序)。
df.sort_values(["last_name", "level"], ascending=[False, True])
ID first_name last_name gender salary level date_of_joining
0 1 Peter Sanders M 10000 2 2020-10-03
8 9 Cristina Rel F 15000 4 2019-09-22
5 6 Helly Raval F 8000 1 2020-06-19
9 10 Brock Murray M 11000 2 2020-02-13
1 2 Julie Miller F 12000 2 2020-01-14
7 8 Mark Franklin M 13500 3 2019-12-11
6 7 John Frank M 13000 3 2019-12-11
4 5 David Cox M 5000 1 2020-05-28
2 3 Rachel Bray F 9000 1 2020-09-03
3 4 Priti Agarwal F 10000 2 2020-01-03这里,对应ascending的列表指示last_name按降序排序,而level按升序排序。
SQL
在SQL中,我们可以使用order by字句来执行此操作。
%%sql
select *
from employee
order by salary;
* sqlite://
Done.
ID first_name last_name gender salary level date_of_joining
5 David Cox M 5000 1 2020-05-28
6 Helly Raval F 8000 1 2020-06-19
3 Rachel Bray F 9000 1 2020-03-09
1 Peter Sanders M 10000 2 2020-03-10
4 Priti Agarwal F 10000 2 2020-03-01
10 Brock Murray M 11000 2 2020-02-13
2 Julie Miller F 12000 2 2020-01-14
7 John Frank M 13000 3 2019-11-12
8 Mark Franklin M 13500 3 2019-11-12
9 Cristina Rel F 15000 4 2019-09-22此外,通过在order by字句中指定更多列,我们可以容纳更多有排序条件的列:
%%sql
select *
from employee
order by salary, level;
* sqlite://
Done.
ID first_name last_name gender salary level date_of_joining
5 David Cox M 5000 1 2020-05-28
6 Helly Raval F 8000 1 2020-06-19
3 Rachel Bray F 9000 1 2020-03-09
1 Peter Sanders M 10000 2 2020-03-10
4 Priti Agarwal F 10000 2 2020-03-01
10 Brock Murray M 11000 2 2020-02-13
2 Julie Miller F 12000 2 2020-01-14
7 John Frank M 13000 3 2019-11-12
8 Mark Franklin M 13500 3 2019-11-12
9 Cristina Rel F 15000 4 2019-09-22我们可以为不同的列指定不同的排序顺序,如下所示:
%%sql
select *
from employee
order by last_name desc, level asc;
* sqlite://
Done.
ID first_name last_name gender salary level date_of_joining
1 Peter Sanders M 10000 2 2020-03-10
9 Cristina Rel F 15000 4 2019-09-22
6 Helly Raval F 8000 1 2020-06-19
10 Brock Murray M 11000 2 2020-02-13
2 Julie Miller F 12000 2 2020-01-14
8 Mark Franklin M 13500 3 2019-11-12
7 John Frank M 13000 3 2019-11-12
5 David Cox M 5000 1 2020-05-28
3 Rachel Bray F 9000 1 2020-03-09
4 Priti Agarwal F 10000 2 2020-03-01#17填充NaN值
在此,我删除了“薪水”列中的几个值。这是更新后的数据帧:
print(df.head())
ID first_name last_name gender salary level date_of_joining
0 1 Peter Sanders M NaN 2 2020-10-03
1 2 Julie Miller F NaN 2 2020-01-14
2 3 Rachel Bray F 9000.0 1 2020-09-03
3 4 Priti Agarwal F 10000.0 2 2020-01-03
4 5 David Cox M 5000.0 1 2020-05-28Pandas
在Pandas中,我们可以使用fillna()来填充NaN值:
df.salary.fillna(10000).head()
0 10000.0
1 10000.0
2 9000.0
3 10000.0
4 5000.0
Name: salary, dtype: float64SQL
在SQL中,我们可以使用选择语句。
%%sql
select
case when
salary is NULL then 10000 else salary end as salary
from employee
limit 5;
* sqlite://
Done.
salary
10000
10000
9000
10000
5000#18–19连接数据
Pandas
如果要合并两个数据帧,可以使用pd.merge():
df1 = ...
df2 = ...
print(df1)
print(df2)
col1 col2 col3
0 1 2 A
1 3 4 B
2 5 6 C
col3 col4
0 A X
1 B Ypd.merge(df1, df2, on = "col3")
col1 col2 col3 col4
0 1 2 A X
1 3 4 B YSQL
%%sql
select * from
table1 join table2
on (table1.col3 = table2.col3);
* sqlite://
Done.
col1 col2 col3 col3_1 col4
1 2 A A X
3 4 B B Y另一种方法是连接它们。
Pandas
看下面的数据帧:
df1 = ...
print(df1)
col1 col2 col3
0 1 2 A
1 3 4 B
2 5 6 C在Pandas中,你可以使用concat(),将其传给另一个数据帧,将其连接为列表/元组。
pd.concat((df1, df1))
col1 col2 col3
0 1 2 A
1 3 4 B
2 5 6 C
0 1 2 A
1 3 4 B
2 5 6 CSQL
使用SQL中的UNION(只保留特定行)和UNION ALL(保留所有行)也同样能做到。
%%sql
select * from table1
union all
select * from table1;
* sqlite://
Done.
col1 col2 col3
1 2 A
3 4 B
5 6 C
1 2 A
3 4 B
5 6 C#20分组数据
Pandas
要对数据帧进行分组并聚合,可以使用Pandas中的groupby(),如下所示:
df.groupby("level").salary.mean()
level
1 7333.333333
2 10750.000000
3 13250.000000
4 15000.000000
Name: salary, dtype: float64SQL
在SQL中,可以使用GROUP BY字句在SELECT字句中指定聚合。
%%sql
select level, avg(salary)
from employee
group by level;
* sqlite://
Done.
level avg(salary)
1 7333.333333333333
2 10750.0
3 13250.0
4 15000.0结果都一样!
#21–22输出特定值
Pandas
要输出列中不同的值,使用unique()
df.level.unique()
array([2, 1, 3, 4])要输出不同值的数量,使用nunique()。
df.level.nunique()
4SQL
在SQL中,我们可以在select中使用DISTINCT,如下所示:
%%sql
select distinct level
from employee;
* sqlite://
Done.
level
2
1
3
4要计算SQL中不同值的数量,我们可以将COUNT aggregator装给distinct。
%%sql
select count(distinct level)
from employee;
* sqlite://
Done.
count(distinct level)
4#23重命名列
Pandas
我们可以使用df.rename(),如下所示:
df.rename(columns = {"salary":"Employee_Salary"}).head()
ID first_name last_name gender Employee_Salary level date_of_joining
0 1 Peter Sanders M 10000 2 2020-10-03
1 2 Julie Miller F 12000 2 2020-01-14
2 3 Rachel Bray F 9000 1 2020-09-03
3 4 Priti Agarwal F 10000 2 2020-01-03
4 5 David Cox M 5000 1 2020-05-28SQL
我们可以使用ALTER TABLE来重命名列:
%%sql
ALTER TABLE employee
RENAME COLUMN salary to Employee_Salary;
* sqlite://
Done.
1#24删除列
Pandas
使用df.drop():
df.drop(columns = ["last_name"]).head()
ID first_name gender salary level date_of_joining
0 1 Peter M 10000 2 2020-10-03
1 2 Julie F 12000 2 2020-01-14
2 3 Rachel F 9000 1 2020-09-03
3 4 Priti F 10000 2 2020-01-03
4 5 David M 5000 1 2020-05-28SQL
与重命名类似,我们可以使用ALTER TABLE和RENAME来删除。
%%sql
ALTER TABLE employee
DROP COLUMN last_name;#25创建新列
假设我们要创建一个新的列“full_name”,它是列first_name和last_name的连接,中间有一个空格。
Pandas
我们可以在Pandas中进行一个简单的赋值运算。
df["full_name"] = df["first_name"] + " " + df["last_name"]
ID first_name last_name gender salary level date_of_joining full_name
0 1 Peter Sanders M 10000 2 2020-10-03 Peter Sanders
1 2 Julie Miller F 12000 2 2020-01-14 Julie Miller
2 3 Rachel Bray F 9000 1 2020-09-03 Rachel Bray
3 4 Priti Agarwal F 10000 2 2020-01-03 Priti Agarwal
4 5 David Cox M 5000 1 2020-05-28 David CoxSQL
在SQL中,我们首先需要添加新列:
%%sql
ALTER TABLE employee
ADD full_name varchar(40);
* sqlite://
Done.
[]接下来,我们使用SQL中的SET来设置该值。
%%sql
UPDATE employee
SET full_name = first_name || " " || last_name;
* sqlite://
10 rows affected.
[]“||”在SQLite中用作连接运算符。点此链接深入了解:https://www.sqlitetutorial.net/sqlite-string-functions/sqlite-concat/
结语
祝贺你!你现在已经了解了Pandas中最常见的SQL变换方法。
我已经努力做到面面俱到了,不过,我应该还是没能罗列齐全。
请批评指正!
一如既往,感谢你的阅读!

你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Avi Chawla
翻译作者:高佑兮
美工编辑:过儿
校对审稿:Chuang
原文链接:https://towardsdatascience.com/pandas-isnt-enough-learn-these-25-pandas-to-sql-translations-to-upgrade-your-data-analysis-game-af8d0c26948d





