
Python数据处理:关于Pandas你需要知道的都在这里
然而,pandas简捷的数据结构并不是那么容易上手。正因为pandas数据结构比较简洁,所以许多常用的功能放置只能被在其他的函数当中。将这些极其常用的功能和数据本身进行了分离,这就是pandas刚开始不那么容易上手的原因。对新手来说,需要找到一个好的学习的切入点。现在市面上有许多pandas学习资料,涵盖了方方面面。但建议初学者打印一份pandas操作指南(或者叫它小抄)以备不时之需。
温馨提示:带好小抄再上路!
A Visual Guide To Pandas: https://www.youtube.com/watch?v=9d5-Ti6onew

注意,你可以把任意一种数据放入Series中,可以是整数、字符串等等。
使用pd.DataFrames( )可以创建DataFrames,它至少包括两列包含不同数据的Series。括号中你可以放字典进去,然后加上一些数字索引来明确地指出列的元素。

pandas甚至有专门对应SQL数据库查询(query)文件的导入函数:pd.read_sql_query( )。to_sql( )函数可以同时应对SQL表格和搜索文件,但是它其实只是上面提到的后两种函数的结合。使用to_sql( )函数时系统会自动探测文件类型,调用正确的函数。
当从python中输出文件的时候,可以使用pd.to_csv( ), pd.to_excel()和 pd.to_sql()。
![]()

选择DataFrames里面的元素的第二种方法是使用iloc( )和iat( )。
第三种方法,则是通过行和列的名字(标签)进行选择。
再比如说你在之前章节已经看见每个列都有一个标签:“Country”、 “Capital”和“Population”。你可以通过把标签输入到这两个函数中:loc()和at(),选择你想要的元素。这是第四个方法。
第五种方法,则是输入标签到ix()函数中得到相应的元素,但如果DataFrames没有标签,ix函数也可以利用列的位置来进行选择。
操作指南中中还介绍了布尔索引,布尔索引能够帮助你选择DataFrames里面满足一定条件的元素。这些条件可以包括等于、不等、大于、小于和它们的和、或的并用。
最后,还可以改变一个Series的索引元素,比如说一个索引值可以从3改为6。


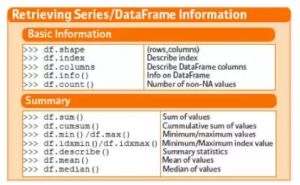
上图左栏列出了一些得到数据结构特征的函数,还有一些常见的总结性指标,比如你肯定已经很熟悉的求和、平均、中位数等。


这种事情经常发生。而pandas的默认设置是将那些两个表不共享的索引值的位置上填满NA(无值)。如果你想避免这种情况,可以设置fill_value参数,设置的值将取代原来的NA。
现在你已经非常懂得pandas的基本操作了。
原文:Pandas Cheat Sheet for Data Science in Python
作者:Karlijn Willems
链接:https://goo.gl/wmnpSy




