
Pandas的秘密:5个鲜为人知的功能,将彻底改变你的数据分析技能
从新手到专业人士:用这5个神秘的Pandas功能来提升你的数据分析技能。如果你想了解更多关于求职的相关内容,可以阅读以下这些文章:
如何从数据分析师过渡到数据科学家的角色?
什么是ChatGPT?作为一名数据分析师,你如何才能更好地利用它?
帮我得到第一份数据分析师工作的9个SQL核心概念
只会Pandas?来学习这25种Pandas变SQL的方法,让你的数据分析更得心应手!
Pandas是一个功能强大的Python库,用于数据操作和分析。数据科学家和分析师一直在使用它来清洗、更改和分析数据。虽然许多人都熟悉Pandas的基本功能,但还有一些不太为人所知的功能可以帮助你更高效地处理数据。在这篇文章中,我们将探索关于Pandas的五个鲜为人知的秘密。
1 数据透视表功能
Pandas中的数据透视表功能是一个汇总和聚合数据的强大工具。它允许你按一列或多列对数据进行分组,并对分组后的数据应用聚合函数。下面是一个如何使用pivot_table函数的例子:
import pandas as pd
# load the Titanic dataset from GitHub
url = 'https://raw.githubusercontent.com/pandas-dev/pandas/master/doc/data/titanic.csv'
df = pd.read_csv(url)
# create a pivot table that shows the total fares paid by passengers in each passenger class
# who either survived or did not survive
pivot = pd.pivot_table(df, index='Pclass', columns='Survived', values='Fare', aggfunc='sum')
# display the resulting pivot table
pivot输出:
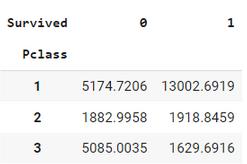
在本例中,我们使用Pandas中的pivot_table函数来按pclass和survivor列对票价进行分组。Pclass被显示为一个索引,并在结果DataFrame的列中保留为0和1。
2 重塑数据
重塑数据是数据分析中常见的任务。Pandas提供了几个用于重塑数据的函数,比如melt和stack。这些函数允许你将数据从宽格式转换为长格式,反之亦然。下面是一个如何使用melt 函数的例子:
import pandas as pd
# load the iris dataset from GitHub
url = 'https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/iris.csv'
df = pd.read_csv(url)
# reshape the data using the melt method to create a long format dataset
melted = pd.melt(df, id_vars=['species'], var_name='measurement', value_name='value')
# display the resulting melted dataset
melted输出:
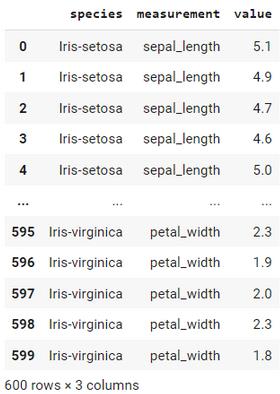
在本例中,我们使用melt函数将irisdata从宽格式转换为长格式。
3 自定义聚合函数
Pandas提供了广泛的内置聚合函数,比如sum、mean和count。但是,你可能会遇到需要对数据应用自定义聚合函数的情况。Pandas允许你使用aggmethod定义和应用自定义聚合函数。下面是如何定义和应用自定义聚合函数的示例:
# import pandas library
import pandas as pd
# Creating DataFrame
df = pd.DataFrame(
{'stud_id' : [101, 102, 103, 104,
101, 102, 103, 104],
'sub_code' : ['CSE6001', 'CSE6001', 'CSE6001',
'CSE6001', 'CSE6002', 'CSE6002',
'CSE6002', 'CSE6002'],
'marks' : [77, 86, 55, 90,
65, 90, 80, 67]}
)
# Displaying DataFrame
df输出:
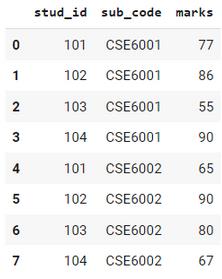
现在,如果你需要计算每个学生的总分数(两个科目的分数)(唯一的stu_id)。这个过程可以使用自定义的聚合函数来完成。这里我的自定义聚合函数是total。
# Importing reduce for
# rolling computations
from functools import reduce
# define a Custom aggregation
# function for finding total
def total(series):
return reduce(lambda x, y: x + y, series)
# Grouping the output according to
# student id and printing the corresponding
# total marks and to check whether the
# output is correct or not, sum function
# is also used to print the sum.
df.groupby('stud_id').agg({'marks': ['sum', total]})输出:
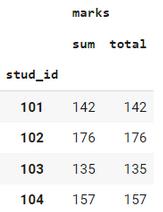
从这里复制的例子。信用:geekforgeeks
4 DateTime功能
Pandas提供了许多用于处理日期和时间数据的函数。这些函数允许你从datetime对象中提取信息,例如星期几或一天中的某一小时。下面是一个如何从datetime对象中提取星期几的例子:
import pandas as pd
# load the female births dataset from GitHub
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/daily-total-female-births.csv'
df = pd.read_csv(url)
# convert the Date column to datetime format
df['Date'] = pd.to_datetime(df['Date'])
# add a new column 'DayOfWeek' to the DataFrame and populate it with the day name
df['DayOfWeek'] = df['Date'].dt.day_name()
# display the resulting DataFrame
df输出:
在这个例子中,我们使用pd.read_csv()将GitHub上一个每日女婴出生数据集加载到一个DataFrame中。然后,我们使用pd.to_datetime()将dateccolumn转换为datetime格式。最后,我们添加了一个新的列dayofweek到DataFrame中,它包含了对应于datecolame中每个日期的日期名,使用了dt.day_name()方法,并打印生成了结果DataFrame.
5 内存优化
在处理大型数据集时,内存使用可能是一个问题。Pandas提供了几个优化内存使用的函数,比如astype方法和to_numeric函数。这些函数允许你将数据转换为更节省内存的数据类型。下面是一个关于如何使用astype方法的例子:
import pandas as pd
# load the sales dataset from GitHub
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/daily-total-female-births.csv'
df = pd.read_csv(url)
# convert the 'Births' column to int32 data type from int64
df['Births'] = df['Births'].astype('int32')
# check new dtypes
df.dtypes输出:

在这个例子中,我们使用pd.read_csv()将GitHub上的每日女婴出生数据集加载到一个DataFrame中。然后,我们使用astype()方法将Birthscolumn的数据类型转换为int32。当处理需要考虑内存效率的大型数据集时,这非常有用。
感谢阅读。你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Moez Ali
翻译作者:马薏菲
美工编辑:过儿
校对审稿:Chuang
原文链接:https://moez-62905.medium.com/secrets-of-pandas-5-little-known-features-that-will-revolutionize-your-data-analysis-c7d4c92a6fd0





