.jpg "如何做社交媒体中的情绪分析(Sentiment Analysis)")
如何做社交媒体中的情绪分析(Sentiment Analysis)
什么是情绪分析(Sentiment Analysis)?
情绪分析能帮我们理解文本数据的语调,包括正面、负面或中立的语气。捕捉文中的情绪可以帮助公司更好地了解用户的心声 (VOC),甚至可以引导产品开发,从而改进功能。情绪分析通常基于词汇和规则,这意味着该情绪可以标记为正面、负面或中立的单词。有很多用于情趣分析的先进机型,比如2018年谷歌公开了BERT模型。
本文将介绍更传统的基于词汇的方法;稍后我们将探讨深度学习模型。如果你想了解更多数据分析相关内容,可以阅读以下这些文章:
数据分析的Regression算法到底是什么?
数据分析新工具MindsDB–用SQL预测用户流失
DS数据科学家和DA数据分析师:要学习什么不同内容?
数据分析师需要知道的10个Excel函数

你需要熟悉新术语,才能解释你得到结果。这些概念都非常简单,但提前了解可以帮助你后续操作。
- 极性(Polarity):表示句子情绪程度从负面到正面的值。是处于 [-1.0, 1.0] 范围内的值(负面情绪-> -1.0,中立-> 0.0,正面情绪-> 1.0)
- 主观性(Subjectivity):主观句表达个人的感受、观点或信念。主观性是在 [0.0, 1.0] 范围内的值,其中 0.0 为非常客观的,而 1.0 是非常主观的。
Twitter数据
在本文的案例中,我们将利用从 Twitter 中提取的数据。Twitter 是 VOC 分析的绝佳来源。你可以搜索产品名称、话题标签、提及或公司名称。对于 Python,我们可以使用 Twitter API 的 Tweepy 包装器。
在寻找非常正面或高度负面的数据例子时,我刚好看到了关于吉兰·麦克斯韦尔(Ghislaine Maxwell)的审判判决结果的文章,与它相关的文字都是高度负面的。我选择了泰勒斯威夫特(Taylor Swift)相关的推特,都是高度正面的。
我们首先导入要使用的库,然后再导入数据。
import pandas as pd
from textblob import TextBlob
from vadersentiment.vadersentiment import sentimentIntensityAnalyzer
import seaborn as sns
import matplotlib.pyplot as plt
swift = pd.read pickle ( ' swift.pkl')
maxwell = pd.read_pickle ( 'maxwell.pkl')使用 TexBlob 进行情绪分析
TexBlob 是我喜欢用于快速建立 NLP 项目的包。TexBlob是一个简单的 Python API,支持情绪分析等常见任务,它包含两个不同的情绪分析器。第一个叫做 PatternAnalyzer,另一个是 NLTKs NaiveBayesAnalyzer,后者是根据电影评论语料库上训练的分析器。
从 TextBlob 获取极性(或主观性)分数很简单。我们可以使用 Panda 的 apply 函数来获取每条推文的情绪极性。
# Apply the Polarity scoring fromTextBlob
swift ['blob']=swift['text'].apply(lambda x:TextBlob(x).sentiment.polarity)
swift.head()
TVEET POLARITY
0 RT @TswiftFTC:According to @HITSDD,Taylor ... 1.000000
1 RT @taylorr_media: Taylor swift - All Too well... 0.00000
2 Taylor Swift and Ed sheeran musicmainly. And ... 0.166667
3 RT @soitgoes: Taylor Swift didn'twrite: . ..0.200000
4 suporte list: Nial Horan, Demi Lovato,Taylor ... 0.00000
操作非常简单,我们获得了极性分数。从上述示例中,我们可以看到,值的范围从中立到最大正值 1.0。很多时候,文章必须保持中立。因为中立推文不会为分析添加任何信息,我们可以删除这些信息,只留下那些正面和负面情绪。
#Get rid of neutral sentiment
filter = swift['blob'] != 0
swift = swift[filter]接下来,我们来绘制结果。我用的是 Seaborn 的 histplot。直方图非常适合可视化极性分数,因为这类图标可以很好地归类至-1.0到1.0的范围内。
sns.histplot (swift,x='blob',color="#7C8c58",bins=10)
plt.title("Taylor swift sentimentDistribution with TextBlob")
plt.xlabel("sentiment")
plt.ylabel("")下面,你可以看到 Taylor的推文大多是正面的,而Maxwell 的推文大多是负面的。
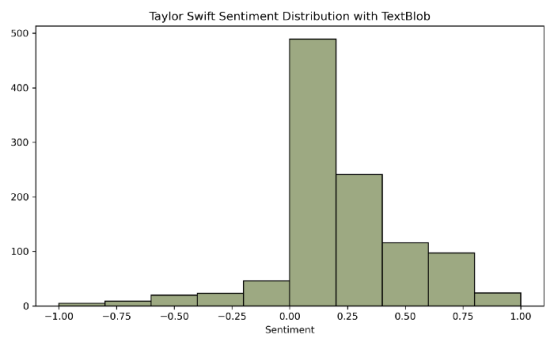
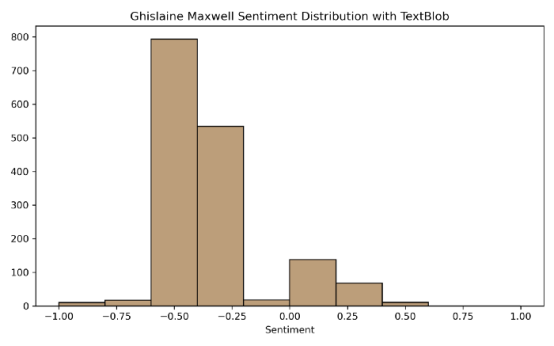
利用 Vader 进行社交媒体情绪分析
TextBlob 并不适合用于较短的文本或社交媒体帖子,它更适合用于较长且更干净的字符串。然而,有一些工具非常适合社交媒体,这些工具了解如何处理社交媒体中使用的语言模式。这些工具之一是 VADER(Valence Aware Dictionary and Sentiment Reasoner)库。VADER 专门为社交媒体处理以下内容:
- 助词:能增加情绪的词,如好棒或爱
- 全部大写:全部大写的单词通常用于放大情绪
- 标点符号:如!或者 !!!可以增加情绪
- 俚语:正确解释 SUX 或 BFF 等词
- 表情符号:正确处理 UTF-8 编码的表情符号
注意:在这里,不能用常用的 NLP 方法清理字符串。VADER 会从未处理的文本中删除很多上下文。
在进入 Twitter 数据之前,我们来看看如何处理几个只包含表情符号的字符串。

使用 TextBlob 时,这两个字符串讲返回 0.0,而使用 VADER 时,它返回的分数看起来
与表情符号所代表的情绪一致。
我们再次执行上述相同操作,但这次是用 VADER 库。我们将在数据帧上使用相同的 apply 方法。
# Add the polarity scores
swift['vader']=
swift['text'].apply(lambda x:sid.polarity_scores(x))
{'neg':0.0,'neu':0.793,'pos':0.207,'compound':0.7184}结果列是不同键值对(key-value pairs)的字典。代表 TextBlob 情绪的键值称为复合键值。我们可以用下面的函数来提取数据帧:
#Extract only the compound score valueswift['compound']=
swift['vader'].apply(lambda score_dict:score_dict['compound'])再次绘制结果,我们可以看到,VADER 更好地代表了情绪。Taylor的得分更偏向正面,而 Maxwell 的得分更偏向于负面。VADER 在推文中捕捉到的情绪比 TextBlob 更多,无论是表情符号还是人们强调自己感受的其他常见方式。
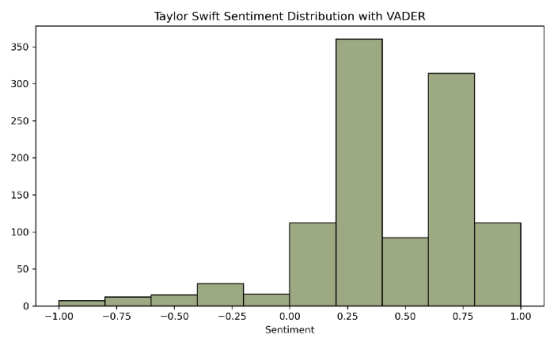
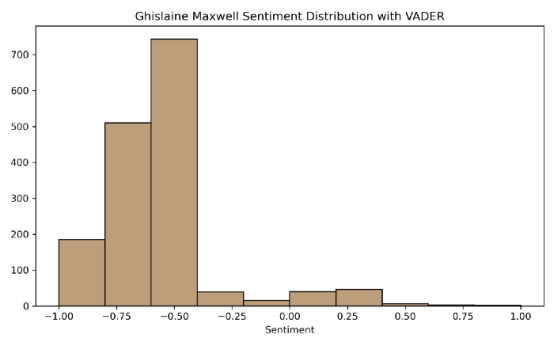
结论
本文到此也就结束了!我们主要讲述通过社交媒体数据的情绪分析获取用户的心声。本文帮助你了解可以做什么以及如何利用这些信息;同时也提供了一个非常有用的工具,帮助你更好地了解用户及其情绪。你会如何运用情感分析?欢迎在文章下方留言!你还可以订阅我们的YouTube频道,观看大量数据科学相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Brain Roepke
翻译作者:Lia
美工编辑:过儿
校对审稿:Jiawei Tong
原文链接:https://towardsdatascience.com/sentiment-analysis-74624b075842





