
数据分析的Regression算法到底是什么?
今天,我们来讲回归分析(Regression Analysis),首先,让我们先想一下Regression这个词代表的是什么意思。这里,我们可以通过两种方式去理解,一种是从机器学习方面理解,Regression可以看做分类(Classification)。分类的时候,Response variable(也可以理解为label或者y)需要是一个非连续的分布,最简单的就是0和1的dispersion。
而对于regression来讲,y应该是一个连续的值,但是从统计来讲,regression有另外一种定义,这又是跟所有的linear regression和linear transfer regression相关。如果你想了解更多数据分析相关内容,可以阅读以下这些文章:
数据分析新工具MindsDB–用SQL预测用户流失
DS数据科学家和DA数据分析师:要学习什么不同内容?
数据分析师需要知道的10个Excel函数
数据分析如何在Fintech中发挥作用?
线性回归(linear regression)

什么是线性回归(linear regression)?一般来说就是在图中公式中所展示的形式。一般会有一个常数项,会有一个x和一个y,x是predictor variable,它是我们用来预测的一个变量,而y是response variable,是需要预测的变量。B0是常数项,如果在图像里,他会是一个截距,而B1会是x的系数,如果在图像里表示,它会是斜率,最后一个是随机变量,我们无法去控制,可以去推断,但对于每一个具体的值它会是随机的,这个就是基本的线性回归(linear regression)的形式。
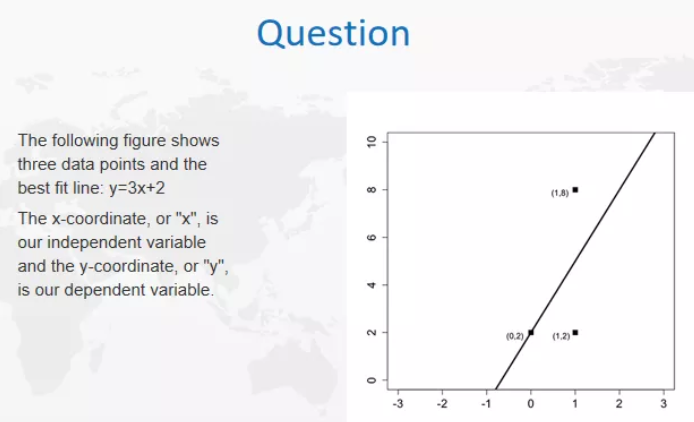
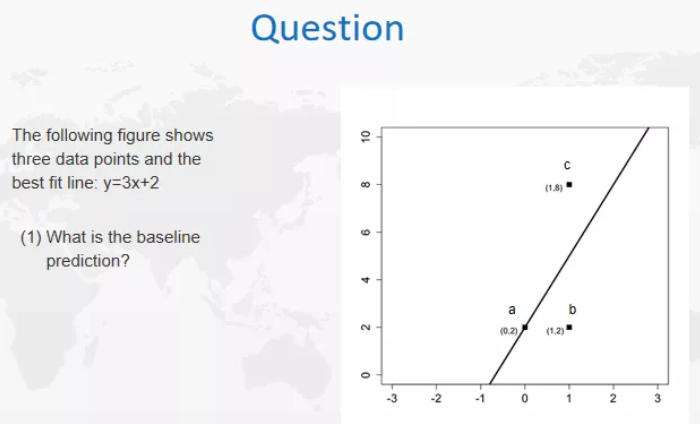
上图是我们一般做回归的一个常见情况,如果有三个值,就会有一个最佳拟合线,但是我们可以想一下,这条线的基线预测(baseline prediction)是什么样的。什么是基线预测baseline prediction?可以理解为最差的prediction。当然,如果我们什么模型都没有,就可以是baseline prediction,如果有模型的话,最开始可以试的就是linear regression。
回归分析(regression analysis)

什么是回归分析(regression analysis)?我们先来看什么时候可以用linear regression,回到刚才的图片,我们可以看到这里面有y有x等等,对于每一项的假设,实际上就是对整个模型的假设,所以一般来说,我们在讲一个模型的假设时,都会从mysql出发。
我们来看看这个linear regression的假设是什么。如果我们用了一个模型,但数据不符合我们的假设,那我们再去贸然去用模型,就会导致模型产生错误,所以在每次训练模型的时候,都要从假设出发去理解这个模型。让我们来看看这个linear regression,首先我们用linear的模式表示y和x,所以y和x就是线性关系,这个就是第一个假设。我们再来看最后一项,一般来说,我们假设它是一个正态分布(normal distribution),这个就是第二个假设,另外,我们还需要e之间每一个都是相对独立的,没有自回归的现象。最后一个假设是x之间没有相同贡献性。
一般来说,在实际案例中,如果点均匀的分布在线的两边,我们可以把它看成一个基本的linear regression。
回归分析(regression analysis)是一种统计的方法,它可以让你去分析两个或多个变量之间的相关性。一般来说,线性模型有两种基本的情况。一种是只有两个变量,一个x一个y,这是一个最基本的情况,我们把y当做反应变量,x是预测变量,这个就是我们用一个变量预测另一个变量。
另外一种情况可能会有multiple regression,就是有两个以上的变量在模型里面,也就是说对于x不止一个变量。而回归本身也不一定是线性的,如果是线性,就叫做线性回归linear regression,如果不是,就叫做非线性回归non-linear regression。最经典的non-linear regression,如果y是泊松分布,这时候就可以做一个泊松regression;如果y是指数分布,我们就可以做指数回归exponential regression,如果是log,就可以的做log regression,这个都是我们可以做的一些回归的方式。
那么,对于线性,我们怎么知道回归结果到底是好还是坏呢?这时候我们可以用R2进行分析。所以,我们经常会听到用说R2衡量我们的regression好还是不好,那为什么R2是一个比较好的衡量标准呢?

这个时候,我们可以简单的画一个图,首先,一个坐标轴里面有很多点,在这里面我们会有两部分SS,一个叫SSE,一个叫SST,这两个分别代表的什么呢?SST就是所谓的“total sum of squares”,在图形里表示就是所有图形的一个面。SSE就是”sum of squared errors”。
在图中可以清楚的看到,1的值永远大于2,1的部分减去2的部分会得到什么呢?这个叫SSM,也就是模型可以解释的部分。那么R2说的是什么呢?R2=SSM/SST;SSM是模型可以解释的部分,而SST是总的差别,这样,R2就可以理解为有百分之多少的差别可以用模型来解释。我们之前提到过的R=1-SSE/SST其实和SSM/SST是一样的,因为1-SSE=SSM。
所以,我们可以用R2来理解模型的适配是不是足够好。R2越大,说明可解释的越多,反之越少。对于一般的模型,如果R2越趋近于1,说明模型越好。对于更复杂的模型,我们可能看到R2仍然趋近于零。那是不是R2约等于1,就说明这是一个好的模型?
其实不是这样的。因为线性模型在很大程度上会受y的影响。例如,在下图中,点都在原点附近,说明高模型一定不是线性模型。但如果在远处有一个点,我们要做线性模型,那么该模型的R2会非常大,因为差异非常大。因为一个点就改变了整个模型,那么这么模型是好的吗?答案是否定的,因为这个点是异常值,很有可能为干扰项或者根本就不属于该模型。这就是为什么我们需要经常检查模型的总和是否正确。对于非线性模型, 我们实际上没办法计算总和,因为它实际上模仿了Epsilon。以上就是对线性模型数据的介绍。

接下来我们来做下简单的计算。
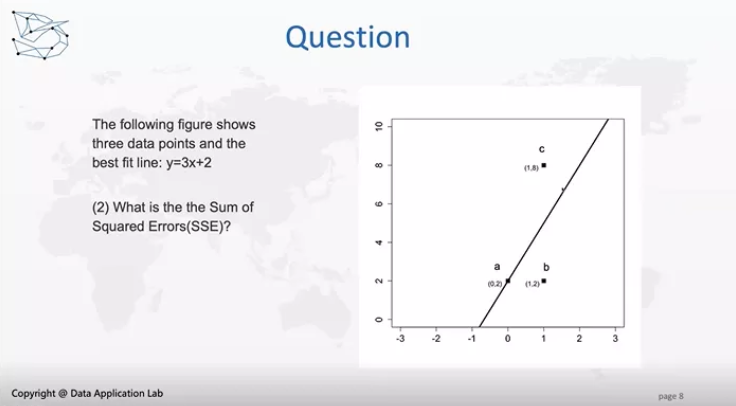
我们想知道a、b、c的SSE总和是多少。
答案:SSE=(Y1-(3X1+2))2+(Y2-(3X2+2))2+(Y3-(3X3+2))2=(2-2)2+(2-5)2+(8-5)2=18
SST需要用到该模型的平均值,即4(8+2+2/3)。
SST=(2-4)2+(2-4)2+(8-4)2=24
R2=1-18/24=0.25
说明该模型并不是很好,因为该模型非常简单,但是R2只有0.25。
我们再来看一个简单的问题:

本体的答案为B。
因为predictor之间不能有多重共线性。
接下来我们来讲逻辑回归(Logistic Regression)。
逻辑回归并不是一个回归模型,而是分类模型(Classification Model)。什么是分类模型?即响应变量为离散变量。
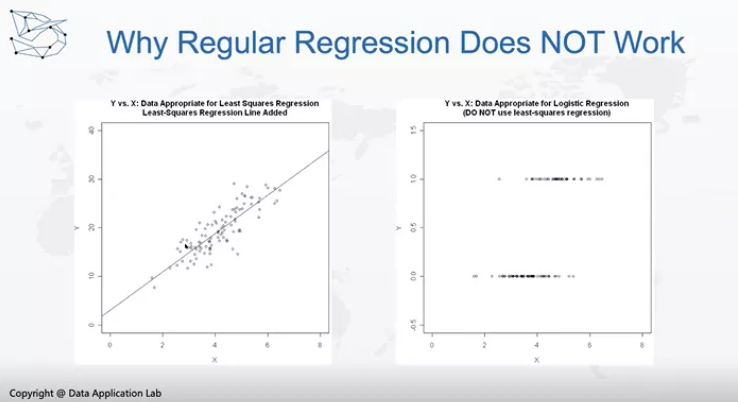
上图中,左边是线性回归,即每个点都落在线两侧,这就是一个很好的线性回归。
而对于Classification问题,就是右边这个图,可以看到y是0-1分布,如果我们强行拟合一个线性回归模型,也是可以的,但是为什么这个线性回归模型效果不佳?因为它也是需要考虑线性回归的假设条件,我们来验证一下线性回归模型的假设条件。
- 第一个假设是y和x是一个线性回归关系,y是一个离散的变量;
- 第二个是一个独立同分布的正态分布,这显然也不是;
- 第三是没有多重共线性(multicollinearity);
- 第四是误差项之间没有自回归性;
- 最后一个是误差项有一个constant variance或者叫同方差(homoscedasticity),因为它连正态分布都不算,不满这个条件,所以不能用线性回归模型。
如果不使用线性回归模型,那如何构建模型是它变得更有意义?
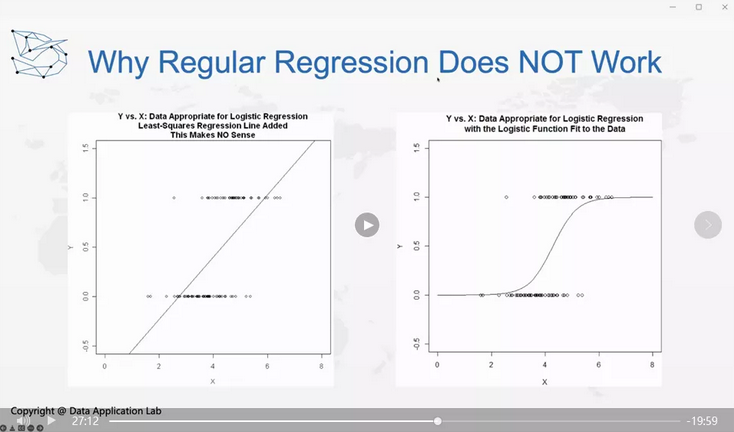
左图可以看到我们做了这样一条线来拟合,这个是不对的,那我们怎么让它工作呢,我们可以考虑做一下转换,比如说,可以做一条线去达到我们的效果。那我们怎么做转换呢?
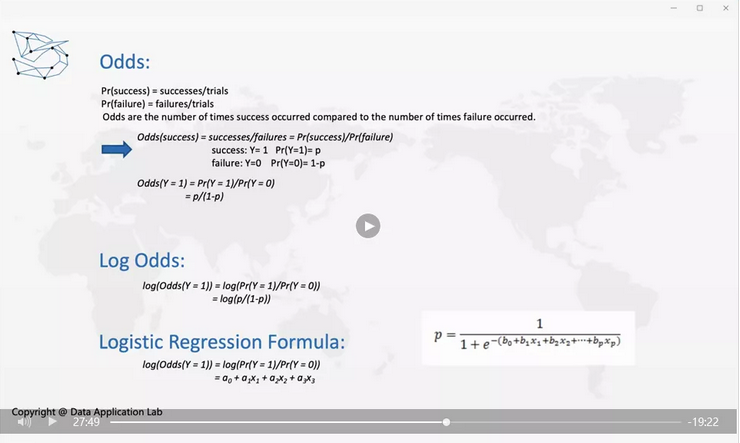
这个就是我们需要想的问题,我们可以考虑Odds。不知道大家是否知道赌博中有一个东西叫赔率(Odds),那什么是Odds呢?Odds就是我们赢得概率除以输的概率,叫做赔率。
一般来说,我们期待得到一个p,p是y等于1的概率,这个是我们可以回归的选项,因为最后我们实际上想要得到的结果是y=1的概率是多少,这个是我们需要解决的问题。
那么y=1时服从一个0-1分布,0-1实际上不可能是一个正态分布,所以我们要考虑怎么做一个转换。所以我们考虑用一个odds,odds就是P(Y=1)/P(Y=0),那这个时候他的分布范围是什么?P(Y=1)/P(Y=0)=P(Y=1)/(1-P(Y=1)),取值为(0, inf),从0到无穷也不能保证它是一个正态分布,那我们还需要考虑什么?我们还可以去log值,log(P(Y=1)/P(Y=0)=P(Y=1)/(1-P(Y=1))),取值为(-inf, inf),我们可以证明它是符合正态分布的。
也就是说,如果我们得到一个log的Odds,这时我们就可以说它是一个逻辑回归,而在这个上面做一个相对于线性回归的逻辑回归模型就会正常工作,所以逻辑回归是我们根据原来值的一个log Odd regression做的一个回归,这个就是我们所谓的回归。
所以逻辑回归公式就是log(Odds(y=1))=log(Pr(Y=1)/Pr(Y=0))=a0+a1x1+a2x2+a3x3,如果我们转化回来就是p=1/(1+e-(b0+b1x1+b2x2+…+bpxp)),这就是如何转化回来的情况。
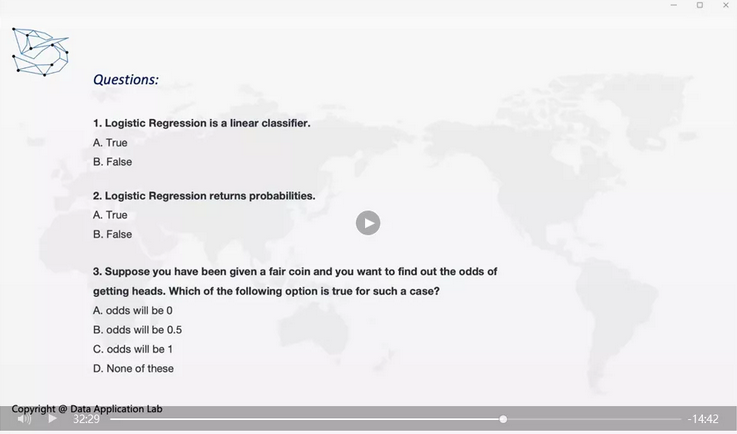
那我们来简单看一下问题:
1.逻辑回归是线性分类。Logistic Regression is a linear classifier.
这个是正确的,因为实际上我们就是在找线性分类器把它分开。
2. 逻辑回归会得到概率的结果。Logistic Regression returns probabilities.
这个也是正确的。
3. 如果你有个正常的硬币,你想知道翻到heads的概率是什么。下面哪个选项正确?Suppose you have been given a fair coin and you want to find out the odds of getting heads。Which of the following option is true for such a case?
如果是一个完美的硬币,那么等于1的概率是0.5,等于0的概率是0.5,那么这时Odds=1.
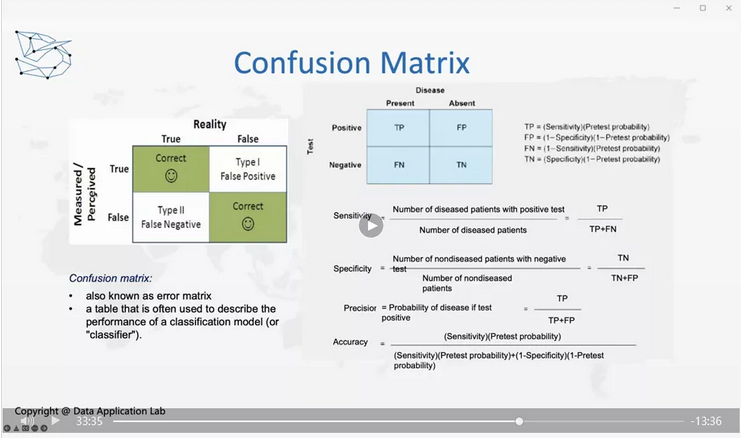
下面,我们来看看如何衡量我们模型的好坏。衡量模型好坏需要知道几个简单的概念,一个是混淆矩阵(Confusion Matrix),横轴是真实值(Reality),纵轴是预测值(Measured/Perceived)。如果我们真实值和预测值都是True或False,这是我们希望看到的,而当真实值是False,预测值是Positive,这个时候就是False Positive,因为我们预测出来的值是错误的,也是TypeⅠerror。
反过来,当真实值是True预测值是False,这时候就是False Negative,这是我们不希望看到的,也就是TypeⅡerror。那TypeⅠerror更严重还是TypeⅡerror更严重?
举个例子,比如核酸检测是False Positive对我们的影响更严重还是False Negative对我们的影响更严重?那什么是False Positive,什么是False Negative?或者说什么是Positive,什么是Negative?真实的Positive是你感染了新冠,真实的Negative是你没感染新冠,而预测的Positive是你的测试结果是感染新冠,Negative是你的测试结果是你没感染新冠。False Positive是你没感染新冠但是测试结果显示你感染了新冠,False Negative是你感染了新冠但是检测出来的结果是你没感染了新冠。False Positive的后果是你一个被隔离,多检测几次显示为Negative后被放出来,这就是最大的影响,而False Negative是你直接被放出来,接触更多的人,你可能会传染更多的人。显然,在这种情况下False Negative的影响更严重。
那我们再来想另外一个例子-法官断案,什么是真实的真假呢?现实的真是犯了罪,现实的假是没有犯罪。预测的真是法官断案认定有罪,预测的假是法官认定没有犯罪。那么false positive就是本身没犯罪却错误的断定有罪被关进监狱;false negative就是本身犯了罪却无法证明有罪就被放了出来。一般国家会做无罪假定就是为了避免false positive的发生,出现false positive的话就会冤枉无辜的人,所以一般来说都是宁可放过一些坏人也不能错误的抓无辜的人,因为抓无辜的人会导致政府的公信力受到质疑;如果是false negative的话可以下次再去抓,下次能够抓到的话也是一个不错的结果,所以这种情况下false negative的影响没有false positive大。
我们再来想一下信用卡欺诈检测的模型,false positive和false negative哪个影响更大?这个也是false negative影响更大。Reality positive是信用卡被盗刷了,Reality negative是信用卡没有被盗刷;Measurement positive是信用卡公司认为可能被盗刷了,Measurement negative是信用卡公司没有认为被盗刷;False Positive的影响是这次刷没刷过,需要给银行打电话信用卡可以重新使用,False Negative的影响是要么是自己要么是银行或是商家或是保险公司总有一方会损失钱。一般来说False Negative影响是更大的,这个就是所谓的混淆矩阵(Confusion matrix)。对于混淆矩阵我们还有其他的一些计算办法,比如说Sensitivity、Specificity。Sensitivity讲的是true positive, Specificity是指true negative,还有精确precision是指true positive在所有的test positive里面的占比。

同样,如果我们直接在某一个情况下去比较模型的性能,显然是不公正的,所以我们要在不同的决策标准下比较性能,这就可以用AUC、ROC去比较。如下图横轴是false positive rate(FPR),纵轴是true positive rate(TPR),切断下的面积越大,模型的性能就越好。
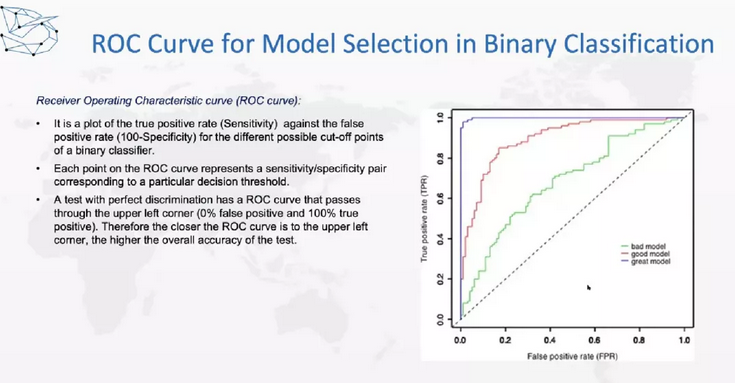
下面,是如何用回归做预测。一般来说,置信区间是可以通过统计推断得到的,但是有时候不太好推理,也可以用类似的方法进行计算。这就讲到的是Bootstrap—一种类似的方法帮助我们得到置信区间。Bootstrap是假设我们取1000个样品,对每一个样品都会有一个预测值,把预测值从小到大排列,第25和第975这两个值就是区间,我们把它拿出来就得到了95%的置信区间。这个就是我们如何用数值的方法帮助得到置信区间。
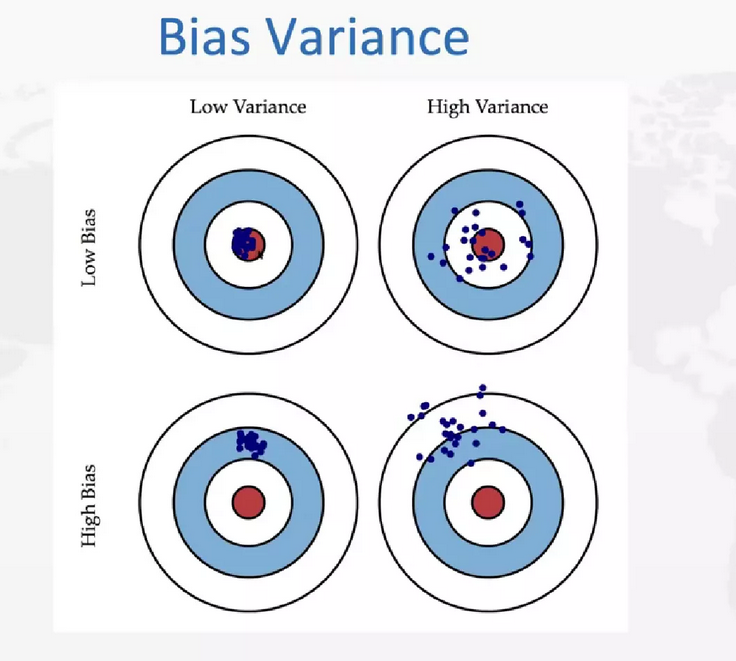
接下来是方差和偏差的权衡。这也是机器学习中经常提到的一个问题,我们可以用靶点来解释这个问题。都打在中心就叫做低方差低偏差,虽然都打在中心,但是相距比较远就叫做高方差低偏差,虽然都打在比较接近的一个位置,但都不是靶心叫做低方差高偏差, 既打都不是靶心,距离又很大叫高方差高偏差。我们最希望低方差低偏差,最不希望遇到高方差高偏差。在实际情况中,我们需要做的是下图中右上和左下的权衡,比如有高方差,如果想降低方差可能就会提高偏差,如果想降低偏差,可能就会提高方差。
想做右上和左下的权衡我们可以考虑这样一个模型:下图中simple和complex两个模型,左边的图是低方差高偏差,也叫underfitting,右边的图是高方差低偏差也叫overfitting。这两个情况我们都不希望出现,我们希望找到一个最好的点就是下图中的最佳点。
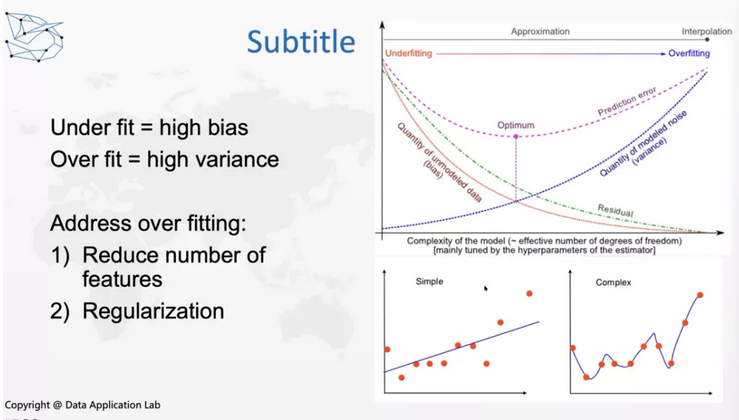
在实际的情况中,我们既不希望欠拟合发生,又不希望过拟合发生。如果发现under fitting发生,可以增加变量,如果发生over fitting,可以减少变量,可以通过减少功能和正则化来避免over fitting。这就是关于偏差和方差的权衡。
以上就是关于regression的全部内容,通过本文,希望你能了解到回归的概念和背后的技术逻辑,其他相关模型以及如何评估和运用模型。感谢你的阅读!你还可以订阅我们的YouTube频道,观看大量数据科学相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/





