
做数据科学项目,别再用Anaconda啦!
我还记得我在大学开始学习Python时开始接触了Anaconda。对我来说,它可以说上是一个多合一的Python Package,并包含了很多别的packages。
拜拜了pip install,我终于可以专注于写我的代码而不是去管那些需求了。如果你想了解更多关于数据科学的相关内容,可以阅读以下这些文章:
2022年,数据科学家文凭能让你赚多少钱?
谷歌数据科学家面试真题
基于云技术的数据仓库给数据科学带来的优势
职场转型与进阶:多年非Data相关工作经验,如何转行数据科学家?
后来有一天,当我正在为我的机器学习课程写程序的时候,问题出现了。这是一个非常简单的任务,加载csv数据集,进行数据加工处理,创建一些可视化效果,然后做一个训练模型。
“挺好,今晚我应该可以睡够8个小时,”我心想。
我们拿到了一个需要在任务中使用的python package的列表,并且有一个特定的package需要用到指定的numpy版本。
我输入了命令pip install -Iv numpy==1.11.0,它成功跑完了。接着我对其余要求的package也做了同样的事情。
但是,当我尝试导入某个package的时后 – 说实话我已经忘了它的名字,系统总是说遇到了错误,且我的计算机中安装了多个版本的numpys。
在我重新安装了那个numpy package一个多小时后,我决定先试试卸载所有numpy package,然后再安装指定的版本1.11.0。是的,我仍然记得那个numpy版本,因为那时我早就已经输入了近一百次。
“好吧,也许能睡6个小时。”
结果它还是说我已经安装了多个numpy package。我心烦意乱,决定拖延一下看了会儿YouTube。
明天必须交作业的恐慌情绪突然来了,我开始强迫自己去仔细检查一下那个错误信息。结果,另一个重复安装的numpy居然在Anaconda的内部。
最后,我同时卸载了Anaconda和Python,然后只重新安装了Python。
我重新安装所有要求的package后,第一次就运行正常了。解决问题后,我终于能开始写这个任务了。
“应该还能按计划睡6个小时。”
我看了一下时钟。
已经凌晨4点了。
我九点的课。
很多人会很快指出我做错了的地方,因为我在Anaconda基础上安装了pip packages。他们是对的,这是我遇到这个问题的根本原因。当时我并没有配置任何环境,只是在基础环境上运行的所有内容,我犯了个愚蠢的错误。
请不要像我一样随意混合pip和conda,以免遇到跟我上述一样的问题。
为什么要用Miniconda
在我作为AI工程师的第一次实习中,我的导师问我以前是否使用过Python packages管理器。我想给他留下良好的印象,所以我说我用过Anaconda。不过,我并没有讲我的不好的经历。
他说我应该用Miniconda代替Anaconda。他给了我以下原因:
- 安排一个项目时,你会希望它尽可能的精简。而 Anaconda绝不精简,它本身就将占用电脑2GB的空间。
- 对于程序员来说,心里要知道他们真正需要用到什么libraries,而不是让所有libraries都通过Anaconda,是一种好习惯。
- Miniconda比Virtualenv更好,因为从理论上讲,它还具有管理非Python packages的功能,因此它的用途更加广泛。
那让我们从基本的开始,什么是Miniconda?
Miniconda是conda的免费的最小安装包。它是Anaconda的小型引导程序版本,仅包含了conda,Python,一些它们必须的package以及少量其他有用的packages,如pip,zlib等。(docs.conda.io)
换句话说,Miniconda是Python的虚拟环境管理器。尽管它不如Docker强大而复杂,它能有效减少那种“明明在我的电脑上能跑”失败的发生。
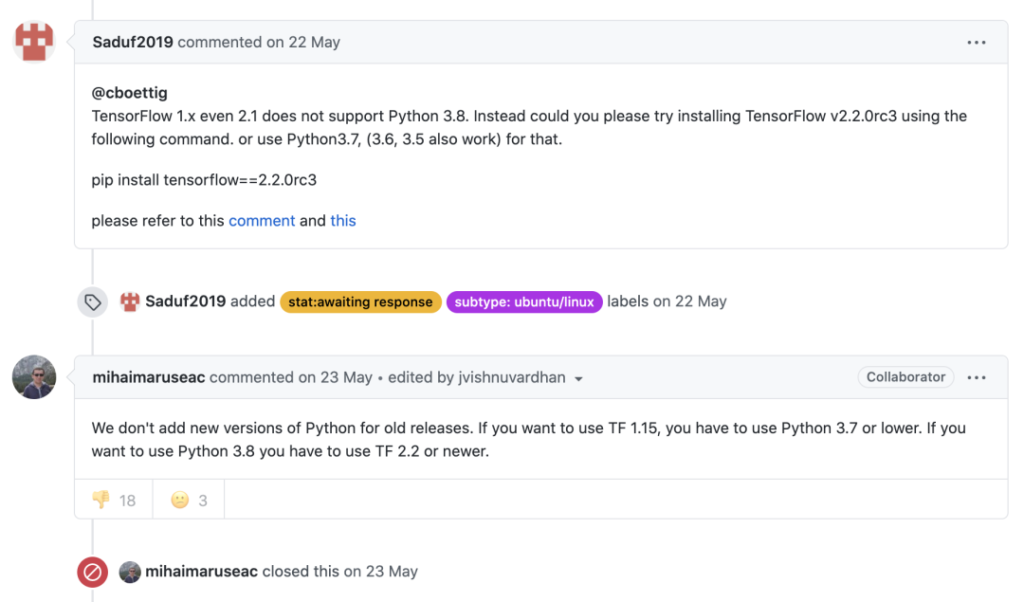
我在安装TF 2时遇到了一个问题,随后我在Github上也发现了它。
假设你要同时维护两个使用不同版本TF的项目,比方说一个是TF 1.15,另一个是TF 2.2,你就需要两个不同版本的Python3才能成功跑完代码。
我并不是说TF的支持不好,但这是我在设想一个冲突场景时想到的第一个例子。
当然,也存在着其他不使用Miniconda的方法,例如使用pyenv或virtualenv。请看一下这个stackoverflow答案,来比较下它们之间的区别。
有一个简化的miniconda版本,看起来比使用pip + virtualenv更为简单,但我个人但但没有使用它的经验。
作为使用Miniconda的人,我完全认为使用Miniconda是一种更简单,更流畅的体验。
安装
通过使用MacOS,我发现homebrew实际上能轻易帮你配制Miniconda。
安装homebrew后,只需运行brew cask install miniconda,即可安装Miniconda。如果你使用的是Linux或Windows系统,则可以遵守Linux和Windows相应的安装指南。你可以通过在终端中输入conda来测试安装是否正常。如果系统提示无法识别conda这个命令,那么请尝试重启终端。
我曾经在Windows系统上使用过Anaconda和Miniconda,我还记得必须手动将conda添加到Path中。你可以按照这个stackoverflow讨论中的说明进行操作。
配置环境
Conda环境应该是你使用Miniconda的主要原因。
很多Miniconda教程会教你输入下面内容来在终端配置环境。
conda create --name myenv其实有一种更简单直接的方法,是通过使用yml文件来配置conda环境。但是,即使在官方文档中,但出于某些原因,这个方法只是被放在了页面的底部。
在管理依赖项(dependency)时,不用使用requirements.txt,而是用如下所示的yml文件。
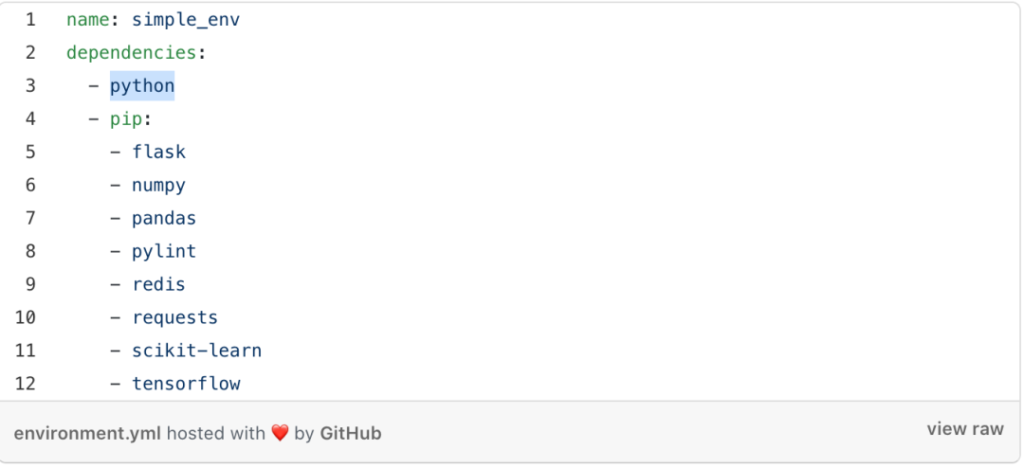
有人与我有分歧,因为我在基本环境上安装了pip,然后再在该pip之上使用Python package,而没有在conda环境中安装它们。我这样做有一个很好的理由——可用于pip的packages可能并不能在Conda上兼容。
以TensorFlow为例。在写下本文的此时,即使你已经添加了“conda-forge”这个通道,conda上也并没有TF 2.3.0。与其将某些package安装在conda上,而将某些package安装在pip上,我更希望把它们全部组合在pip下面来确保统一性。
你可以创建一个名为environment.yml的文件来配置环境,然后再输入以下指令。
conda env create -f environment.yml安装完成后,你可以使用以下命令来激活环境:
conda activate simple_env如果你用conda activate 命令时遇到问题,那你可能需要看一下这个stackoverflow里的帖子。
成功激活环境后,你可以用python3来打开Python会话,并尝试导入任何library来测试packages是否已经正确安装。
在生产环境中使用时,最好对有更详细的版本管理方案。作为数据科学家,dependency的损坏可能是你会面临的最大问题之一,因此你需要类似下列的东西:
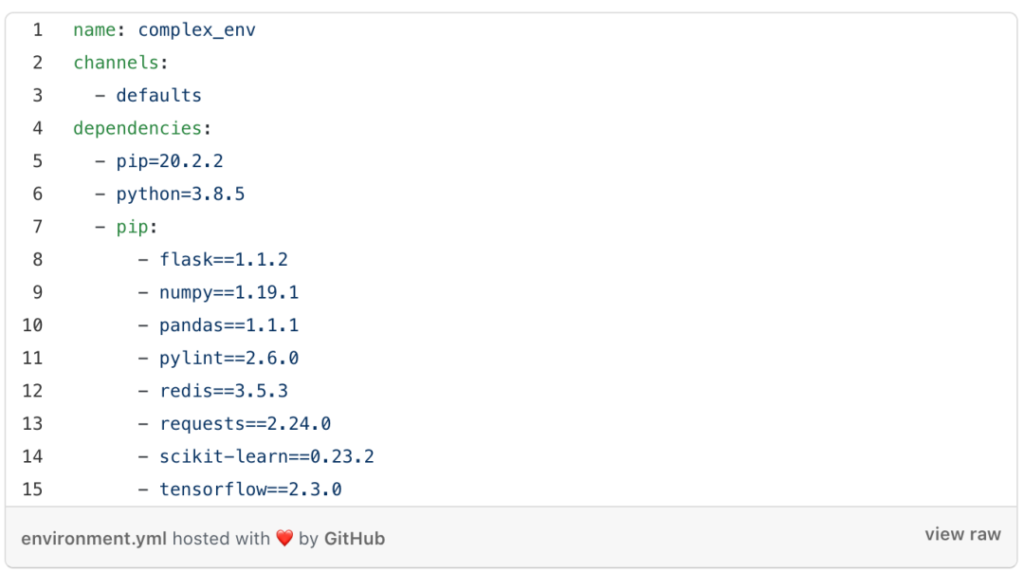
无论需要python 3.9运行的numpy或Tensorflow出了什么新版本,只要你指定一个特定版本时,你的环境都会按预期运行。你一直可以通过更改yml文件,再调用update命令来升级到新版本或添加新的dependency。
conda env update -f environment.yml将Conda添加到Jupyter Notebook
Jupyter Notebook是数据科学家或机器学习工程师中必不可少的工具之一。如果你还没有使用过Jupyter Notebook,甚至还没听说过Jupyter Notebook,可以用Google Colab来体验一下。
要注意的是,在你的终端上安装miniconda并不意味着它能在Jupyter Notebook中运行。
为了将conda环境设置为Jupyter中的内核,你需要在该环境中安装ipykernel。
conda activate condaenv
conda install ipykernel
python3 -m ipykernel install --user --name condaenv --display-name "Python3 (condaenv)"你可以设置任何你想要的显示名称,为了更容易记住, 我通常会设置和conda环境一样的显示名称。
完成这个操作后,你可以使用jupyter notebook来启动它并打开任何.ipynb 文件。在该文件中,选择菜单里的 Kernel > Change kernel > Python3 (condaenv)来激活conda环境内核。
Conda技巧
以下是一些我个人使用conda的技巧和经验。它们不是你必须专门要做的,而是可能会你在使用过程中对你有所帮助。
在环境文件里统一文件名
我以前是根据conda环境里的名称来命名环境文件。很有道理吧?这样你就能知道是哪个文件更新了哪个环境。
conda env create -f computer_vision.yml
conda env update -f computer_vision.ymlconda env create -f nlp.yml
conda env update -f nlp.yml问题是,你必须被迫记住这些环境文件的名称,或用ls | grep yml 来查看环境文件的名称。似乎没什么大不了的,但是随着时间的流逝,这些名字会越来越多。
解决方案是什么?我个人总是把环境文件命名为“ environment.yml”
Conda环境名称是在“名称”字段中被定义的。在yml文件使用不同的名称,并不会对环境名称产生任何影响。
所以,在创建或更新任何环境时,我们只需在终端上使用基于历史记录的自动完成功能即可。
conda env create -f environment.yml
conda env update -f environment.yml在这之上,你需要为每个项目创建一个conda环境文件,这就讲到了下一条内容。
使用仓库名称来命名环境
每个项目都应该有一个属于自己的环境,而不是与现有的其他项目共享。
在项目仓库和环境使用相同的名称,会让你更容易激活conda环境。这也说明在日常工作中需要你记住的一件事情少了,因此,如果我有一个conda环境下名为“ awesome-project”的仓库,那肯定也会使用“ awesome-project”来作为conda环境的名称。
按字母顺序排列packages
按字母顺序对packages排序可能听起来很蠢,但其实可以节省你(或你的同事)的很多时间。
以下是个还未排序的环境文件。
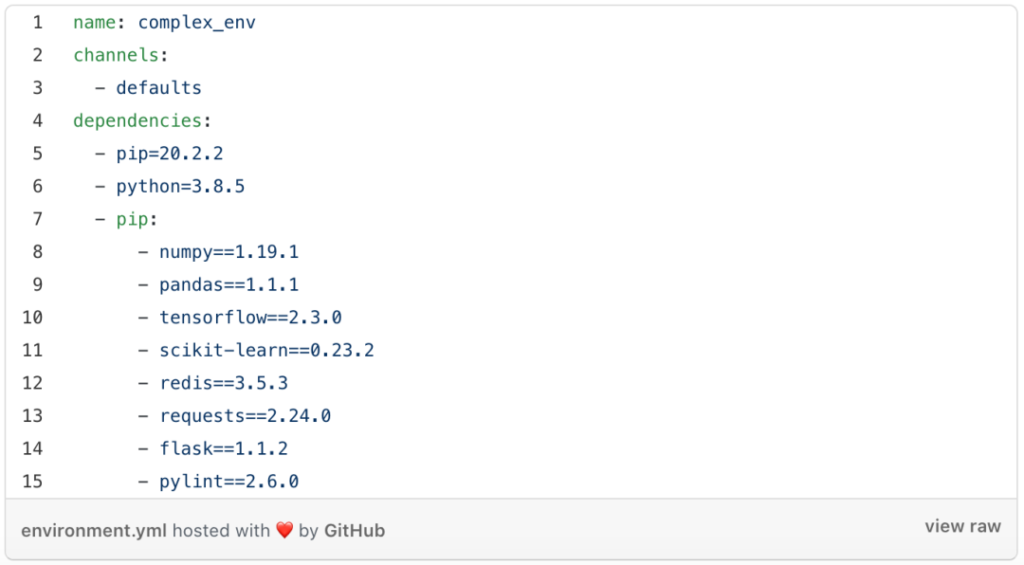
再对比看看这一个。
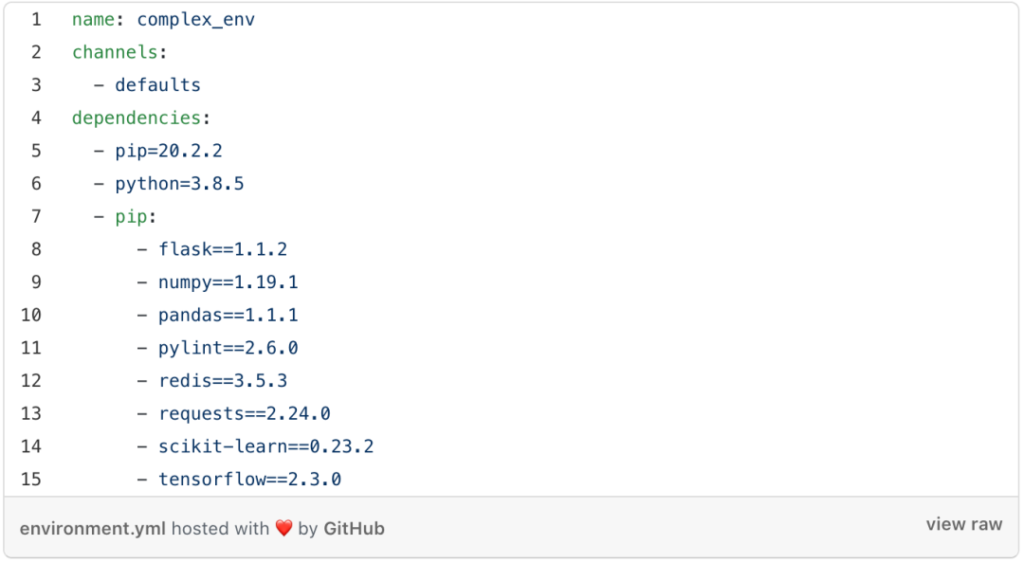
当你想添加另一个package,或更改package的版本时,在已排序好的的yml文件中手动搜索它会容易得多。
当然,你也可以在yml文件中使用搜索工具,但我还是更喜欢排序以后的环境。
并没有任何警告或建议告诉你必须这样做。这两个yml文件都可以在同一个环境下使用,但排序会使你维护环境文件时更加容易。
删除缓存来节省空间
当你安装新环境时,有时磁盘里会有一些多余的packages。根据你平时的使用情况,它的大小范围可能会从几MB到几GB。
如果你需要释放多余的空间,可以通过运行以下命令清除conda的缓存。
conda clean --all结语
如果到目前为止,你一直在使用Anaconda或根本不用conda,我希望现在的你可以了解Miniconda的优点并充分利用它。在pip上安装每个软件包可能不是使用conda的最佳办法,但比起去等待这些package在conda上出现,它能使你更快地访问到新的package。
从技术角度来说,你可以混合使用它们,及在conda上安装所有packages,然后在pip上安装较新的packages,不过我不太喜欢这样。当然,我上面所说的一切都是基于我的个人喜好。如果你还是喜欢Anaconda,或其他的环境管理,甚至利用Docker来管理你的环境,那都还是很好的选择。
归根结底,它们只是可以帮助你实现最终目标的工具。最好还是使用自己喜欢的工具,而不是并不熟悉的工具。你可以首先对练习使用新工具,直到你感到习惯为止;如果你觉得它比之前的工具更好,那么彻底换到新的工具。
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Rionaldi Chandraseta
翻译作者:Jiawei Tong
美工编辑:过儿
校对审稿:Dongdong
原文链接:https://medium.com/swlh/stop-using-anaconda-for-your-data-science-projects-1fc29821c6f6





