
Netflix系统设计:构建高可用、可扩展的流媒体平台
让我们设计一个类似Netflix的视频流媒体服务,类似于亚马逊Prime Video、Disney Plus、Hulu、YouTube、Vimeo等服务。
什么是Netflix?
Netflix是一种让用户订阅的流媒体服务,允许会员在互联网设备上观看电视节目和电影。它可在Web、iOS、Android、电视等平台上使用。
要求
我们的系统应满足以下要求:
功能需求
- 用户应能够流式传输和分享视频。
- 内容团队(或YouTube中的用户)应能够上传新的视频(电影、电视剧集和其他内容)。
- 用户应能够使用标题或标签搜索视频。
- 用户应能够像YouTube一样对视频发表评论。
非功能性需求
- 高可用性和最小延迟。
- 高可靠性,不应丢失上传内容。
- 系统应具有可扩展性和高效性。
扩展需求
- 某些内容应该受到地理限制。
- 恢复从用户离开的点开始的视频播放。
- 记录视频的指标和分析数据。
估计和限制条件
让我们从估计和限制条件开始。
注意:确保与面试官一起检查任何与规模或流量相关的假设。
流量
这将是一个读取为主的系统,假设我们有10亿个总用户,每天活跃用户(DAU)为2亿,每个用户平均观看5个视频,这意味着我们每天有10亿个视频被观看。
60419 200 \space million \times 5 \space videos = 1 \space billion/day 60419
假设读写比为1:1,每天大约会上传约5000万个视频。
60419 \frac{1}{200} \times 1 \space billion = 50 \space million/day 60419
我们的系统的每秒请求数(RPS)将是多少?
10亿个请求每天相当于每秒12000个请求。
60419 \frac{1 \space billion}{(24 \space hrs \times 3600 \space seconds)} = \sim 12K \space requests/second 60419
存储
如果我们假设每个视频平均为100MB,那么我们每天将需要大约5PB的存储空间。
60419 50 \space million \times 100 \space MB = 5 \space PB/day 60419
对于10年来说,我们将需要18,250 PB的存储空间(惊人的数字)。
60419 5 \space PB \times 365 \space days \times 10 \space years = \sim 18,250 \space PB 60419
带宽
由于我们的系统每天处理5PB的流入数据,我们将需要至少每秒58GB的带宽。
60419 \frac{5 \space PB}{(24 \space hrs \times 3600 \space seconds)} = \sim 58 \space GB/second 60419
高级估计
这是我们的高级估计:
| Type | Estimate |
| Daily active users (DAU) | 200 million |
| Requests per second (RPS) | 12K/s |
| Storage (per day) | ~5 PB |
| Storage (10 years) | ~18,250 PB |
| Bandwidth | ~58 GB/s |
数据模型设计
这是反映我们需求的一般数据模型。
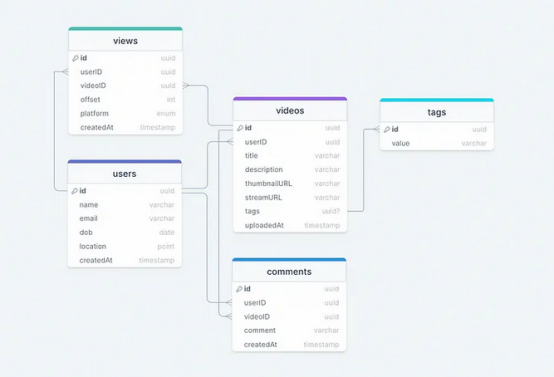
我们有以下表格:
users
这个表格将包含用户的信息,例如用户名、电子邮件、密码等详细信息。
videos
顾名思义,这个表格将存储视频及其属性,例如标题、描述、发布日期等。我们还将存储相应的用户ID。
tags
这个表格将简单地存储与视频相关的标签。
views
这个表格帮助我们存储视频的所有观看次数。
comments
这个表格存储在视频上收到的所有评论(类似于YouTube)。
我们应该使用什么样的数据库?
虽然我们的数据模型似乎具有很强的关系性,但我们不一定需要将所有内容存储在单个数据库中,因为这可能限制了我们的可扩展性并很快成为瓶颈。
我们将数据分割成不同的服务,每个服务对特定的表格负责。然后,我们可以针对我们的用例使用关系型数据库,如PostgreSQL,或分布式NoSQL数据库,如Apache Cassandra。
API设计
让我们为我们的服务进行基本的API设计:
上传视频
给定一个字节流,此API使视频能够上传到我们的服务。
参数
- 标题():新视频的标题
- 描述():新视频的描述
- 数据():视频数据的字节流
- 标签():视频的标签(可选)
返回
- 结果():表示操作是否成功
流式传输视频
此API允许用户使用首选的编解码器和分辨率来流式传输视频。
参数
- 视频ID():需要流式传输的视频的ID
- 编解码器():所请求视频所需的编解码器,如,,,等
- 分辨率():所请求视频的分辨率
- 偏移量():视频流的偏移量(以秒为单位),以从视频的任意点开始流式传输数据(可选)
返回
- 流():所请求视频的数据流
搜索视频
此API将允许用户根据视频的标题或标签搜索视频。
参数
- 查询():用户的搜索查询。
- 下一页():下一页的令牌,可用于分页(可选)。
返回
- 视频():特定搜索查询可用的所有视频
添加评论
此API将允许用户在视频上发表评论(类似于YouTube)。
参数
- 视频ID():用户想要评论的视频的ID
- 评论():评论的文本内容
返回
- 结果():表示操作是否成功
高级设计
现在让我们对系统进行高级设计。
架构
我们将使用微服务架构,因为这样可以更容易地水平扩展和分离我们的服务,每个服务将拥有自己的数据模型,让我们尝试将系统划分为一些核心服务。
用户服务
该服务处理与用户相关的问题,如身份验证和用户信息。
流媒体服务
该服务将处理与视频流媒体相关的功能。
搜索服务
该服务负责处理与搜索相关的功能,将单独详细讨论。
媒体服务
该服务将处理视频上传和处理,将单独详细讨论。
分析服务
该服务将用于度量和分析用例。
那么服务之间的通信和服务发现怎么办?
由于我们的架构是基于微服务的,所以服务之间也会进行通信。通常,REST或HTTP表现良好,但我们可以使用gRPC进一步提高性能,因为它更轻量级和高效。
服务发现是另一个我们必须考虑的事情。我们还可以使用服务网格,它可以在各个服务之间实现可管理、可观察和安全的通信。
注意:了解更多关于REST, GraphQL, gRPC 以及它们之间的比较。
视频处理
在处理视频时,涉及到很多变量。例如,高端相机拍摄的两小时原始8K素材的平均数据大小可能高达4TB,因此我们需要进行一些处理来减少存储和传输成本。
下面是我们在内容团队(或YouTube用户)上传视频后,将其排队等待处理的消息队列中如何处理视频的方式。
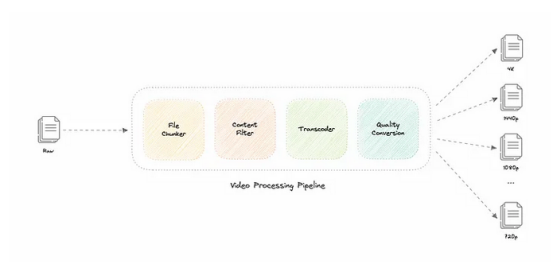
让我们来讨论一下它是如何工作的:
- 文件分块
这是我们处理流程的第一步。文件分块是将文件分割成较小的称之为块的过程。它可以帮助我们消除存储中重复的数据副本,并通过仅选择更改的分块来减少通过网络传输的数据量。
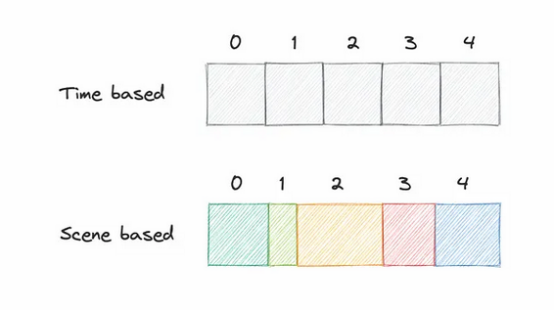
通常,视频文件可以根据时间戳分割成相等大小的分块,但Netflix会根据场景分割分块,这种细微的变化对于更好的用户体验来说是一个重要的因素,因为每当客户端从服务器请求一个分块时,中断的机会较低,因为将检索到完整的场景。
- 内容过滤器
此步骤检查视频是否符合平台的内容政策,对于Netflix来说,这可能是预先批准的,根据媒体的内容评级,或者像YouTube一样,可能是严格执行的。
这整个步骤是由一个机器学习模型完成的,该模型执行版权、盗版和不适宜内容检查。如果发现问题,我们可以将任务推送到一个死信队列(DLQ),然后由审核团队的成员进行进一步检查。
- 转码器
转码是一种将原始数据解码为中间未压缩格式的过程,然后再将其编码为目标格式的过程。该过程使用不同的编解码器来执行比特率调整、图像降采样或重新编码媒体。
这将导致文件大小更小,以及更适合目标设备的优化格式。可以使用独立的解决方案(如FFmpeg)或基于云的解决方案(如AWS Elemental MediaConvert)来实现此流程的这一步。
- 质量转换
这是处理流程的最后一步,顾名思义,此步骤处理来自上一步转码媒体的不同分辨率(如4K、1440p、1080p、720p等)的转换。
这使我们可以根据用户的请求获取所需的视频质量,一旦媒体文件完成处理,它将被上传到分布式文件存储(如HDFS、GlusterFS)或对象存储(如Amazon S3),以便在流媒体播放期间进行后续检索。
注意:我们可以将字幕和缩略图生成等额外步骤添加到我们的流程中。
为什么要使用消息队列?
将视频处理作为长时间运行的任务更有意义,而消息队列还将我们的视频处理流程与上传功能解耦。我们可以使用类似Amazon SQS或RabbitMQ的工具来支持这一点。
视频流媒体
无论是从客户端还是服务器的角度来看,视频流媒体都是一项具有挑战性的任务。此外,不同用户的互联网连接速度差异很大。为了确保用户不会重新获取相同的内容,我们可以使用内容分发网络(CDN)。
Netflix通过其Open Connect计划进一步发展了这一点。在这种方法中,他们与数千个互联网服务提供商(ISP)合作,将其流量本地化,并更高效地提供其内容。
Netflix的Open Connect与传统的内容分发网络(CDN)有什么区别?
Netflix Open Connect是我们专门为Netflix视频流量提供服务的内容分发网络(CDN)。全球大约95%的流量通过Open Connect与用户用于访问互联网的ISP之间的直接连接进行传输。
目前,他们在全球范围内的1000多个不同位置都有Open Connect设备(OCA)。如果出现问题,Open Connect设备(OCA)可以故障转移,并且流量可以重新路由到Netflix服务器。
此外,我们可以使用自适应比特率流媒体协议,例如HTTP Live Streaming(HLS),该协议专为可靠性而设计,并通过优化播放以适应连接的可用速度来动态适应网络条件。
最后,为了从用户离开的地方开始播放视频(我们的扩展需求的一部分),我们可以简单地使用我们在表中存储的属性来检索该特定时间戳处的场景分块,并为用户恢复播放。
搜索
有时传统的数据库管理系统性能不够高,我们需要一些可以快速存储、搜索和分析海量数据并在几毫秒内给出结果的解决方案。Elasticsearch可以帮助我们实现这个用例。
Elasticsearch是一个分布式、免费和开放的搜索和分析引擎,适用于各种类型的数据,包括文本、数字、地理空间、结构化和非结构化数据。它构建在Apache Lucene之上。
我们如何确定热门内容?
热门功能将基于搜索功能。我们可以缓存最近几秒钟内最频繁搜索的查询,并使用某种批处理作业机制每秒更新它们。
分享
分享内容是任何平台的重要组成部分,为此,我们可以使用某种URL缩短服务,为用户生成短URL以进行分享。
详细设计
现在是时候详细讨论我们的设计决策了。
数据分区
为了扩展我们的数据库,我们需要对数据进行分区。水平分区(也称为分片)可以是一个很好的第一步。有很多分区方案可供选择,例如:
- 哈希分区
- 列表分区
- 范围分区
- 复合分区
上述方法仍可能导致数据和负载分布不均,我们可以使用一致性哈希来解决这个问题。
地理阻止
像Netflix和YouTube这样的平台使用地理阻止来限制特定地理区域或国家的内容。这主要是由于Netflix与制作和分发公司达成协议时必须遵守的法律分销法规。在YouTube的情况下,这将由用户在发布内容时控制。
我们可以使用用户的IP或其个人资料中的地区设置来确定用户的位置,然后使用支持地理限制功能的服务,如Amazon CloudFront,或者使用Amazon Route53的地理位置路由策略,当某内容在该特定地区或国家中不可用,它将会把用户重定向到错误的页面。
推荐
Netflix使用一个机器学习模型,根据用户的观看历史预测用户可能想要观看的下一个内容,可以使用协同过滤等算法。
然而,Netflix(像YouTube一样)使用自己的算法,称为Netflix推荐引擎,可以跟踪多个数据点,例如:
- 用户的个人资料信息,如年龄、性别和位置
- 用户的浏览和滚动行为
- 用户观看标题的时间和日期
- 用于流媒体内容的设备
- 搜索次数以及搜索的词汇
指标和分析
记录分析和指标是我们的扩展需求之一。我们可以从不同的服务中捕获数据,并使用Apache Spark对数据进行分析,Apache Spark是一个用于大规模数据处理的开源统一分析引擎。此外,我们可以将关键元数据存储在视图表中,以增加我们的数据点。
缓存
在流媒体平台中,缓存非常重要。我们必须能够尽可能多地缓存静态媒体内容,以提高用户体验。我们可以使用Redis或Memcached等解决方案,但哪种缓存驱逐策略最适合我们的需求?
使用哪种缓存驱逐策略?
最近最少使用(LRU)可以成为我们系统的良好策略。在这个策略中,我们首先丢弃最近最少使用的键。
如何处理缓存未命中?
每当发生缓存未命中时,我们的服务器可以直接访问数据库并使用新的条目更新缓存。
媒体流媒体和存储
由于我们的大部分存储空间将用于存储缩略图和视频等媒体文件。根据我们之前的讨论,媒体服务将处理媒体文件的上传和处理。
我们将使用分布式文件存储,如HDFS,GlusterFS,或像Amazon S3这样的对象存储来存储和流式传输内容。
内容交付网络(CDN)
内容交付网络(CDN)可以增加内容的可用性和冗余性,同时降低带宽成本。通常,静态文件如图像和视频是从CDN提供的。我们可以使用像Amazon CloudFront或Cloudflare CDN这样的服务来处理这种情况。
识别和解决瓶颈问题
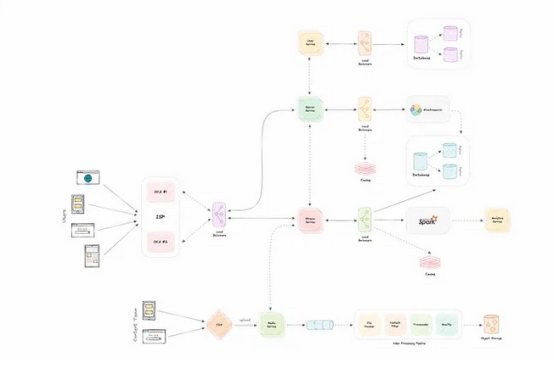
让我们识别和解决设计中的瓶颈,例如单点故障:
- “如果我们的其中一个服务崩溃怎么办?”
- “我们如何在各个组件之间分发流量?”
- “如何减轻数据库的负载?”
- “如何提高缓存的可用性?”
为了使我们的系统更具弹性,我们可以采取以下措施:
- 运行每个服务的多个实例
- 在客户端、服务器、数据库和缓存服务器之间引入负载均衡器
- 为我们的数据库使用多个读取副本
- 为我们的分布式缓存使用多个实例和副本
原文作者:Mukesh Singh
翻译作者:过儿
美工编辑:过儿
校对审稿:Chuang
原文链接:https://medium.com/@karan99/system-design-netflix-6962b4f6222





