
想了解AB测试?重要概念合集就在这里!
实验单元和随机单元有什么区别?AA-Test 是用来做什么的?本文为你精挑细选了一些 AB 测试重要术语! 接下来,将提到在网站上运行的 AB 测试,这些测试的内容涉及众多领域,包括应用程序、营销活动等,通过假设测试来衡量某一变化带来的影响。如果你想了解更多数据分析相关内容,可以阅读以下这些文章:
Amazon商业分析师面试指南
如何准备Front-End Back-End岗位面试?
数据岗位大合集|DS、DA、BA和DE的区别及求职面试重点
硅谷数据科学家岗位哪家工资高,哪家面试题难?揭秘FANNG迥异的面试画风!
AA-测试
在 AA测试中,实验组和对照组之间没有差异。AA测试用于验证进行 AB测试的统计假设是否有效(例如,合理的随机样本)。预计这类测试的报告中,测试组和对照组之间没有差异。
AB测试
AB 测试用于比较网站的两个或多个版本。在这些测试中,根据用户的不同,我们也会随机看到网站的不同版本。然后使用统计分析,来确定网站的更改是否对看到新版本的用户产生巨大影响。
分析单元(Analysis Unit)
在进行AB测试时,分析单元是度量的分母。例如,你可以跟踪每个用户或会话的点击率,而用户和会话都可能成为分析单位。
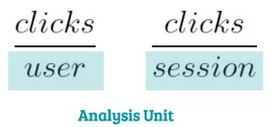
实验单元可以,但不必与随机变体和实验单元相同。
贝叶斯与频率测试
(Bayesian vs. Frequentist Testing)
贝叶斯统计和频率统计是计算统计测试显着性的两种的不同思想流派。长期以来,频率统计一直是 AB测试的行业标准。但是贝叶斯统计的优点也非常显著,吸引了越来越多的关注。
两种方法都在回答同一个问题-哪个版本最好?这个问题,两者使用不同的方法来得出结论。简而言之,贝叶斯实验使用过往实验(或我们的经验)的数据,而频率论方法仅依赖于来自测试的数据。
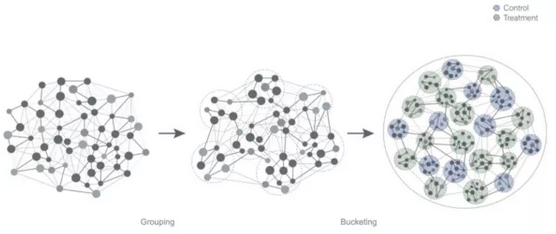
分桶测试(Bucketing)
分桶测试指的是如何将用户随机分配到对照组或实验组之一。使用 cookie 或其他属性(例如帐户 ID)来识别用户,然后在实验期间,将其分配给其中一个版本。有一点很重要,就是被分配到同一个实验中的用户,不能看到其他的版本。因此,每当用户返回站点时,分桶必须保持一致。
Cookie流失
使用 cookie 来识别和存储用户有几个缺点,可能会影响测试结果。Cookie流失是指用户从浏览器中删除 cookie 的现象。这些用户在返回网站时无法被 AB测试的工具识别。因此,重复删除 cookie 的用户会收到新生成的 cookie,并再次随机分配给一个版本。
这不仅会导致测试中用户数量信息出现错误。对于之前已经接触过某个版本的用户,如果在短时间内系统处理不同,用户的行为可能也会不同,从而导致结果出现偏差。同时,测试时间越长,也就越容易出现Cookie 流失。
对照组
对照组是实验中未接触到测试版本的用户组。作为参考,对照组和测试组之间的行为差异可用于衡量变化的效果。

实验单元
实验单元是导流单元,用于识别、并将其分入不同的实验单元。这类实体可以是用户的标识符,例如帐户 ID(或 cookie)。实验单元可以,但不必与随机化和分析单元相同。
外部有效性
外部有效性是指:AB 测试的结果是可概括大部分情况的。尽管有正确的统计设置,但在非代表性样本上进行实验时,实验结果可能会有偏差。例如,一个旅游网站在假日季和淡季进行测试时,结果可能大相径庭,而这仅仅可能是因为网站上的用户群体差异很大。
划分组
划分组的用户不会被分入任何实验,而是作为划分对照组保留。从理论上讲,这样做可以在不进行任何转换优化的情况下,深入了解网站的性能。关于划分组的作用,人们存在不同的意见。其中,批评者声称划分组通常不能代表整个用户群体,因为他们只是短暂用户。
假设
这里指的是我们想要在 AB 测试中验证的假设。例如,“增加登录按钮的大小可以增加用户的点击量”。通过假设测试,我们可以在统计框架中反驳假设,减小错误决策的可能性。
驳斥假设是替代假设的间接证据。所以,为了检验更大的登录按钮是否真的能带来更高的点击率,我们不得不反驳以下假设:“增加登录按钮的尺寸并不会增加用户的点击量。”
最小可检测效应
最小可检测效应决定了我们想要以一定概率在 AB 测试中检测到的最小效应大小。最小可检测效应越小,进行 AB 测试时需要收集的样本越多,测试持续时间也就越长。例如,如果一个产品团队想要测试一个新的按钮设计,那么与2% 的变化相比,更容易检测到20% 的点击率。
所需的最小样本量
所需的最小样本量指,在评估结果之前,必须在 AB 测试的每个实验单元中收集的样本数量。该参数是使用选定的功效、显着性水平、以及所需的最小可检测效应大小计算的。所需的最小样本量越大,测试持续时间越长。
多变量测试
多变量测试或 A/B/n testing,是针对对照测试的多个版本的实验。这些测试可用于比较相同问题的不同解决方案(例如不同的按钮颜色)并确定哪个选项效果最佳。在一次测试中,变体数量较多,会增加测试的 I 类错误率。因此,有必要调整在分析具有多个变体的 AB 测试时使用的统计模型。

首位/新奇效应
(Primacy/Novelty Effect)
新奇效应是指,用户首次接触一项新功能时,单纯出于好奇而表现出更高的参与度。在决定是否应该实施新功能时,高点击率可能会让人产生错觉,因为当用户习惯新功能时,该指标可能很快就会恢复平常。
随机化
随机化是 AB 测试的重要组成部分。所有用户都有可能被分到对照组或测试组之一,事实上,所有用户都有可能在对照组或测试组中被淘汰,我们可能会因为这一事实而忽略那些未被观察到的因素,从而对结果产生影响。
假设我们将所有新用户都放在对照组中,将所有有经验的用户放在测试组中,那我们观察到的任何偏差都可能是由于两个群体的性质不同,而不是因为我们正在测试的内容不同而引起的。随机化保证了我们在每组中都有一个具有代表性的用户样本,处理不同,观察到的效应也就不同。
随机化单位
通常,测试在用户层次上是随机的。这意味着,用户会被随机分配到一个测试桶。在某些情况下,在不同层次上进行随机测试是有意义的。例如,如果 Facebook 测试了一个新的群组功能,那么在群组这个层次上进行随机测试是没问题的,这样,群组中的所有用户都具有相同的体验:
随机化单位可以,但不必与实验和分析单位相同。
序列AB测试(Sequential AB-Testing)
序列AB测试是AB测试中的一种方法,用户可以提前停止测试,但测试结果仍然有效。在传统的 AB 测试中,必须在收集到所需样品的最低数量后才能分析结果。在序列测试中,在测试运行时对收集的样本进行持续验证,如果效应很明显,那么测试人员就可以提前停止测试。
统计显著性(Statistical Significance)
当达到显著水平,我们就可以控制驳斥假设(并作出更改)的概率,尽管它是正确的(更改内容不会导致网站显著改进)。因此,显著性水平越高,犯Ⅰ类错误的概率就越低。如果对照组和测试组之间的差异大到足以反驳零假设、并作出更改,那么测试人员也会提及具有统计意义的结果。
统计功效
有了功效的级别,我们就可以控制不反驳零假设(因此不作出更改)的概率,尽管它是错误的(且更改具有积极影响)。这意味着,测试的统计功效越高,我们就越有可能发现其效应,并且犯下 II 类错误的可能性越低。
实验
实验描述了我们在 AB 测试中测试的版本。当对照组中的用户看到网站的当前状态时,测试组中的用户会接受实验。然后测量处理效果,来确定测试结果。

触发
点击某一按钮、打开某一网站或尝试登录;有时我们只想让那些执行某一操作的用户,而不是所有用户都参与。只有当用户执行某一特定操作时,才会触发实验,并将用户分入其中一个实验单元格中。这个概念非常重要,因为触发有助于过滤噪音,让实验中的用户真正受到变量的影响。
Ⅰ类错误(False Positive)
I 类错误描述了一种错误类型,我们预测假设错误,但实际上该假设是正确的。例如,我们的原假设可能是“将结帐按钮颜色更改为绿色不会增加点击率。”当犯第一种错误时,我们会反驳零假设(因此将按钮设为绿色),但实际上,绿色按钮的点击次数没有显着增加。我们可以通过调整显着性水平来控制此错误的概率。
Ⅱ类错误(False Negative)
II 类错误描述了我们在不反驳零假设时犯的错误类型,而实际上该假设是错误的。我们可能不会拒绝原假设“将结帐按钮颜色更改为绿色,不会增加点击率。”,尽管实际上这个假设是错误的。因此,我们可能不会将按钮设为绿色,尽管这会导致更高的点击率。我们可以通过调整测试的功效来控制这种错误的概率。
感谢阅读!你还可以订阅我们的YouTube频道,观看大量数据科学相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Dennnis Meisner
翻译作者:Lia
美工编辑:过儿
校对审稿:Jiawei Tong
原文链接:https://productcoalition.com/the-ab-testing-dictionary-a565acf6d260





