")
一文了解机器学习中的F1分数(F1 Score)
本文是关于机器学习中F1分数,你需要了解的信息,以Python为例。如果你想了解更多关于机器学习的相关内容,可以阅读以下这些文章:
机器学习中的文本分类是什么?
Ins 数据科学、机器学习及AI宝藏博主推荐
机器学习在安全领域撒过的美丽的谎言
5种有效方法:提高机器学习模型的准确性
介绍|F1分数
F1分数是机器学习中用于分类模型的评估指标。尽管分类模型存在许多评估指标,但在本文中,你将了解如何计算F1分数以及何时使用它才更有意义。
F1分数是对两个简单评估指标的改进。因此,在深入了解F1分数之前,我们先回顾一下F1分数的基础指标。
准确率(Accuracy)
准确率是分类模型的一个指标,用于衡量正确的预测数量占所做预测总数的百分比。例如,如果你90%的预测是正确的,那么准确率就是90%。
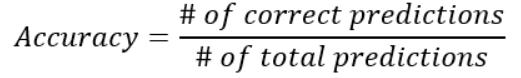
只有当分类中的类分布均等时,准确率才是有用的指标。这意味着,如果你用例中的一类数据点多于另一类的数据点,那么准确率就不是一个有用的指标。
不平衡数据示例
假设你在处理网站的销售数据。你知道99%的网站访问者不购买,只有1%的访问者购买了东西。构建一个分类模型来预测哪些访问者是买家,哪些只是浏览者。
可以预料到这个模型效果不佳,它预测100%的访问者只是浏览者,而0%的访问者是买家。
当你遇到不平衡数据时,准确率不是一个很好的指标。
如果我们在这个模型上使用准确率公式会发生什么?你的模型只预测了1%的错误:所有的买家都被误认为浏览者。因此,正确预测的百分比为99%。这里的问题是99%的准确率听起来是一个很好的结果,而你的模型表现很差。
通过重采样解决不平衡数据
解决不平衡问题的一种方法是处理数据。使用特定的采样方法,重新采样数据集,使数据平衡,然后再使用准确率作为指标。在本文中,你可以了解如何使用这些方法,包括欠采样、过采样和SMOTE。
通过指标解决不平衡数据
解决不平衡问题的另一种方法是使用更好的准确率指标,例如F1分数,它不仅考虑模型预测的错误数量,还考虑错误类型。
F1分数的基础:精确率(Precision)和召回率(Recall)
精确率和召回率是考虑到数据不平衡的两个最常见的指标。它们是F1分数的基础!
精确率:F1分数的第一部分
精确率是F1分数的第一部分。它也可以用作单独的机器学习指标。它的公式如下所示:

你可以按如下方式解释此公式。在所有被预测为正的情况下,精确率计算正确的百分比:
- 一个不精确的模型可能会找到很多正样本,但它的选择方式很杂乱:它也会错误地预测到许多实际上不是正样本的正样本。
- 一个精确的模型是非常“纯粹的”:也许它没有找到所有的正样本,但预测结果很可能是正确的。
召回率:F1分数的第二部分
召回率是F1分数的第二个组成部分,尽管召回率也可以用作单独的机器学习指标。它的公式如下所示:
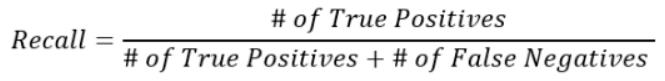
你可以按如下方式解释此公式。在所有正样本中,模型成功地预测了多少:
- 具有高召回率的模型可以很好地找到数据中所有正样本,即使它们可能错误地将一些负样本识别为正样本。
- 召回率低的模型无法找到数据中所有(或大部分)正样本。
精确率vs召回率
以超市销售有问题的产品为例,他们只想找到所有有问题的商品。客户寄回的产品是否有问题对他们来说并不重要,这家超市不关心精确率。
精确率和召回率权衡
理想情况下,我们需要模型可以识别所有的阳性病例,并只识别阳性病例。
但在现实生活中,我们不得不处理所谓的精确率和召回率权衡。
精确率和召回率权衡表示,在许多情况下,你可以调整模型降低召回率来提高精确率,或者另一方面以降低精确率为代价来提高召回率。
F1分数:结合精确率和召回率
精确率和召回率是F1分数的两个组成部分。F1分数的目标是将精确率和召回率组合成一个指标。同时,F1分数能很好地处理不平衡的数据。
F1分数公式
F1分数定义为精确率和召回率的调和平均值。
简而言之,调和平均值是算术平均值的替代指标。它通常用于计算平均速率。
F1 分数公式如下所示:
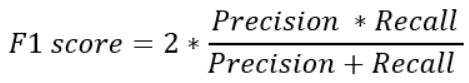
由于F1分数是精确率和召回率的平均值,这意味着它对精确率和召回率的权重相同:
- 如果精确率和召回率都很高,模型将获得较高的F1分数
- 如果精确率和召回率都较低,模型将获得较低的F1分数
- 如果精确率和召回率中的一个低而另一个高,则模型将获得中等F1分数
F1分数可以取代其他指标吗?
在整篇文章中有许多定义。在使用Python实现F1分数之前,我们总结一下何时使用F1分数以及如何将其与其他指标进行基准测试。
准确率vs精确率和召回率
准确率是最简单的分类指标。它只是评估机器学习模型做出正确预测的百分比。在数据不平衡的情况下,准确率无法区分特定类型的错误(FP和PN)。
精确率和召回率是更适合数据不平衡时的评估指标,它们考虑模型预测过程中的错误类型(FP和PN)。
- F1 分数vs精确率和召回率
- F1 分数将精确率和召回率组合成一个指标。在许多情况下,例如自动基准测试或网格搜索,只使用一个评估指标比使用多个要方便得多。
你应该使用F1分数吗?
总之,你应该为每个模型查看多个指标。每个指标都有优缺点,并为你提供模型相关优缺点的具体信息。
真正的选择困难是在进行自动化模型训练或使用网格搜索优化模型。在这些情况下,你必须指定要优化的指标。
我的建议是仔细研究一个或几个模型的多个不同指标。当你了解对特定用例的影响时,你可以选择一个指标进行优化或调整。
如果你将模型投入生产以供长期使用,则应定期进行模型维护并验证模型是否正常运行。
Python中的F1分数
现在让我们看一个例子来了解F1分数的意义。我们将使用一个示例数据集,其中包含许多网站访问者的数据。
目标是建立一个简单的分类模型,该模型使用四个自变量来预测访问者是否会购买某物。我们将看到如何使用不同的指标,我们将看到不同的指标如何给我们不同的结论。
本文使用相同的数据集,建议使用SMOTE采样技术来提高模型性能。
这里不会使用SMOTE,因为我们的目标是演示F1分数。但如果你对处理不平衡数据感兴趣,那么将这两种方法结合起来绝对是值得的。
数据
你可以直接从GitHub将数据导入Python 。以下代码允许你直接读取原始文件:
import pandas as pd
data = pd.read_csv('https://raw.githubusercontent.com/JoosKorstanje/datasets/main/sales_data.csv')
data.head()结果如下所示:
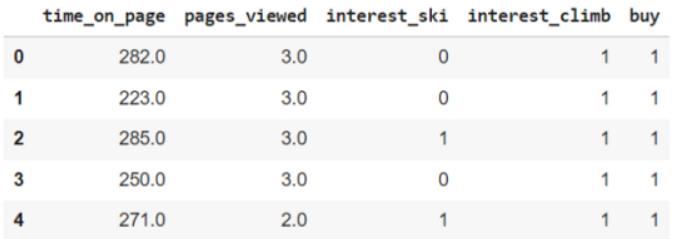
在这个数据集中,我们有以下五个变量
- buy:兴趣告诉我们访问者是否购买了我们山地运动的新产品。
- time_on_page:访问者在页面上花费的时间
- pages_viewed:访问者浏览过的网站页数
- interest_ski:来自客户关系数据库,它告诉我们访问者之前是否购买过任何与滑雪相关的物品。
- interest_climb:来自客户关系数据库,它告诉我们访问者之前是否购买过任何与登山相关的物品。
验证不平衡数据
在数据集中少部分买家。如果需要,可以使用以下代码验证这一点:
data.pivot_table(index='buy', aggfunc='size').plot(kind='bar', title = 'Class distribution')你将获得以下条形图:
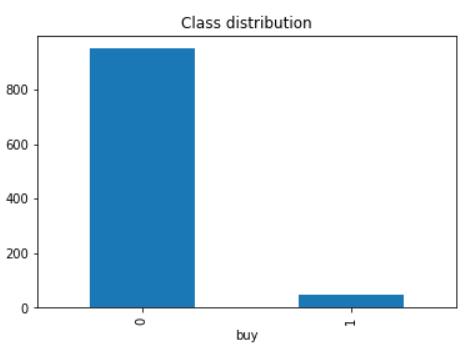
可以看到与其他访客相比,买家很少。在电子商务以及其他行业(如欺诈检测等)构建模型时,这种情况经常发生。这证实了F1分数可能会派上用场。
训练集测试集分层抽样
在构建模型之前拆分训练/测试集。如果你不熟悉机器学习中的训练/测试方法,我建议你先查看这篇文章。
但存在严重的数据不平衡时,进行随机训练/测试集拆分是有风险的。由于正样本的数量非常少,你可能会得到具有差异很大的数据分布的训练集和测试集。你甚至可能在测试集中得到接近零的正样本。
分层抽样是一种抽样方法,可避免干扰样本中的数据平衡。它允许你生成与原始数据具有完全相同的类平衡的训练集和测试集。你可以使用以下代码在 scikit-learn中执行训练/测试的分层抽样:
from sklearn.model_selection import train_test_split
train, test = train_test_split(data, test_size = 0.3, stratify=data.buy)如果需要,你可以使用与之前相同的代码来生成显示类分布的条形图。它可以验证总数据中的类分布与训练集和测试集中的类分布完全相同。
基准模型
作为基准模型可能会创建一个效果很差的模型,它会生成一个全部为0的预测列表,没有人会购买任何东西。你可以按如下方式执行此操作:
# this very bad model predicts that nobody ever buys anything
preds = [0] * len(test)虽然这个模型效果很差,但我们仍会找出它的准确率。你可以按如下方式使用scikit-learn的准确率方法:
from sklearn.metrics import accuracy_score
accuracy_score(test.buy, preds)这个模型的准确率非常高:95%!如果你从头看这篇,你可能会理解为什么。在测试数据中,我们知道买家很少。模型预测没有人会购买任何东西。因此,对买家来说(数据集的5%)是错误的。
这就是我们担心召回率和精确率的确切原因。让我们使用下面的代码来计算模型的召回率和精确率:
from sklearn.metrics import precision_score, recall_score
print('Precision is: ', precision_score(test.buy, preds))
print('Recall is: ', recall_score(test.buy, preds))请记住,精确率会告诉你正确预测的买家占预测买家总数的百分比。在这个效果不佳的模型中,没有一个人被预测为买家,因此精度为0!
另一方面,召回率告诉你在所有实际买家中你能够找到的买家百分比。由于你的模型没有找到一个买家,召回率也是 0!
让我们使用下面的代码来看看F1分数是多少:
from sklearn.metrics import f1_score
print('F1 is: ', f1_score(test.buy, preds))结果并不奇怪。由于F1分数是准确率和召回率的调和平均值,因此F1分数也是0。
本例中的模型根本不是智能模型。然而,该示例表明,使用准确率作为不平衡数据集的评估指标是非常危险的,该模型实际上根本没有任何效果。在这个例子中,精确率、召回率和F1分数都被证明是更好的评估指标。
更好的模型
由于上一个示例中的模型非常简单,让我们用真实模型重做另一个示例。我们将在第二个示例中使用逻辑回归模型。用以下代码构建模型,看看会发生什么:
from sklearn.linear_model import LogisticRegression
# Instantiate the Logistic Regression with only default settings
my_log_reg = LogisticRegression()
# Fit the logistic regression on the independent variables of the train data with buy as dependent variable
my_log_reg.fit(train[['time_on_page', 'pages_viewed', 'interest_ski', 'interest_climb']], train['buy'])
# Make a prediction using our model on the test set
preds = my_log_reg.predict(test[['time_on_page', 'pages_viewed', 'interest_ski', 'interest_climb']])让我们详细检查预测结果。在二元分类(如示例中具有两个结果的分类)中,你可以使用混淆矩阵来区分四种类型的预测:
- 真阳性True positives(买家正确预测为买家)
- 假阳性False positives(非买家被错误地预测为买家)
- 真阴性True negatives(非买家被正确预测为非买家
- 假阴性False negatives(买家被错误地预测为非买家)
你可以在 scikit-learn中获取混淆矩阵,如下所示:
from sklearn.metrics import confusion_matrix
tn, fp, fn, tp = confusion_matrix(test['buy'], preds).ravel()
print('True negatives: ', tn, '\nFalse positives: ', fp, '\nFalse negatives: ', fn, '\nTrue Positives: ', tp)结果如下:
- 真阴性:280
- 假阳性:5
- 假阴性:10
- 真阳性:5
这个模型评估数据非常详细。准确率是最简单的评估指标,让我们看看这个例子的准确率是多少:
print('Accuracy is: ', accuracy_score(test.buy, preds))有趣的是,逻辑回归的准确率为95%:与我们效果不佳的基准模型完全相同!
让我们看看精确率和召回率:
print('Precision is: ', precision_score(test.buy, preds))
print('Recall is: ', recall_score(test.buy, preds))结果:
- 精确率为:0.5
- 召回率为:0.33
让我们也使用scikit-learn的F1分数:
print('F1 is: ', f1_score(test.buy, preds))获得的F1分数为 0.4。
哪个模型和指标更好?
所以准确率告诉我们逻辑回归与基准模型效果一样,但精确率和召回率告诉我们逻辑回归更好。我们尝试了解原因:
- 两个模型的错误总数相同。所以准确率是一样的。
- 第二个模型实际上能够找到(至少一些)正样本(买家),而第一个模型在数据中没有找到一个买家。因此,第二个模型的召回率更高(逻辑回归为0.33,而不是第一个模型的0)。
- 第一个模型没有找到任何买家,因此精确率自动为零。逻辑回归确实找到了一些买家,因此我们可以计算出精确率。精确率显示了有多少预测的买家实际上是正确的。最终是50%。
- F1分数是我们真正感兴趣的指标。该示例的目标是演示其对不平衡数据建模的意义。第一个模型的F1分数为0:我们对这个分数感到满意,因为它是一个效果非常差的模型。
- 第二个模型的F1分数为0.4。这表明第二个模型虽然远未达到完美水平,但至少比第一个模型有了很大的改进。这是我们无法使用准确率作为指标获得的有价值的信息,因为两个模型的准确率是相同的。
结论
在本文中,F1分数是模型评估指标。在处理不平衡数据集的分类模型时,F1分数特别重要。
你已经看到F1分数将精确率和召回率结合到一个指标中。这使得它易于在网格搜索或自动优化中使用。
希望这篇文章对你有用。感谢阅读,你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Joos Korstanje
翻译作者:明慧
美工编辑:过儿
校对审稿:过儿
原文链接:https://towardsdatascience.com/the-f1-score-bec2bbc38aa6





