
使用谷歌AI Open Images进行对象检测
你最后一次刷脸登录手机是什么时候?
或者使用Snapchat滤镜将一些花哨的狗耳朵放在脸上,将自拍照分享给朋友?你是否知道这些很酷的功能是通过一个神奇的神经网络实现的,它不仅可以识别出照片中有一张脸,还可以检测出耳朵的位置。从某种意义上说,你的手机可以“看到”你,它甚至可以知道你的样子!
帮助计算机“看到”的技术被称为“计算机视觉”。近年来,由于计算能力的爆炸使得深度学习模型更快且更可行,计算机视觉应用正变得越来越普遍。亚马逊、谷歌、特斯拉、Facebook和微软等许多公司都在大力投资这项技术及其应用。
计算机视觉任务
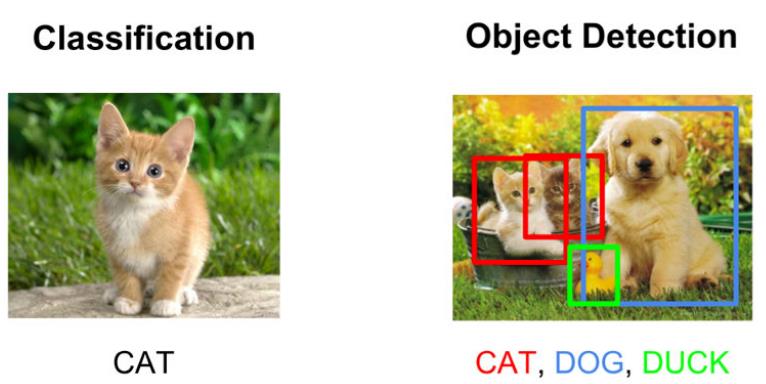
我们主要专注于两种计算机视觉任务 – 图像分类和对象检测。
- 图像分类侧重于将图像分组为预定义的类别。为了实现这一点,我们需要拥有我们感兴趣的类别的多个图像,并训练计算机将像素数转换为符号。这只是说计算机看到一张猫的照片,并说它里面有一只猫。
- 对象检测利用图像分类器来确定图像中存在的内容和位置。通过使用卷积神经网络(CNN),这些任务变得更容易,可以在一遍扫描图像的过程中检测多个类别。
计算机视觉很酷!
认识到未来许多有趣的数据科学应用程序将涉及处理图像,我的团队和我决定尝试参加托管在Kaggle上的Google AI Open Image挑战赛。我们认为这是一个极好的机会,亲自应用神经网络和卷积,并可能给我们的教授和同学留下深刻的印象。该挑战赛为我们提供了170万个图像,其中包含1200个对象类的1200万个边界框标注(它们相对于图像的X和Y坐标)。你可以在这里 (https://www.figure-eight.com/dataset/open-images-annotated-with-bounding-boxes/) 找到数据。
我们强烈建议任何想要了解有关CNN的人观看Andrew Ng关于卷积神经网络的Coursera课程 (https://www.coursera.org/learn/convolutional-neural-networks/home/welcome) 。
探索性数据分析 – 与所有数据分析一样,我们开始探索我们拥有的图像以及我们需要检测的对象类型。
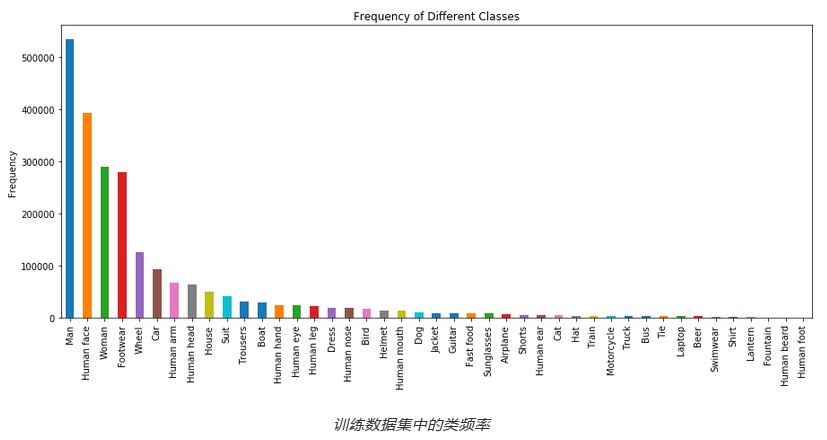
快速浏览一下训练图像,发现某些对象出现的次数比其他对象更多。上图显示了前43个类别的分布情况。很明显,存在巨大的差异,需要以某种方式解决。为了节省时间和金钱(GPU成本很高),我们选择了前面提到的43个对象类别,得到这些对象的大约300K张图像的子集。我们在训练数据中为每个对象类别提供了大约400个图像。
选择目标检测算法
我们考虑了各种算法,如VGG、Inception,但最终选择了YOLO算法,因为它的速度、计算能力和丰富的在线文章可以指导我们完成整个过程。面对计算和时间限制,我们做出了两个关键决定。
- 使用YOLO v2模型,预训练的模型可识别某些对象。
- 利用迁移学习训练最后一个卷积层,以识别以前看不见的对象,如吉他、房子、男人/女人、鸟等。
YOLO
算法需要一些给定的输入
- 输入图像大小 – YOLO网络设计上用于处理特定的输入图像大小。我们发送了大小为608 * 608的图像。
- 类别数 – 43,这是定义YOLO输出的维度所必需的。
- 锚点框 – 要使用的锚点框的数量和尺寸。
- 置信度和IoU阈值 – 用于定义要选择的锚点框以及如何在锚点框之间进行选择的阈值。
- 带有边界框信息的图像名称 – 对于每个图像,我们需要以特定格式为YOLO提供其中的内容,如下所示

以下是YOLO输入的代码片段

YOLO v2架构
其结构如下所示,它有23个卷积层,每个层都有自己的批处理标准化、泄漏RELU激活和最大池。
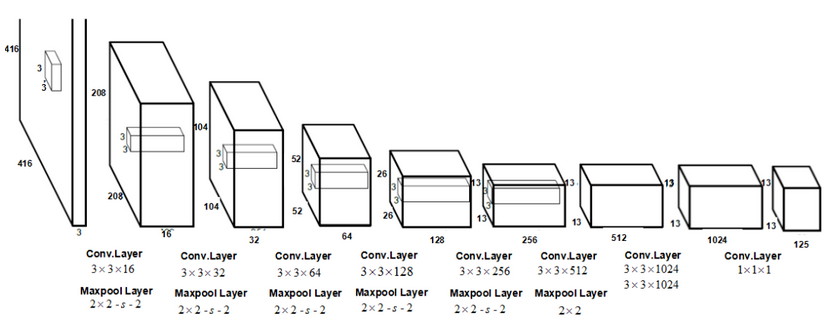
这些层尝试从图像中提取多个重要特征,以便可以检测各种类别。出于对象检测的目的,YOLO算法将输入图像划分为19 * 19网格,每个网格具有5个不同的锚点框。然后,它尝试检测每个网格单元中的类别,并将对象分配给每个网格单元的5个锚点框之一。锚点框的形状不同,旨在为每个网格单元捕获不同形状的对象。
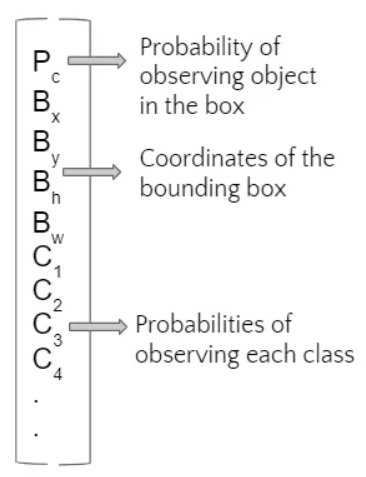
YOLO算法为每个定义的锚点框输出一个矩阵(如下所示)
鉴于我们训练43个类别的算法,我们得到的输出尺寸为:
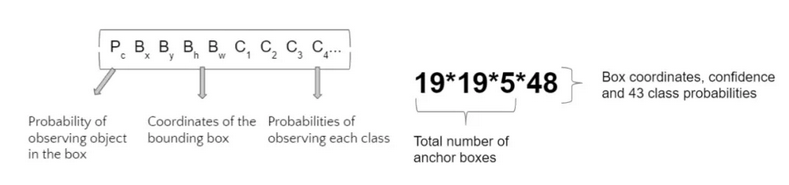
这些矩阵为我们提供了观察每个锚点框的对象的概率,以及该对象所属类别的概率。要过滤掉不属于任何类别或具有与其他框相同的对象的锚点框,我们使用两个阈值 – IoU阈值过滤掉捕获相同对象的锚点框和置信度阈值以过滤掉大概率不包含任何类别的框。
下面是YOLO v2架构最后几层的说明:

迁移学习
迁移学习的想法是获得已经训练过对图像进行分类的神经网络,并将其用于我们的特定目的。这节省了我们的计算时间,因为我们不需要训练大量的权重 – 例如,我们使用的YOLO v2模型有大约5000万个权重 – – 在我们使用的Google云实例上训练,可能需要4-5天才能完成。
为了成功实现迁移学习,我们需要对我们的模型进行一些更新:
- 输入图像大小 – 我们下载的模型使用大小为416 *416的输入图像。由于我们训练的一些对象非常小 – 鸟类,鞋类 – 我们不想那么大幅地压缩输入图像。出于这个原因,我们使用了大小为608 * 608的输入图像。
- 网格大小 – 我们更改了网格大小的维度,以便将图像划分为19 *19网格单元而不是13 *13,这是我们下载的模型的默认值。
- 输出层 – 由于我们训练的是不同类别数量:43,而原始模型训练的类别数为80,因此将输出层修改为输出矩阵,如上所述。
我们重新初始化了YOLO最后一个卷积层的权重,以便在我们的数据集上训练它,最终帮助我们识别出特定的类别。
以下是对应的代码片段

代价函数
在任何对象检测问题中,我们希望在图像中具有高置信度的正确位置识别正确的对象。成本函数有三个主要组成部分:
1. 类别损失:如果检测到对象,则为类别条件概率的平方误差。因此,只有当网格单元中存在对象时,损失函数才会惩罚分类错误。
2. 局部化损失:如果框负责检测对象,则是预测边界框位置和大小与真正实况框的平方误差。为了惩罚边界框坐标预测的损失,我们使用正则化参数(ƛcoord)。此外,为了确保较大框中的小偏差小于较小框中的小偏差,算法使用边界框宽度和高度的平方根。
3. 置信度损失:它是边界框置信度得分的平方误差。大多数框不负责检测物体,因此方程式分为两部分,一部分用于检测对象的框,另一部分用于其余的框。正则化项术语λnoobj(默认值:0.5)应用于后一部分以权衡未检测到对象的框。
请随时参考原始的YOlO论文,详细了解代价函数。
YOLO的优点在于它使用了易于用优化函数优化的误差,例如随机梯度下降(SGD)、带动量的SGD或Adam等。下面的代码片段展示了我们用于优化代价函数的参数。

输出精度 – 平均精确度(mAP分数):
在对象检测中评估模型有许多度量标准,对于我们的项目,我们决定使用mAP分数,即所有IoU阈值下不同召回(recall)值的最大精度的平均值。为了理解mAP,我们将快速回顾精度、召回和IoU。
精度和召回
精确度衡量正确预测的百分比。召回是所有可能结果中真正确性的比例。这两个值是反向相关的,也取决于我们为模型设置的模型得分阈值(在我们的例子中,它是置信度得分)。他们的数学定义如下:

联合上的交集(IoU)
IoU测量两个区域之间有多少重叠,这等于并集区域上的重叠区域。这可以衡量预测(来自对象探测器)与真实情况(真实对象边界)的对比情况。总而言之,mAP分数是所有IoU阈值的平均AP。
结论

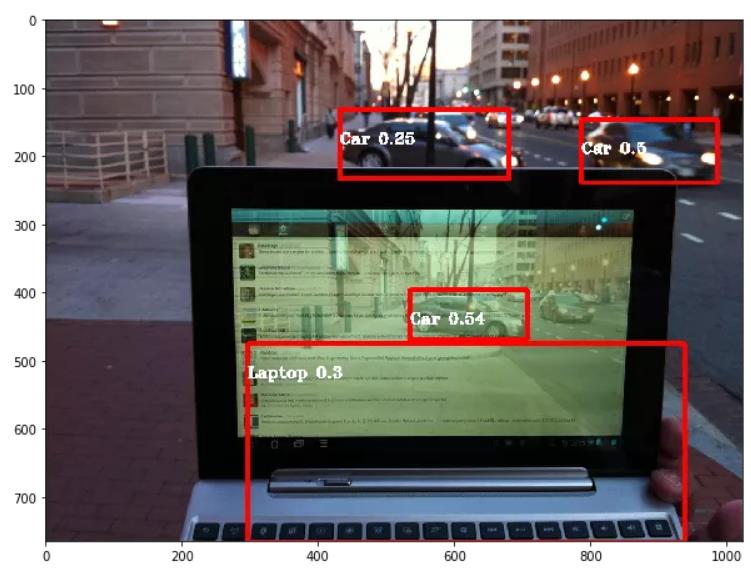


对象检测与其他计算机视觉任务不同。你可以使用预先训练的模型并根据需要进行编辑以满足你的需求。你将需要GCP或其他允许更高计算能力的平台。数学很难,读别人的文章会很快放弃。
得到的教训
最初,我们发现该模型无法预测许多类别,因为其中许多类别只有少量训练图像,这导致了不平衡的训练数据集。因此,我们决定只使用最多的43个类别,这不是一个完美的方法,但每个类别至少有500个图像。然而,我们预测的置信度仍然很低。为了解决这个问题,我们选择了包含目标类别的图像。
对象检测是一个非常具有挑战性的主题,但不要害怕并尝试尽可能多地从各种在线资源中学习,如Coursera、YouTube教学视频、GitHub和Medium。所有这些公开知识可以帮助你在这个激动人心的领域取得成功!
未来的工作 – 持续或改进
在更多类别上训练模型以检测更多种类的对象。要实现这一目标,我们首先需要解决数据不平衡的问题。一个可能的解决方案是我们可以为这些少数类别收集更多图像。
- 数据增强 – 稍微修改现有图像以创建新的图像
- 图像复制 – 我们可以多次使用相同的图像来训练特定稀有类别的算法
- 组合 – 在多数类别上训练一个模型,为少数的类别训练另一个模型并使用两者的预测。
此外,我们可以尝试组合不同的模型,例如MobileNet、VGG等,它们也是用于对象检测的卷积神经网络算法。
如果你想详细了解我们团队的代码,请参阅GitHub链接。请随时提供任何反馈或意见!
https://github.com/bandiatindra/Object-Detection-Project
原文作者:Atindra Bandi
翻译作者:Tony Yan Wang
美工编辑:过儿
校对审稿:Dongdong
原文链接:https://towardsdatascience.com/object-detection-using-google-ai-open-images-4c908cad4a54




