
年收入$500和$225,000的数据科学家之间有什么区别?
数据科学是一个日益流行的话题。随着这个行业越来越受欢迎,数据科学家的收入差距也越来越大。那这种差异的根源是什么?
在本文中,我们一起来探索数据科学中高收入的重要特征。如果你想了解更多数据分析相关内容,可以阅读以下这些文章:
5个鲜为人知的 Python 库!帮你的下一个NLP项目起航
从Marplotlib到Plotly: 教你入门Python数据可视化
如何征服数据科学面试中的Python编程考试
如何编写出优秀的 Python Class
该数据集是来自Kaggle的数据集,整理了2019年有关数据科学和机器学习的调查数据。这项调查在 10 月进行了三周,并收集了 19,717 条回复。本文分为 3 个部分,分别是数据清洗、数据分析和分析结果。
数据清洗
这里的主要目标是找到不同薪资的数据科学家。因此,我们删除了“学生”或“未就业”的行。
df = pd.read_csv("../input/kaggle-survey-2019/multiple_choice_responses.csv", low_memory = False)
df = df[~df['Q5'].isin(["Student", "Not employed"])]接着,我们将查看视觉信息的数据分布。
cols = ['Q1', 'Q2', 'Q3', 'Q4', 'Q5', 'Q10']
plot_distirubution(df, cols)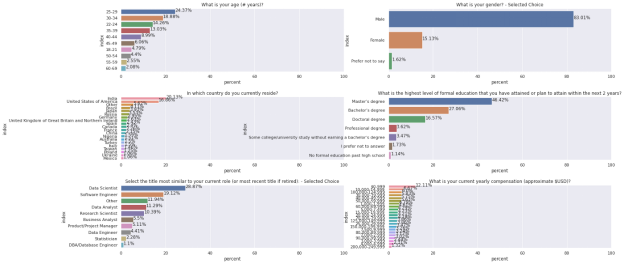
数据分析
我们使用的数据中,compensation_num的类型是一个字符串。因此,首先我们要清理数据,将字符串数据转换为整数数据。然后我们将薪酬数据分成 3 组,并把这列命名为“ commentation_num_group ”。这个列代表了 3 种不同的收入;低、中、高。
df['compensation_num'] = df['Q10'].str.replace('$', '')
df['compensation_num'] = df['compensation_num'].str.replace(',', '')
df['compensation_num'] = df['compensation_num'].str.replace('> 500000', '600000')
quenstion_dict = {}
for index, value in enumerate(df.loc[0, :]):
quenstion_dict[df.columns[index]] = value
df['low_compensation_num'] = df.loc[1:, 'compensation_num'].str.split('-').str[0]
df['high_compensation_num'] = df.loc[1:, 'compensation_num'].str.split('-').str[1]
df['low_compensation_num'] = df['low_compensation_num'].fillna(-1)
df['high_compensation_num'] = df['high_compensation_num'].fillna(-1)
df['low_compensation_num'] = df['low_compensation_num'].astype(int)
df['high_compensation_num'] = df['high_compensation_num'].astype(int)
df['compensation_num'] = (df['low_compensation_num'] + df['high_compensation_num']) / 2
df = df[df['compensation_num'] != -1]
df = df.drop(['low_compensation_num', 'high_compensation_num'], 1)
df['compensation_num_group'] = pd.qcut(df['compensation_num'], 3, labels=["low", "medium", "high"])接下来,我们用categorical_distribution_diff函数,计算高收入和低收入差异,并根据分类分布的得分绘制图表。第一张图绘制会最重要的列,最后一张图绘制最不重要的列。
questions = group_cols(df)
score_cols = find_distribution_diff(df, questions, 'compensation_num_group')
sns.set(font_scale=1.2)
plot_salary(df, score_cols, quenstion_dict, target='compensation_num_group', country='all')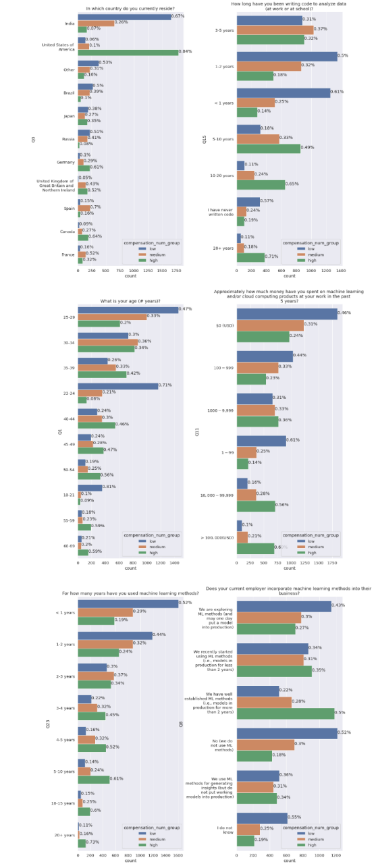
plot_parallel_categories_salary(df, country='all')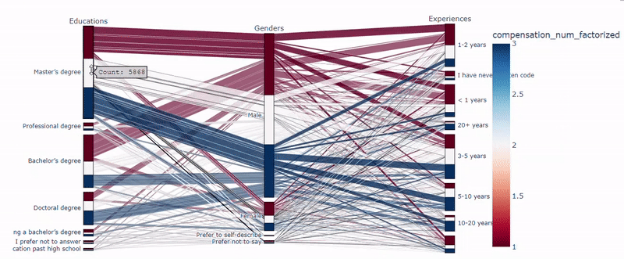
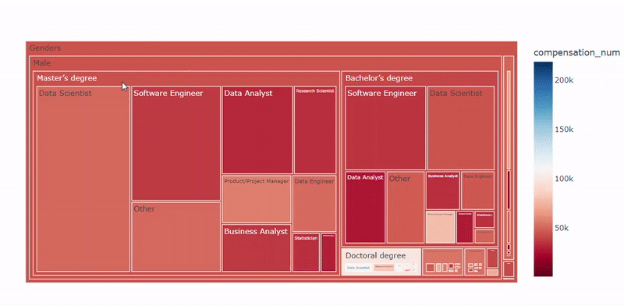
plot_treemap_salary(df, target='compensation_num_group', country='all')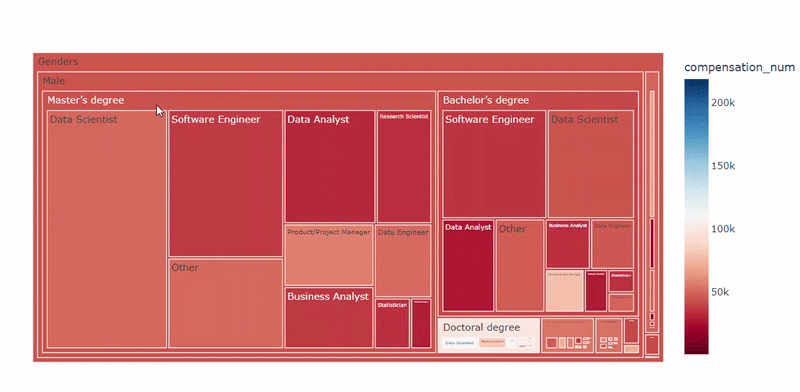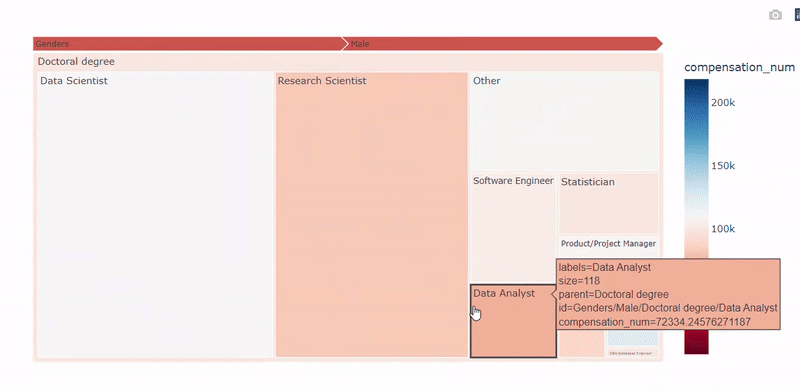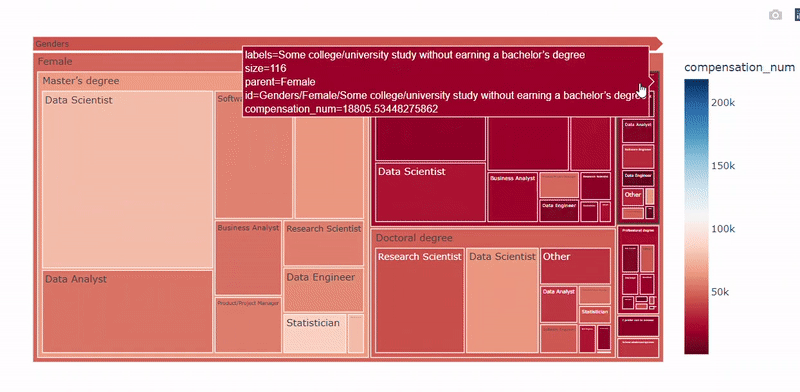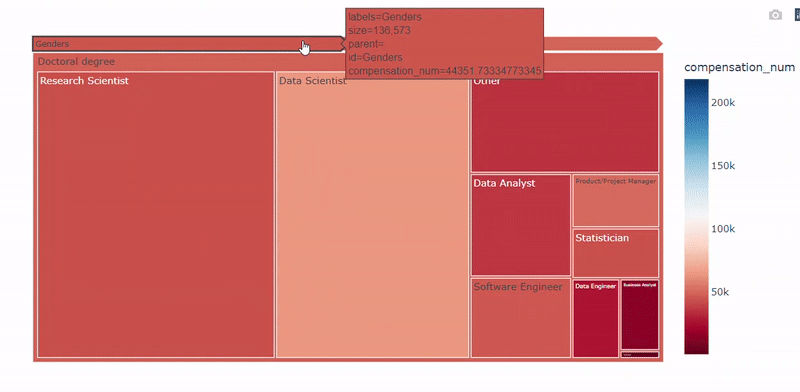
性别-教育-职称树图 — 图片作者
plot_point_salary(df, target='compensation_num_group', country='all')
分析结果
按照顺序,国家是最影响薪资高低的特征。美国、德国和加拿大是数据科学家最高薪国家。
第二个重要特征是经验。数据显示,一个经验丰富的数据科学家需要5年数据分析经验,和3-4年在机器学习经验。年龄和经验有着相同的特征,它们都直接/间接代表了工作经验。
在机器学习上的花销是第三个重要特征。如果有人在机器学习上花费超过了1000美元,那么他可以获得比其他数据科学家更多的薪水。但这个发现中有趣的是,很多数据科学家的薪水很高,但没有在机器学习上花钱。这向我们展示了免费资源的重要性。
第四个重要特征是数据科学家工作的公司的属性。如果公司有2年以上的机器学习模型产品,20人专门负责数据科学,10000多名员工,那公司给数据科学家的薪水就会很高。
数据科学家的岗位和教育程度也很重要。拥有产品/项目经理职位和博士或硕士学位的数据科学家更会获得高薪。这些特征也与经验特征息息相关,因为成为产品/项目经理,并拥有博士学位或硕士学位需要更多时间。
编程语言和数据库也是数据科学的重要特征。最常见的编程语言是 python,但SQL对薪资高低的影响更明显,数据库相关技术通常都是高薪的重要指标。根据这个结果,我们可以大胆地说——“所有优秀的数据科学家都必须了解数据库”。
机器学习模型被广泛用于决策。最重要的机器学习模型是Xgboost。这个模型也是 Kaggle 中最常见的 ML模型。
云计算和数据分析工具也是影响薪资的重要技能。数据结果显示,AWS是数据科学最重要的工具。
总结
本次分析直接针对了所有国家/地区进行,但分析可以根据国家/地区改变。如果你对本国高薪与数据科学人才之间的关系感兴趣,可以更改 plot_salary 中的 country 变量,并进行更多的探索和发现。感谢你的阅读。
原文作者:Hasan Basri Akçay
翻译作者:Jiawei Tong
美工编辑:过儿
校对审稿:Jiawei Tong
原文链接:https://medium.com/databulls/what-are-the-differences-between-data-scientists-that-earn-500-and-225-000-yearly-ea60ccdf03d7





