
除了预测姨妈周期,时间序列还能干嘛?
数据应用学院每周末都会为大家奉上
最高质量有价值的公开课程,
我们不收取任何费用;
为了让更多的人了解数据领域真正需要的是什么,
为了让想要学习数据的同学们可以勇敢地迈出第一步,
为了让已经在领域里驰骋的朋友们实时了解
行业里最热门最新潮的知识!
欢迎大家访问我们的公开课主页面了解每周公开课

欢迎大家访问我们的Youtube看你错过的公开课录播

一. 时序预测简介
可能大家一听到时序预测,脑海中首先浮现的就只有股价预测。其实不然,在工业界,但凡涉及到销售目标、财务计划、库存管理、物流管理、动态定价和市场营销等方面,都需要进行时序预测。
时序预测也已经渗透到了不同的领域:
金融领域:GDP,各种金融 / 财务因子
互联网:广告点击,流量监测
市场营销:销售,促销活动
工业:电力负载,生产线异常检测
生物医药:心电图
关于时序预测的预测区间,通常有如下的分类。
预测区间:
短期预测:排班,安排生产和运输
(例:每半个小时预测)
中期预测:资源安排,采购原材料/新设备,安排招聘(例:每个月/季度)
长期预测:战略规划。基于环境市场以及内部能力规划(例:每年)
时序预测通用模型就如下图所示,在当前时间之后的T时间内的预测值,可以通过一个与过去的观测值和外部的环境变量相关的函数计算出来。

二. 传统时序模型
下图是一个记录了澳大利亚历年游客数量的曲线。由图中可以看出,数据逐年上升,且年内有季节性变化,振幅逐年上升。要预测接下来几年的数据,有以下这些传统时序模型可以选择。图中绿色部分是实际值,红色部分是预测值。
简单平均模型
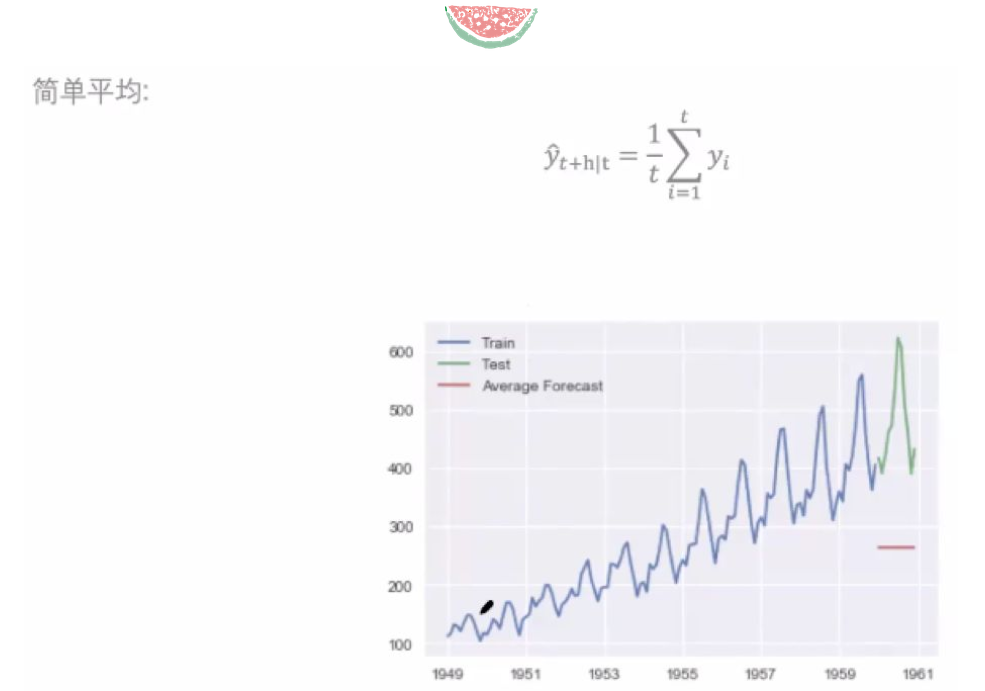
简单平均模型,顾名思义,就是把历年观测值平均,得到预测值。很显然,它的预测值偏低,因为没有考虑到逐年上升的趋势。
滑动平均模型
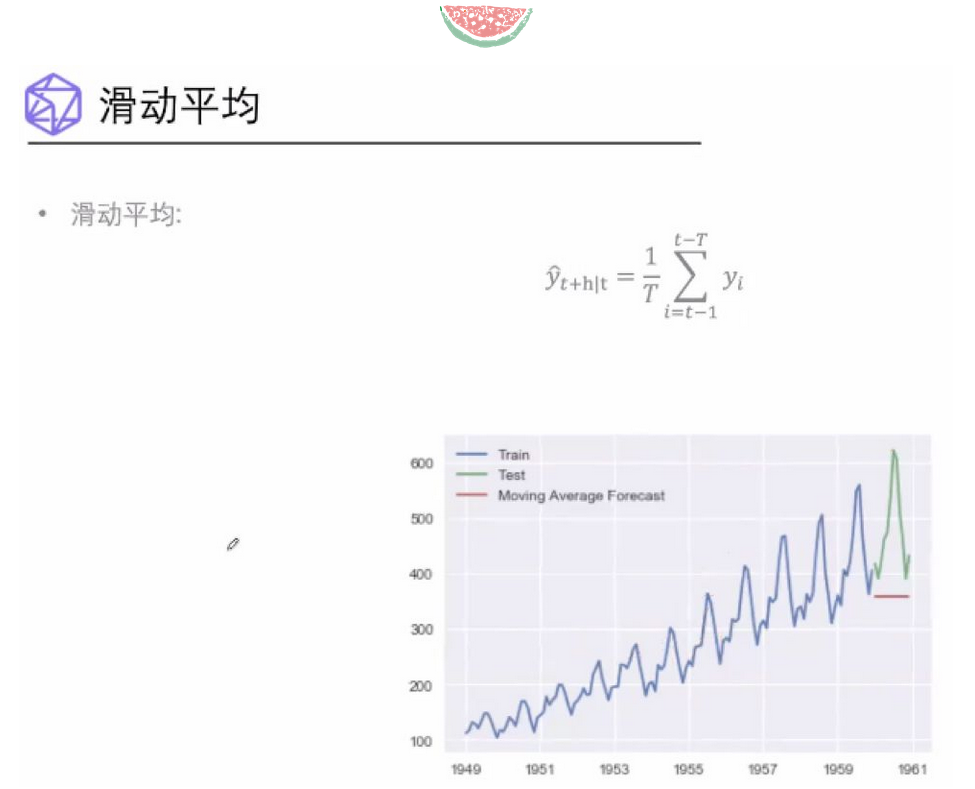
滑动平均和简单平均的区别就是,它不选择所有观测值进行平均,只选择过去几年内的观测值进行平均,所以会离实际值更接近一些。
指数平均模型
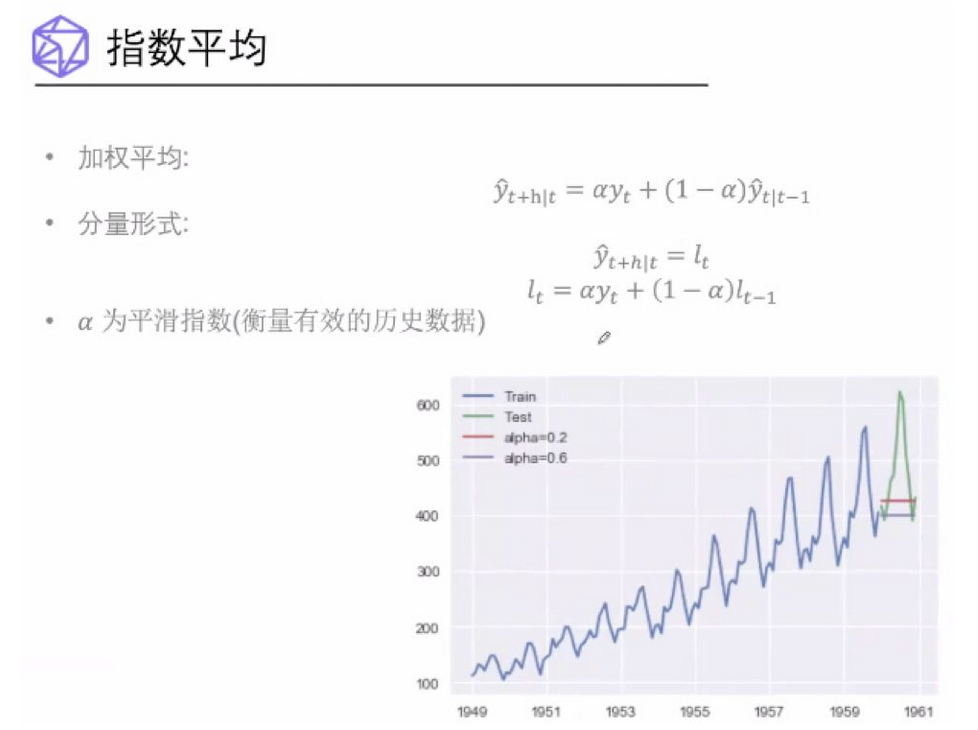
指数平均模型就比前面两种更合情理了。它的思想是离预测值越近的值,对预测值越有参考价值,反之则越没有参考意义。所以,对过去的观测值进行了加权平均。可以看到,预测值和真实值更接近了。
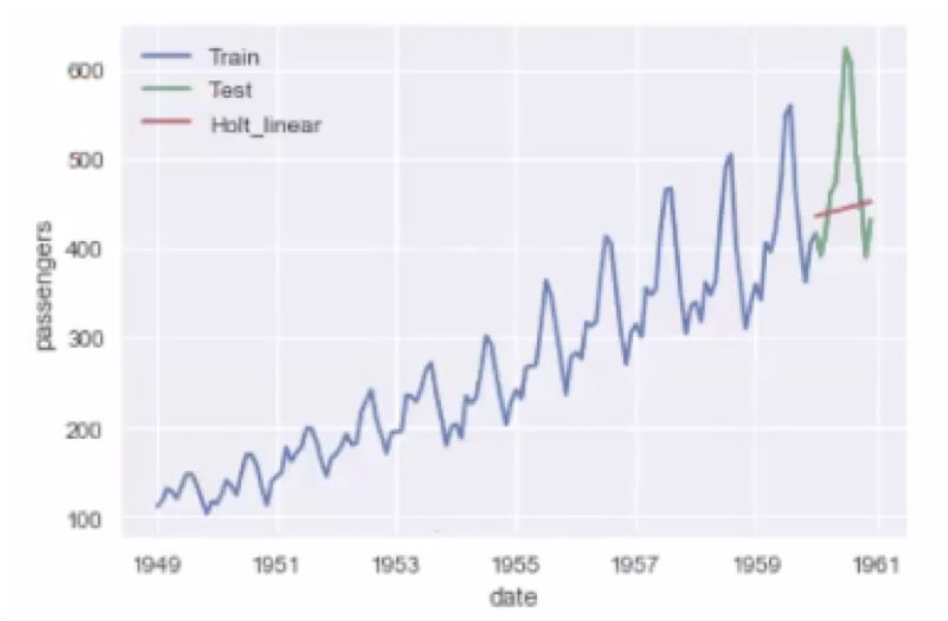
Holt 线性趋势模型

所谓 Holt 线性趋势模型,就是在指数平均模型的基础上,加上一个线性的趋势,就是图中的 hbt。Lt就是指数平均得到的结果,h 是预测的步数,bt 是上升的斜率,也是通过加权平均的方式求得(离预测值越近的两点之间的斜率,越有参考价值)。
预测结果如下图所示,我们得偿所愿,为预测值添加了上升趋势。
自回归积分滑动平均模型

自回归积分滑动平均模型是传统时序预测模型的另一大类,它认为预测值和过去值有直接的线性关系,并假设满足一个有 p 个 feature 的线性回归模型。如果这么考虑,其实是默认各个过去值之间没有相关性,但事实不是这样,所以要通过 q 阶的滑动平均把这其中的相关性去掉。其次,还要使用差分的方法,抹掉其季节性趋势,在预测的时候,再将它添加回来。
那么,总结一下传统时序模型的优缺点:
*** 优点
# 线性模型,易于理解
# 只依赖于历史数据
# 参数较少,参数的含义明确
*** 缺点
# 很难加入其它特征(价格,产品描述,产品类别)
# 很难考虑序列间的关联
# 很难应用于多个序列(百万产品)
# 需要人为预缺失值处理
# 需要对每个序列进行统计分析来确定拟合参数。
三. 机器学习
关于时序预测的机器学习模型的选择,现在已经不是什么大问题,树模型(XGBoost, Lightgbm)已经是大家的普遍选择。
特征工程也是时序预测的重要组成部分,常见的需要做的特征工程有:手工加入季节性特征、趋势、滞后特征、类别编码和目标编码等。
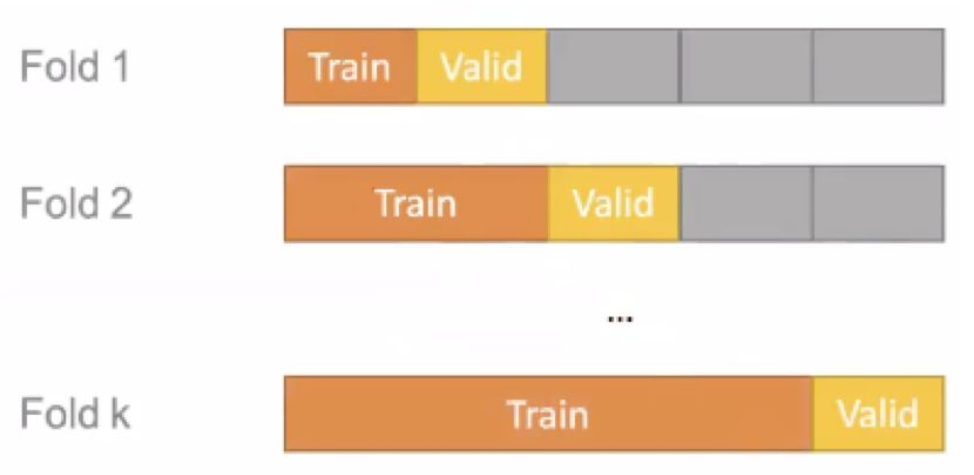
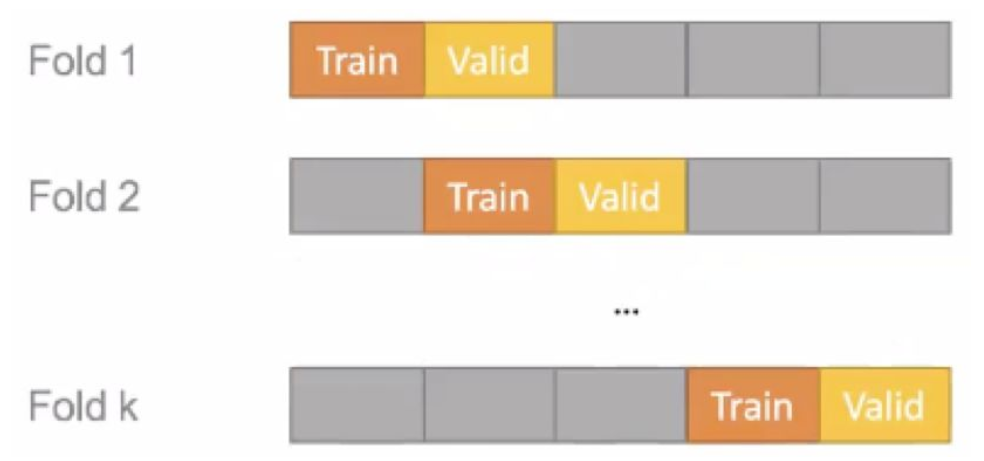
老师重点强调了做时序预测时 cross validation 和普通机器学习的区别。做时序预测,因为数据的产生有先后次序,不可以随便选择一部分数据进行 train,另一部分进行 validation。所以,一定要选择老数据进行 training,新数据进行 validation,有如下图所示两种方法。其中第二种方法适用于数据量比较大的时候,当对 fold1 validation 后,舍弃前面的数据,对后面的数据进行 cross validation。
方法一
方法二
是不是觉得干货满满!





