
为什么你需要用小型语言模型
“越大越好”——这一原则在人工智能领域根深蒂固。每个月,参数数量不断增加的更大模型被研发出来。公司甚至投资数十亿美元建造人工智能数据中心。但这是唯一的方向吗?
在NeurIPS 2024 大会上,OpenAI 的联合创始人之一 Ilya Sutskever 提出了一个引人深思的观点:“我们所知的预训练毫无疑问会结束。”缩放时代似乎即将终结,这表明是时候聚焦于改进现有方法与算法了。
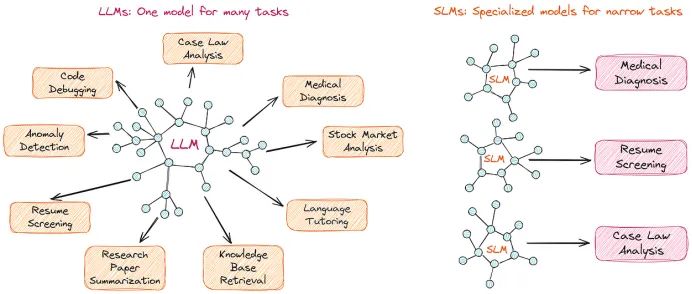
其中一个最有前景的领域是使用参数数量多达 10B 的小型语言模型(SLM)。这种方法已经在行业内逐渐流行。例如,Hugging Face 的首席执行官 Clem Delangue 预测,多达 99% 的用例 可以通过 SLM 解决。类似趋势也出现在 Y Combinator 最近对初创公司的指导方针中:
“具有海量参数的大型通用模型令人印象深刻,但它们既昂贵,又常常伴随着延迟和隐私方面的挑战。”

在本文中,我将阐述为什么小型语言模型可能正是您的企业所需的解决方案。我们将探讨它们如何帮助降低成本、提高准确性并增强对数据的掌控。当然,我们也会诚实地讨论它们的局限性。如果你想了解更多关于LLM的相关内容,可以阅读以下这些文章:
大语言模型:AI如何改变医疗现状
为什么大语言模型不适合编码?
AI驱动的财务分析:多代理LLM系统将数据转化为见解
2024年打造生产级LLM应用的最佳技术栈
成本效益
LLM 的经济学是企业最常面对的挑战之一。然而,问题远不止于此:它涉及昂贵的硬件、基础设施、能源成本以及环境影响。
诚然,LLM 的能力令人印象深刻,但维护它们的代价同样高昂。您可能已经注意到,基于 LLM 的应用订阅价格不断上涨。例如,OpenAI 最近宣布的每月 200 美元 Pro 计划 就是一个明显的信号,预示着成本在进一步攀升。竞争对手也很可能将价格调整至类似水平。
真实案例:Moxie 机器人
Embodied 公司开发了一款名为 Moxie 的儿童伴侣机器人,售价 800 美元,使用 OpenAI API。这款产品取得了成功(儿童每天发送 500-1000 条消息!),但由于 API 的高昂运营成本,公司最终不得不关闭项目。如今,成千上万的机器人无法再被使用,孩子们失去了他们的“朋友”。
小型模型的优势
一个可行的替代方案是微调针对特定领域的小型语言模型。尽管它不能解决“世界上所有的问题”,但却可以完美应对分配给它的特定任务。例如,分析客户文档或生成特定报告。同时,SLM 的维护更加经济,资源消耗更少,数据需求更低,且能够在普通硬件上运行(甚至可以在智能手机上执行)。
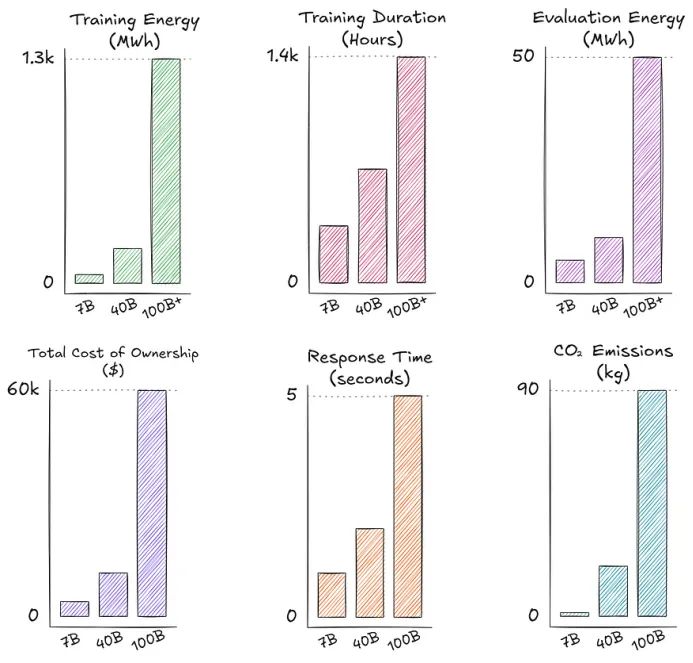
(来源:Source 1,Source 2,Source 3,Source 4)
此外,环境问题也不可忽视。《碳排放与大型神经网络训练》一文提供了一些令人震惊的数据:训练拥有 1750 亿参数的 GPT-3 所需的电量,相当于美国家庭 120 年的用电量;而它每年产生的二氧化碳排放量高达 502 吨,相当于 100 多辆汽油车的排放。而部署 7B 级别的小型模型所需的资源仅为其 5%。
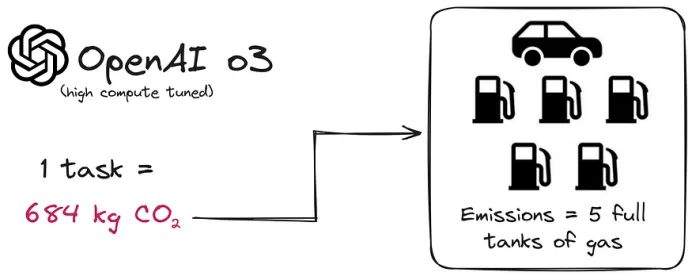
既然我们已经讨论了经济问题,让我们谈谈质量问题。当然,很少有人会为了节省成本而牺牲解决方案的准确性。但即使在这里,SLM也能提供一些东西。
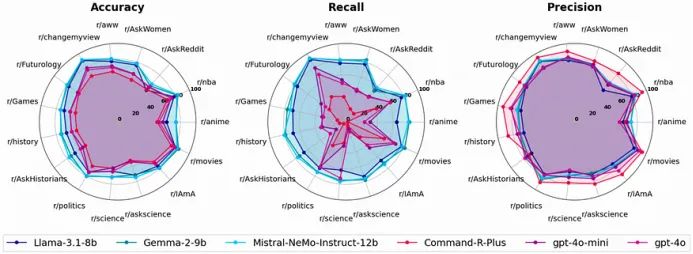
- 医学领域:Diabetes-7B 模型(基于 Qwen2-7B)在糖尿病相关测试中的准确率为 87.2%,显著高于 GPT-4 的 79.17% 和 Claude-3.5 的 80.13%。尽管如此,Diabetes-7B 的模型体积比 GPT-4 小几十倍,并且能够在消费级 GPU 上本地运行。
- 法律领域:一个仅有 0.2B 参数的 SLM 在合同分析中达到了 77.2% 的准确率(GPT-4 为 82.4%)。此外,在识别用户协议中的“不公平条款”任务中,SLM 在 F1 指标上甚至优于 GPT-3.5 和 GPT-4。
- 数学任务:DeepMind 的研究表明,训练小模型 Gemma2-9B(基于小模型生成的数据),在性能上优于在更大的 Gemma2-27B 上训练。这说明小型模型可以更加专注于细节,而不像大型模型常常试图“展示无关知识”。
- 内容审核:LLaMA 3.1 8B 在 15 个热门子reddits 中审核内容时,在准确性(+11.5%)和召回率(+25.7%)方面优于 GPT-3.5,即便经过 4 位量化后依然表现出色。
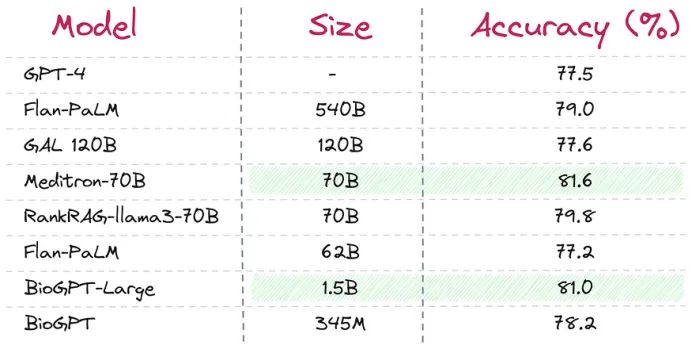
这些例子表明,对于高度专业化的任务,小型模型不仅可以与大型模型竞争,甚至经常表现得更好。
经典方法的潜力
有时候,经典的 NLP 方法表现甚至会出人意料地好。例如,在开发心理支持产品时,我们每天处理用户发来的上千条信息。这些信息会被分类为以下四类:
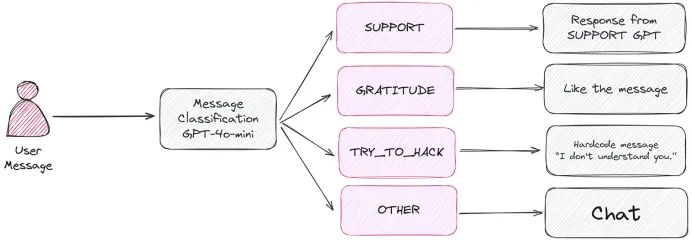
- 支持类:与应用程序功能相关的问答;通过文档生成响应。
- 感谢类:用户表达感谢;直接回复简单致谢。
- 尝试破解类:用户提出与应用目的无关的请求(如“用 Python 写个函数”)。
- 其他类:需要进一步处理的消息。
起初,我使用GPT-3.5 Turbo进行分类,但随后切换到GPT-4o mini,尽管提示优化后,错误仍时有发生。后来,我尝试了一种经典方法:TF-IDF + 简单分类器。模型训练时间不到一分钟,Macro F1 分数从 GPT-4o mini 的0.92提升至0.95。模型体积仅 76 MB,处理 200 万条消息后,成本从基于 GPT 的约500美元显著下降至几乎为零。

这类“小而简单”的任务在许多产品中并不少见。大型模型适合快速原型开发,特别是在需求动态变化且缺乏标注数据时;但对于定义明确、稳定的任务,专用小型模型和经典方法通常是更经济高效的解决方案。
提示:利用 LLM 进行快速原型设计,任务明确后切换到更小、更便宜、更准确的模型。这种混合方法既能保持高质量,又显著降低成本,同时避免通用模型带来的资源浪费。
安全、隐私与合规性
通过 API 使用 LLM 会将敏感数据暴露给第三方服务提供商,增加泄漏风险,并加剧合规性挑战(如 HIPAA、GDPR 和 CCPA)。此外,OpenAI 最近宣布可能引入广告,这进一步突显了这种风险:您的公司不仅失去了对数据的控制,还依赖第三方服务协议。
相比之下,小型语言模型(SLM)在安全和隐私方面的优势更加明显:
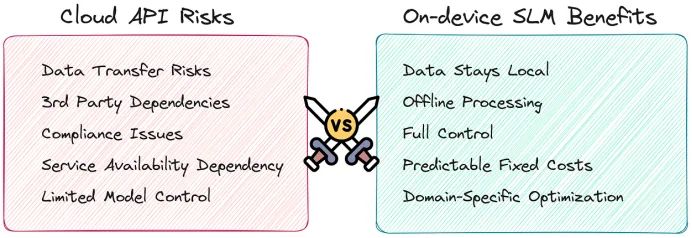
这就是“small guys”重新发挥作用的地方:
- 简化审计:SLM 的较小规模使审计、验证和定制更加便捷,可以更轻松地向审计员展示数据如何处理,并确保数据始终在受信环境中流转。
- 本地运行:由于 SLM 的计算需求较低,可以部署在从本地服务器到智能手机等各种设备上。据预测,到 2028 年,超过 9 亿部智能手机将能够运行生成式 AI 模型。
- 快速调整:法规频繁变化,小型模型能够在几小时内完成微调,而大型 LLM 通常需要耗费数天甚至数周。
- 分布式架构:SLM 支持分布式安全系统设计,例如:
- 隐私守护模型(2B):屏蔽个人信息。
- 医疗验证模型(3B):确保医疗建议准确性。
- 合规检查模型(1B):检测 HIPAA 合规性。
提示:在医疗、金融或法律等合规要求高的领域,优先考虑SLM解决方案。这将帮助企业降低监管成本,同时增强灵活性和数据安全性。

提示:如果您在监管严格的领域操作,请考虑使用slm。密切关注数据传输政策和监管环境变化的频率。如果您的专业领域是医疗保健、金融或法律,我建议您使用SLM。
AI代理:智能分工的新时代
经典的Unix哲学提到“只做一件事,并做好它”,如今AI技术似乎再次回归这一原则。
例如,假设您需要构建一个用于财务文档分析的系统,与其依赖单一大型模型,您可以将任务拆分为多个专门的 AI 代理:
- 预处理代理:负责 OCR 识别、格式转换和数据清理,确保输入一致性。
- 分类代理:根据内容将文档分类为发票、合同或财务报告等类型。
- 数据提取代理:提取发票中的关键字段(如金额、日期、供应商信息)。
- 验证代理:校验提取数据的准确性和一致性。
这种代理架构不仅提高了效率,还显著降低了开发和运行成本,是未来AI系统发展的重要方向。
提示:充分利用 SLM 的专长和灵活性,通过“多模型协作”应对复杂任务,将成为企业 AI 转型的新常态。
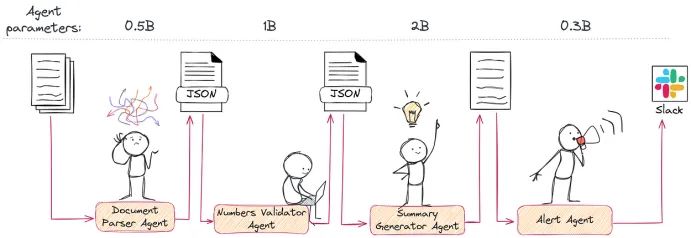
这种方法不仅更具成本效益,而且更可靠:每个代理专注于自己最擅长的任务。这意味着成本更低、速度更快、效果更好。是的,我又重复了一遍。
为了证明这一点,以下是几家公司成功应用专门模型的案例:
- H公司:在种子轮融资中获得了1亿美元,用于开发基于 SLM(2-3B 参数)的多智能体系统。他们的代理 Runner H(3B)的任务完成成功率为67%,而 Anthropic 的计算机使用成功率为52%,两者的计算成本显著降低。
- Liquid AI:最近获得了2.5亿美元融资,专注于构建高效的企业模型。他们的模型(1.3B 参数)在性能上优于所有现有的同规模模型。同时,他们的 LFM-3B 在内存需求更低的情况下,提供了与7B甚至13B模型相当的性能。
- Cohere:推出了 Command R7B,这是一个专为 RAG 应用设计的模型,甚至可以在 CPU 上运行。该模型支持23种语言,并集成外部工具,在推理和问答任务中展现了一流的表现。
您也可以将您的公司加入这个名单。例如,在我工作的 Reforma Health 公司,我们专注于为医疗行业开发专门的 SLM。之所以做出这样的决定,是因为医疗行业需要遵守 HIPAA 等法规,同时处理复杂的医疗数据。我们的经验表明,高度专业化的 SLM 在受监管行业中是一项重要的竞争优势。
专业化模型的市场趋势
这些案例突出了以下关键点:
- 投资者信任专业化小模型的未来。
- 企业客户愿意为高效且不依赖外部服务商的数据解决方案付费。
- 市场正在转向“智能”的专门代理,而非依赖“通用”的大型模型。
提示:在项目中首先确定那些重复性高的任务,这些任务最适合开发专门的 SLM 代理。这种方法不仅可以避免因 LLM 的超强通用性而导致的高成本,还可以实现对流程的更大控制。
SLM的潜在局限性
尽管本文一直强调小型模型的优势,但也有必要认识到它们的局限性:
1.任务灵活性有限
SLM 的一个显著局限是其狭窄的专门化。相比能够处理广泛任务的 LLM,SLM 仅在特定领域表现优异。例如,在医学领域,Diabetes-7B 模型在糖尿病相关测试中表现优于 LLM,但在其他医学学科中则可能需要额外微调或新架构支持。
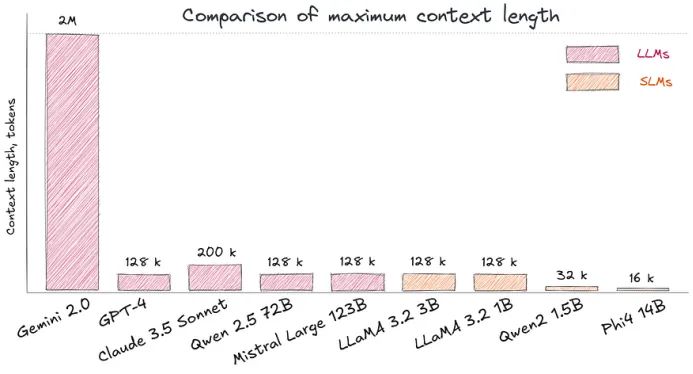
2.上下文信息窗口限制
与支持高达1M tokens 上下文的大型模型(如 Gemini 2.0)相比,SLM 的上下文长度通常更短。尽管最新的小型 LLaMA 3.2(3B, 1B)模型支持128k tokens,但实际有效上下文长度往往不如其标称值。SLM 在处理多年病史或大型法律文件时,可能无法有效捕捉完整背景信息。
3.应急能力不足
很多复杂能力只有在模型达到某种规模时才会显现。SLM 通常缺乏足够的参数数量,难以实现高级逻辑推理或深度上下文理解。例如,Google Research 的研究表明,在数学问题中,小模型在基本算术上表现平平,而大模型则展示出复杂数学推理能力。
然而,Hugging Face 的研究指出,通过测试时间计算扩展(如迭代自我改进),SLM 可以部分弥补这一不足。通过延长生成时间,小模型(1B 和 3B 参数)在 MATH-500 基准测试中的表现甚至超越了较大模型(8B 和 70B)。
提示:如果任务需要频繁变化的能力、处理大规模文档或解决复杂逻辑问题,大型 LLM 通常更通用、更可靠。
结语
如果您的任务需求频繁变化且缺乏明确专业化目标,LLM是快速启动的理想选择。然而,随着任务目标逐渐明确,转向更紧凑的SLM代理可以显著降低成本,提高准确性,并更轻松地符合法规要求。
SLM不是一种趋势性的范式转换,而是一种务实的解决方案。它允许您以更低成本、更高精度解决特定问题,而不为不必要的功能付出过高代价。您甚至无需完全放弃LLM,可以逐步用SLM替代部分组件。最终选择应基于任务的性质、预算和性能指标。
以IBM为例,该公司采用多模型策略,根据任务需求灵活组合不同模型。他们总结道:
“更大并不总是更好,低基础设施需求的专用模型往往优于通用模型。”
成功的关键在于适应性:从 LLM 开始,分析其最佳表现领域,然后优化架构,避免为多余功能支付高昂代价,同时保障数据隐私。这种方法将初期的 LLM 灵活性与成熟阶段的 SLM 性能优势相结合,最终为项目实现最佳价值。
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/。
原文作者:Sergei Savvov
翻译作者:过儿
美工编辑:过儿
校对审稿:Jason
原文链接:https://towardsdatascience.com/your-company-needs-small-language-models-d0a223e0b6d9





