
每个数据科学家都应该养成的15个好习惯
数据科学是对数据的研究,以提取有助于企业发展的有意义的见解。它结合了数学、统计学和编程的知识,以产生有助于做出商业决策的见解。
数据科学家是分析专家,他们负责收集、分析和解释数据,以帮助推动组织中的决策。他们利用自己的技术和社交技能来产生有用的见解。
十年前,研究人员Thomas H. Davenport和DJ Patil共同撰写了一篇文章,将数据科学称为“21世纪最性感的工作”。这篇文章得到了很多关注,十年后我们可以清楚地看到其中的原因。
在过去的5年里,对数据科学家的需求增长了很多,预计从2021年到2031年将增长36%。在印度时报上发表的一篇文章中,数据科学的市场资本将在2026年增长到3229亿美元。
技术人员和非技术人员都在尝试掌握数据科学技能。因此,数据科学工作的竞争已经增加了很多。如今,要想获得一份数据科学家的工作,你需要的不仅仅是顶级机构的认证。
在这篇文章中,我将分享一些每个数据科学家都应该采用的好习惯,这些习惯可以节省大量的时间和处理成本。如果你想了解更多关于数据科学的相关内容,可以阅读以下这些文章:
你的第一份数据科学工作中要避免的错误
0经验?一样能成为一名成功的数据科学顾问!
3步走方略——用Python为数据科学项目收集数据
担任数据科学经理的前半年,我学到了什么?
1 使用处理和可视化功能
函数是一段可以在计算机程序中反复使用的代码“块”。函数是编程的基础,但我仍然看到许多数据科学的新手没有在代码中使用它们。
如果你正在对原始训练数据应用某些处理步骤以使其为建模做好准备,则还需要在测试集上再次应用相同的步骤集。因此,我们可以创建一个全局函数,然后将训练集或测试集作为输入传递,而不是再次编写它们。
def process_data(data):
----
----
# processing steps
----
----
process_data(df_train)
process_data(df_test)可视化没什么不同。分析数据的第一步是统计列的类别。你可以创建一个像下面这样的函数,并在需要时使用它,而不是一遍又一遍地写代码。它会使你的笔记本变得干净易懂。
def plot_top_n(df,col,val):
top_n = df[col].value_counts().iloc[:val]
fig = px.bar(x=top_n.index,y=top_n.values,
labels={
'x':f'{col}',
'y':'Count'
})
return fig
plot_top_n(df,'Company',12) ## it will create a bar graph for top 12 companies2 在应用任何重大转换之前,对你的数据进行备份
在使用数据集时,有一个预防规则,即在应用任何重大转换之前,应该始终创建数据的副本,以防你搞砸了过程。
df_copy = df.copy()3 记录你的代码
你应该开始养成给代码写注释、标签、标题等的习惯。否则,一个月后当你回来的时候,你必须分析所有的代码才能正确地理解它。如果不是为了别人,就为未来的自己记录你的代码。
4 使用样本而不是头部和尾部
你遇到的每一门数据科学课程都会使用函数head()和tail()来预览数据。Head()函数返回前5行,而tail()返回后5行。根据上下行做一些假设是不好的,所以尝试使用sample(n)从数据中返回n个随机行。
df.sample(n) ## n = 1,2,3,4,5,6.....5 始终保存你清理过的CSV文件
在每个处理步骤之后保存清理过的CSV文件是一个好习惯,这样将来你就有一个路径可以回头重做所有的错误分析,而不用担心处理代码和执行时间。如果你需要使用一组不同的参数集重新训练你的模型,保存已清理的CSV也很有帮助。
import pandas as pd
pd.to_csv("Cleaned_DATA.csv")6 试着把你的分析分成不同的文件
在过去的两年里,我看到了大量的jupyter笔记本。我看到人们常犯的一个错误是把数据分析和机器学习建模放在同一个笔记本里。在一个较小的项目中,这不会造成问题,但当你在一个需要大量单元进行eda和特征工程的大项目中工作时,你应该将建模与分析分开。否则,在建模中出现一个错误,你就必须重新运行所有的单元格。你可以从三个独立的文件开始,一个用于数据分析,第二个用于建模,第三个用于模型测试和评估。

7 永远不要为回归输出一个特定的数字
自从streamlit推出以来,每个数据科学家都试图将他们的模型转换为web应用程序,以便其他人可以与之交互并测试它。Streamlit提供了一个功能,使创建web应用程序变得超级简单。大多数由streamlit创建的web应用程序接受文本、数字或图像形式的输入,并返回输出。在处理回归问题时,我们尝试创建一个可以预测特定数字的模型。对于建模来说,预测一个数字是可以的,但当涉及到在web应用程序上输出结果时,你永远不应该输出一个特定的数字,而是输出一个范围,使你的输出更易于解释。你可以看看下面的图片,自己决定你最喜欢哪一个,哪一个预测正确结果的概率更高。

8 始终尝试不同的评估矩阵
当你为自己购买电子设备时,你会考虑仅仅通过阅读一个用户或网站的评论来购买它吗?机器学习也是如此。你不应该依赖于一个单一的母体。你的模型准确率可能是90%,但在现实中,它会产生大量的假阳性结果。无论你在处理哪种类型的问题,总是尝试不同的评估矩阵,然后得出你的结论。

9 注意文本处理步骤
数据科学的新手常犯的一个错误之一是对不同的问题一次又一次地使用相同的文本处理步骤,而不知道它们的实际工作原理。有时,一个愚蠢的错误就可能导致有用数据的大量丢失或不需要的数据的大量增加。例如,如果你在删除电子邮件、url或HTML标记之前删除了所有非字母数字字符,那么你最终会得到大量不需要的数据。以代码块为例,想象一下,如果一行就能产生这么多不需要的数据,那么整个文档将产生多少呢?这就是为什么在将文本处理步骤应用于数据之前理解它们是一个很好的做法。
import regex as re
text = 'abhay@gmail.com has requested 2 burgers and 1 pepsi. Order from https://online.order.com'
print(re.sub('[^a-zA-Z\d\s]',"",text))
---------------
abhaygmailcom has requested 2 burgers and 1 pepsi Order from httpsonlineordercom
'''
abhaygmailcom , httpsonlineordercom -> unwanted data
'''10 跟踪你的模型参数
超参数调整是模型训练中最耗时的过程之一。我们从一些随机参数开始,希望我们的模型性能会有所提高。在每次迭代之后,都会生成一组新的参数。有时它们会提高性能,有时会降低性能。跟踪你的模型参数变得非常重要,这样就不会丢失最能提高性能的参数。最好的方法之一是使用自动参数跟踪器。我个人更喜欢CometML,因为它易于集成,只需两行代码就可以将笔记本电脑与它的服务器连接起来。
from comet_ml import Experiment
import tree from sklearn
# 1. Define a new experiment
experiment = Experiment(project_name="YOUR PROJECT")
# 2. Build your model and fit
clf = tree.DecisionTreeClassifier(
# ...configs
)
clf.fit(X_train_scaled, y_train)
params = {...}
metrics = {...}
# 3. Log additional metrics and params
experiment.log_parameters(params)
experiment.log_metrics(metrics)
# 4. Track model performance in Comet11 始终放置条形标签
Barplot是数据科学中最常用的可视化方法之一。它主要用于显示n个类别的n个计数。默认情况下,许多python可视化库不会在条形图上放置类别(条形标签)的计数。如果没有条形标签,条形图就是一些不同颜色的随机垂直矩形。你可以在下图中看到,通过添加条形标签,它变得多么有信息量。
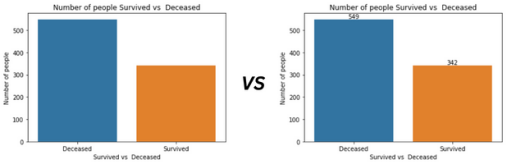
import matplotlib.pyplot as plt
import seaborn as sns
df_train = pd.read_csv ('titanic/train.csv')
ax = sns.countplot(data=df_train,x = 'Survived');
ax.bar_label(ax.containers[0]) ## Bar Label Code
plt.title("Number of people Survived vs Deceased")
plt.xlabel("Survived vs Deceased")
plt.ylabel("Number of people")
plt.xticks(ticks=[0,1],labels=['Deceased','Survived'])
plt.show();12 Mean()并不总是答案
数据有缺失值!
该列的数据类型为Integer!
只需要用它们的平均值来填充缺失的值即可。这是90%的新手数据科学家在不知道使用平均值来估算缺失值的原因的情况下采取的方法。只有当我们的数据服从正态分布或接近正态分布时,平均值才能用于imputation。在偏态分布的情况下,使用中值。除了平均值和中值之外,还有其他技术,如随机值imputation, knn imputer,分布末端,任意值imputation等,也可以用于输入缺失值。这里的结论是不要到处使用mean(),因为mean()并不总是答案。
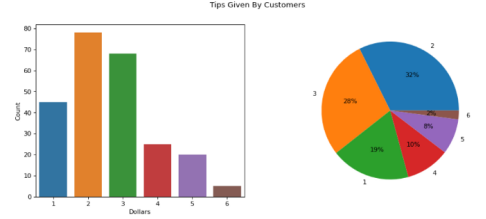
13 将条形图和饼状图组合在一起
我觉得柱状图和饼状图是表兄弟。柱状图用于展示“类别的数量”,饼状图用于展示“类别占整个组的百分比”。当你需要使用柱状图绘制超过10个类别时,一个好的做法是也包括一个饼状图,这样你就可以在一个地方获得类别的计数和百分比。
14 永远不要根据基本参数得分进行假设
不要因为模型的基本参数得分而拒绝它们。机器学习模型训练是一个过程,不是一天的事情。在做出任何强有力的假设之前,你必须尝试多种排列和组合。像XGBoost这样的一些模型通常在其基本参数上表现不佳,但当你花一些时间进行超参数调整并优化模型时,性能将得到提高。调整模型然后做一些假设是一个好习惯。相信我,线性回归和逻辑回归可以解决你90%的问题。
15 花更多时间分析
你应该总是把你花在一个项目上的时间分成不同的部分,其中数据分析应该拥有最大的蛋糕。根据数以千计的作者分享的多项研究和经验,数据科学家花费了大部分时间来清理和组织数据。如果你对数据进行良好的数据分析,则可以预测输出并在训练模型之前为模型设定一些标准。

感谢阅读。你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Abhay Parashar
翻译作者:马薏菲
美工编辑:过儿
校对审稿:Chuang
原文链接:https://medium.com/pythoneers/15-good-habits-every-data-scientist-should-adopt-be884bba121d





