,你需要知道这15个词")
关于时间序列分析(TSA),你需要知道这15个词
一个时间序列,就是在不同时间戳收集的数据点序列,而这些数据点序列则是以相同的时间间隔从相同的数据源收集的连续测量。如果你想了解更多关于数据分析的相关内容,可以阅读以下这些文章:
只会Pandas?来学习这25种Pandas变SQL的方法,让你的数据分析更得心应手!
数据分析求职最常用的30种大数据工具,你掌握几个了?
数据科学家V.S数据分析师面试全对比
数据分析在Supply Chain方向有哪些应用?
利用这一技术,我们可以使用这些按时间顺序收集的读数来监测一段时间内的变化趋势。时间序列模型可以是单变量,也可以是多变量——当因变量是单个时间序列时(如来自单个传感器的室温测量),使用单变量时间序列模型;当有多个因变量时(即输出取决于多个序列,如相互关联的变量“GDP”、“通货膨胀率”、“失业率”一起建立的模型),可以使用多变量时间序列模型。
- 时间序列表示一系列时间点读数,单位可以是“年”、“月”、“周”、“日”、“时”、“分”或“秒”。
- 时间序列是来自连续间隔的离散时间序列的观察。
- 时间序列是一种运行图。

- 时间变量/特征是自变量,支持目标变量预测结果。
- 时间序列分析被用于不同领域,如天气预报,经济走势,信号处理,工程控制系统和通信系统。
- 时间序列分析涉及产生特定序列的信息集,与空间分析等其他分析截然不同。
- 使用AR、MA、ARMA和ARIMA模型,我们甚至可以预测未来。
时间序列分析需要理解的15个重要术语
1 平稳和非平稳时间序列(Stationary and Non-Stationary Time Series)
平稳性是时间序列的一种特性,一个平稳序列表示其序列的值不是一个时间函数。换句话说,平稳序列的统计特性(如均值、方差和自相关)在时间上是恒定的,其序列的自相关所表示的只不过是序列与其先前值的相关性(如下图所示)。平稳时间序列不会被其他因素干扰。
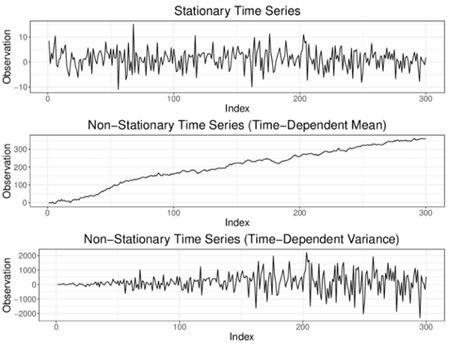
2 趋势(Trend)
趋势表示时间序列数据在长时间内的大致方向,可以是增加(向上)、减少(向下)或水平(静止)。
3 季节性(Seasonality)
季节性是指在时间、方向和幅度方面重复的趋势,比如由于天气炎热,夏季用水量增加。
4 周期性(Cyclical Component)
有时候,趋势不会固定在某个时间点出现。一个周期(通常在商业里)是指时间序列某个表现出起伏、繁荣和萧条的时期。这些周期不表现出季节性变化,但根据时间序列的性质,通常在3至12年的时间内轮回一次。
5 不规则变化(Irregular Variation)
时间序列数据中也会存在波动,特别是去除趋势和周期性变化时,这些波动尤为显眼。这种变化不可预测,不稳定,不规则,让人捉摸不透。
6 ETS分离(ETS Decomposition)
ETS用于分离时间序列的不同分量,所谓“ETS”代表的是误差、趋势和季节性。
7 关联(Dependence)
指的是同一变量在先前时间段的两个观测值的关联。
8 差分(Differencing)
差分可以让序列平稳,自我掌控。某些时候,我们不需要差分,事实上,过度差分的序列也可能会产生错误的估计。
9 规格(Specification)
即通过使用时间序列模型(如ARIMA模型)来测试因变量的线性或非线性关系。
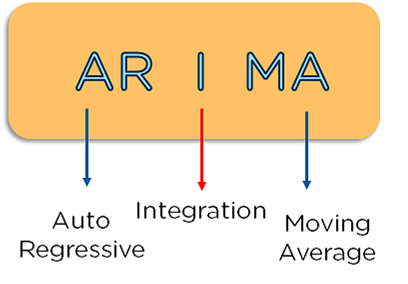
10 ARIMA
ARIMA,即自回归移动平均模型。
它可以利用时间序列的过去值和误差来预测其未来值。
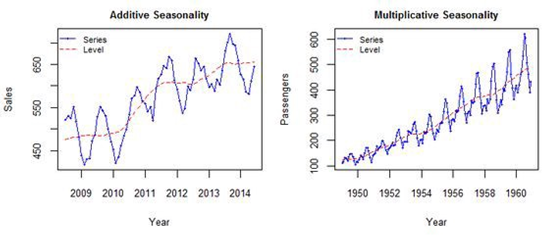
11 加法和乘法时间序列(Additive and Multiplicative Time Series)
由于会有不同的趋势和季节性组合,我们根据趋势和季节性的性质,可以将时间序列建模为加法或乘法时间序列(观测值表示为分量的和或积)。
加法时间序列:
值=基础值+趋势+季节性+误差
乘法时间序列:
值=基础值×趋势×季节性×误差
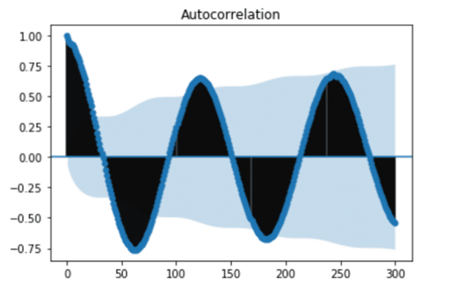
12 自相关(Autocorrelation)
自相关性是时间序列中两个不同观测值之间的相关性,两个被间隔开来的值可能具有很强的正相关或负相关性。当相关性存在时,就表示过去值影响了当前值。分析人员可以使用自相关和偏自相关函数来了解时间序列数据的性质,拟合适当的模型进行预测。
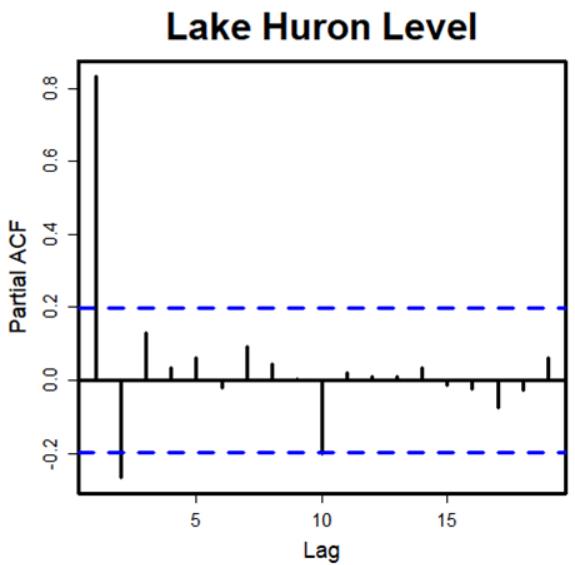
13 偏自相关(Partial Autocorrelation)
在时间序列分析中(https://en.wikipedia.org/wiki/Time_series_analysis),偏自相关函数(PACF)能给出平稳时间序列与其自身滞后值的偏相关(https://en.wikipedia.org/wiki/Partial_correlation),回归时间序列在所有较短滞后处的值。与不控制滞后的自相关函数对比起来,它显得格外亮眼。https://en.wikipedia.org/wiki/Autocorrelation_function)
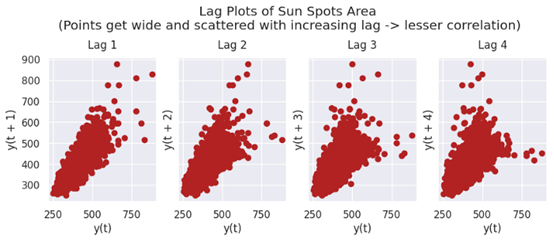
14 滞后图(Lag Plots)
滞后图是时间序列相对于其自身滞后的散点图,通常用于检测自相关。
15 可预测性(Forecastability)
时间序列的规律和可重复模式越多,预测就越容易。“近似熵”可以用来量化时间序列中波动的规律性和不可预测性。这也代表着,“近似熵”越高,预测的难度越大。
如果你要测量某个市场需求的变异系数,无论是实际销售量还是预测销售量,你都只会得到一个数字,既代表可预测,也代表不可预测——它不会告诉你哪部分是可预测的。
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Azmine Toushik Wasi
翻译作者:高佑兮
美工编辑:过儿
校对审稿:Chuang
原文链接:https://medium.com/@azmine_wasi/15-important-terms-to-understand-for-time-series-analysis-f492c90b4747





