揭秘——数据科学将如何应用在元宇宙.jpg "生成式AI与深度学习如何推动销售增长:3个实际用例")
生成式AI与深度学习如何推动销售增长:3个实际用例
我从(人工智能咨询)客户那里收到的最常见的请求是“为我定制一个聊天机器人”。虽然这是解决一些问题的好办法,但它远非包治百病。在这篇文章中,我将分享企业利用人工智能在销售环境中创造价值的三种方法。这些方法涵盖了生成式人工智能、深度学习和机器学习。如果你想了解更多关于人工智能的相关内容,可以阅读以下这些文章:
如何在2024年构建人工智能软件
Meta的FAIR团队:为全球免费开放人工智能
人工智能产品经理的崛起
Google的2024年人工智能设计原则:以用户为中心的人工智能体验
大型语言模型(LLM)已经占领了商业世界,现在每家公司都在尝试使用生成式人工智能。虽然像ChatGPT这样的工具显然很强大,但企业如何可靠地使用这项技术来驱动价值还不清楚。
对于我接触过的大多数企业来说,“使用人工智能”意味着建立一个聊天机器人、副驾驶、人工智能代理或人工智能助手。然而,随着对这些解决方案最初的兴奋消退,组织正在意识到围绕LLM构建系统的关键挑战。
这比我想象的要难…
一个核心挑战是LLM本质上是不可预测的(甚至比传统的机器学习系统更不可预测)。因此,要让他们可以预见地解决一个特定的问题并不容易。
例如,解决幻觉问题的一种方法是让“法官”LLM审查系统响应的准确性和适当性。然而,增加LLM的数量会增加系统的成本、复杂性和不确定性。
解决正确的问题
这并不是说生成式AI不值得追求。人工智能让无数公司变得非常富有,我认为这种情况不会很快停止。
关键在于,价值是通过解决问题产生的,而不是使用AI(本身)。当企业找到需要解决的正确问题时,人工智能的承诺就会实现,例如,Netflix的个性化推荐、UPS的配送路线优化、沃尔玛的库存管理等等。
3个AI销售用例
“解决正确的问题”说起来容易,做起来却不容易。为了帮助解决这个问题,我在这里分享3个人工智能用例,这些用例是每个企业都关心的——销售。我的希望是激发你的想象力,并用具体的例子演示如何实现它们。
这三个用例是:
- 特征工程——从文本中提取特征
- 结构化非结构化数据-使文本分析就绪
- 领先得分-识别你最大的机会
用例1:特征工程
特色工程包括创建可用于训练机器学习模型或执行一些分析的变量。例如,给定一组LinkedIn个人资料,提取当前职位、工作年限和行业等信息,然后用数字表示它们。
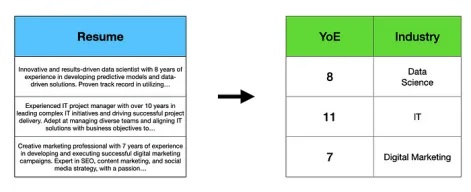
从简历文本中提取多年的经验和行业,图片来自作者
传统上,这有两种方式。
- 你手动创建功能
- 你从第三方购买功能(例如,FICO的信用评分,D&B的公司收入)。
然而,LLM创造了第三种方式来做到这一点。
示例:从简历中提取特征
假设你正在为SaaS产品筛选潜在客户。该软件有助于保护中端市场企业免受网络安全威胁。目标客户是决定哪些供应商适合他们公司的IT领导者。
你从不同的来源收集了10万份专业人士的简介和简历,这些简历的标签是“IT”、“网络安全”、“领导者”、“副总裁”等。然而,问题是,领导的质量很低,通常包括非IT领导、入门级IT专业人员和其他不符合客户形象的人。
为了确保销售工作集中在正确的客户身上,目标是过滤掉潜在客户,只包括IT领导者。这里有一些方法可以解决这个问题。
- 想法1:手动审查所有100,000条线索。问题:对于一个人或小型销售团队来说不切实际
- 想法2:编写基于规则的逻辑来过滤简历。问题:简历的格式多种多样,所以逻辑表现很差。
- 想法3:为这些信息向数据供应商付费。问题:这大大增加了获取客户的成本(每条线索约0.10美元)
考虑到上述思想的问题,让我们考虑一下如何使用大型语言模型来解决这个问题。一个简单的策略是设计一个提示,指导LLM从简历中提取所需的信息。下面给出一个例子。
Analyze the following text extracted from a resume and determine whether the
person works in the IT industry. Return a `0` if the person does not work in
theIT industry, and a `1` if they do. Then, provide a brief explanation for
your conclusion.
Resume Text:
{resume text}这个解决方案是上述三个想法的完美结合。
- 它像人一样审查每个线索寻找特定信息
- 它由计算机程序自动完成
- 你花的钱更少(每条线索约0.001美元)
奖励:对于那些有兴趣实现这类东西的人,我在这里分享一个示例Python脚本,它使用OpenAI API从LinkedIn个人资料中提取多年经验。https://youtu.be/3JsgtpX_rpU?si=WG1X-tvKmXLQLkEY&t=446
用例2:结构化非结构化数据
来自电子邮件、支持票、客户评论、社交媒体资料和电话记录的数据都是非结构化数据的例子。这仅仅意味着它不像Excel电子表格或.csv文件那样按行和列组织。
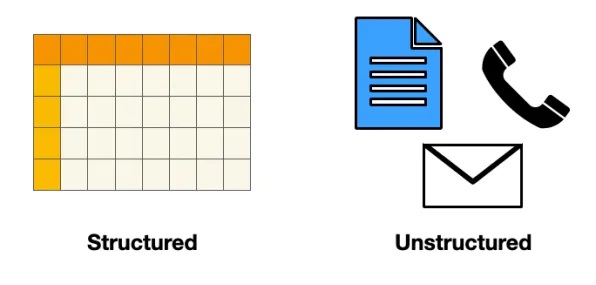
非结构化数据的问题在于它不能用于分析,因此很难获得洞察力。这与结构化数据(即按行和列组织的数字)形成对比。将非结构化数据转换为结构化格式是自然语言处理(NLP)和深度学习的最新进展可以提供帮助的另一个领域。
示例:将简历翻译成(有意义的)数字
考虑前面示例中的相同业务案例。假设我们成功地从100,000个线索中挑选出10,000个IT领导者。当你的销售人员开始拿起电话和制作电子邮件时,你首先要看看你是否可以提炼出列表,以优先考虑与过去的客户类似的潜在客户。
一种方法是定义额外的特性,为理想的客户概要提供更多的粒度(例如,行业、遵从性需求、技术堆栈、地理位置),这些特性可以像用例1一样被提取出来。然而,识别这些指标可能具有挑战性,并且开发额外的自动化流程需要成本。
另一种方法是使用所谓的文本嵌入。文本嵌入只是语义上有意义的文本块的数字表示,这就像把一份简历翻译成一组数字。

文本嵌入的价值在于它们将非结构化文本转换为结构化的数字表,这更适合传统的分析和计算方法。例如,在这种情况下,可以使用文本嵌入来数学地评估哪些潜在客户与过去的客户最相似,哪些最不同。
用例3:领先得分
最后一个用例是潜在客户评分,它包括基于关键预测因素(例如,职位、公司收入、客户行为等)评估潜在客户的质量。虽然这并不是什么新鲜事,但人工智能的最新进展使人们能够更好地解析非结构化数据,并将其输入领先评分模型。
示例:根据质量对线索进行分级
为了总结我们正在进行的业务案例,让我们讨论一下如何使用文本嵌入来优先考虑潜在客户。假设我们有1000个过去的线索,其中500人买了,500人没有。对于每个领导,我们都有一个包括关键信息的简介,如职位、工作经验、当前公司、行业和关键技能。
这些线索可以用来训练一个预测模型,该模型可以根据客户的个人资料估计客户购买产品的可能性。虽然开发这样的模型有许多细微差别,但基本的想法是,我们可以使用该模型的预测来定义每个线索的等级(例如,a, B, C, D),这可以用于对10,000个新线索进行分类和优先排序。
奖励:对于寻求实现这些方法的更多技术读者,我在本视频中介绍了应用于我的业务的实际销售数据的所有三个用例(https://youtu.be/3JsgtpX_rpU)。此外,示例代码可以在GitHub上免费获得。(https://github.com/ShawhinT/YouTube-Blog/tree/main/ai-for-business/3-sales-use-cases)
回顾
人工智能对企业具有巨大的潜力。然而,意识到这种潜力需要确定正确的问题来解决它。
随着ChatGPT等工具的普及,解决方案的想法很容易被限制在人工智能助手范式中。为了帮助扩展可能性的空间,我分享了本文中的3个使用替代方法的实际AI用例。
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/。
原文作者:Shaw Talebi
翻译作者:过儿
美工编辑:过儿
校对审稿:Jason
原文链接:https://towardsdatascience.com/3-ai-use-cases-that-are-not-a-chatbot-f4f328a2707a





