
面向技术领导者的5个有关生成式人工智能的残酷事实
生成式人工智能(GenAI)无处不在,各行各业的组织都在对其团队施加压力,希望能够参与这场竞争 – 77%的业务领导者担心他们已经错过了GenAI的好处。
数据团队正在争先恐后地响应号召。但是构建一个真正能够推动业务价值的生成式人工智能模型是很困难的。
从长远来看,与OpenAI API的快速集成并不能解决问题。这是GenAI,但是什么是优势?为什么用户应该选择你而不是ChatGPT?
简单地勾选一个选项框可能会让你觉得进展了一步,但是如果你还没有开始考虑如何将LLMs与你的专有数据和业务背景相连接以真正推动差异化的价值,那你就落后了。
这不是夸大其词。就在本周,我已经与六位数据领导者就这个话题进行了交谈。他们都意识到这是一场竞赛。在终点线上,将会有赢家和输家,就像是Blockbusters和Netflix。
如果你感觉起跑枪已经响了,但是你的团队还停留在起跑线上,只是在谈论“泡沫”和“炒作”,我整理了5个残酷的事实,帮助你摆脱自满情绪。如果你想了解更多关于人工智能的相关内容,可以阅读以下这些文章:
2024年每个开发人员都需要掌握的生成式人工智能技能
Google的Gemini AI模型:揭开人工智能的未来
世界上最好的人工智能模型:谷歌DeepMind的Gemini已经超过了GPT-4!
我尝试了50种人工智能工具,以下是我的最爱
残酷的事实1:你的生成式人工智能功能没有得到广泛采用,你的变现速度很慢。
“Barr,如果GenAI如此重要,为什么我们目前实现的功能得到的采用率如此之低?”
嗯,有几个原因。首先,你的人工智能计划并不是为了应对大量定义明确的用户问题。对于大多数数据团队来说,这是因为你正在比赛,而且时间还早,并且你想获得一些经验。
然而,用不了多久,你的用户就会遇到一个最好由GenAI解决的问题,当这种情况发生时,与你的Tiger团队集思广益将GenAI与用例联系起来的方法相比,你将获得更好的采用率。
而且由于现在还处于早期阶段,已经集成的生成式人工智能功能只是“ChatGPT在这里而已”。
让我给你举个例子。想象一下你每天使用的一个用于共享组织知识的生产力应用程序。这样的应用程序可能提供一个功能,可以在非结构化文本块上执行命令,比如“总结这个”、“增加长度”或“改变语气”。一个命令等于一个人工智能积分。
是的,这很有帮助,但是并没有差异化。
也许团队决定购买一些人工智能积分,或者他们只是简单地切换到另一个标签页并询问ChatGPT。我并不完全忽视或低估不将专有数据暴露给ChatGPT的好处,但与全国各地的盈利电话会议上所描绘的情况相比,这也是一个较小的解决方案和愿景。
图片由Substack上的Joe Reis提供
因此,请考虑一下:你的GenAI差异化优势和附加值是什么?让我给你一个提示:高质量的专有数据。
这就是为什么RAG模型(有时是微调模型)对Gen AI计划如此重要的原因。它允许LLM访问该企业的专有数据。我将在下面解释原因。
残酷的事实2:你害怕用Gen AI做更多的事情。
确实如此:生成人工智能令人生畏。
当然,你可以将你的人工智能模型更深入地集成到你的组织流程中,但这感觉有风险。让我们面对现实吧:ChatGPT会产生幻觉,而且无法预测。存在一个知识界限,使用户容易受到过时输出的影响。即使是偶然的,数据处理不当和向消费者提供错误信息也会产生法律后果。
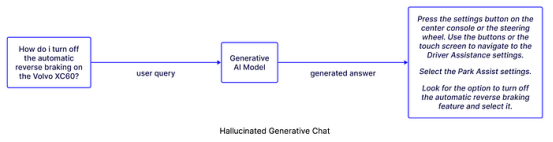
图片由Pinecone提供
你的数据错误会造成后果。这就是为什么准确了解你向GenAI提供的数据以及数据的准确性至关重要。
在我们发给数据领导者的一项匿名调查中,询问他们的团队离实现GenAI用例还有多远,一个回答是,“我不认为我们的基础设施是阻碍我们前进的因素。我们在方面非常谨慎—随着形势变化如此之快,以及‘流氓’聊天机器人可能带来声誉损害的风险,我们暂时搁置并等待炒作平息一些!”
这是我采访过的许多数据领导者普遍认同的观点。如果数据团队突然出现了面向客户的安全数据,那么他们就陷入了困境。数据治理是一个重要的考虑因素,这是一个很高的门槛。
这些都是真正的风险,需要解决方案,但你不能袖手旁观来解决它们。还有一个真正的风险,就是看着你的业务被最先解决这个问题的团队从根本上被打破。
通过微调和RAG将LLM建立在你的专有数据中是这个难题的一大组成部分,但这并不容易…
残酷的事实3:RAG是困难的。
我相信 RAG(检索增强生成)和微调是未来企业生成式人工智能的核心。但尽管在大多数情况下RAG是较简单的方法,但开发RAG应用仍然很复杂。
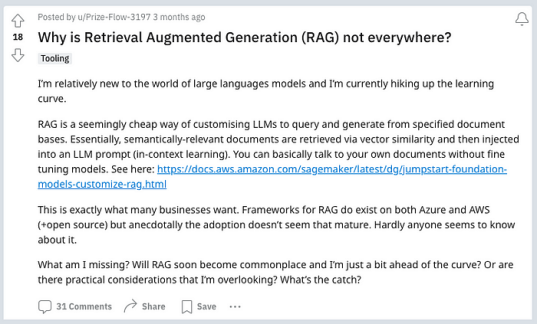
RAG似乎是定制LLM的一个显而易见的解决方案。但是RAG的开发有一个学习曲线,即使对于最有才华的数据工程师也是如此。他们需要了解即时工程、矢量数据库和嵌入矢量、数据建模、数据编排、数据管道……所有这些都是为了RAG。而且,由于它是新的(由Meta AI在2020年推出),许多公司还没有足够的经验来建立最佳实践。
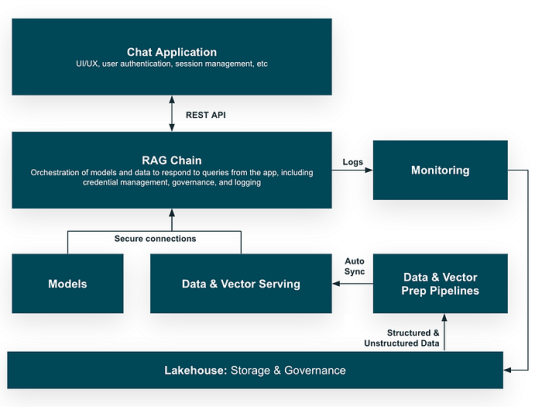
这是一个过度简化的RAG应用架构:
- RAG体系结构将信息检索与文本生成器模型结合在一起,因此它可以在尝试回答用户的问题时访问你的数据库。
- 数据库必须是包含专有数据的可信源,并且它允许模型将最新的可靠信息合并到其响应和推理中。
- 在后台,数据管道将各种结构化和非结构化源摄取到数据库中,以保持数据库的准确性和最新性。
- RAG链接受用户查询(文本)并从数据库中检索相关数据,然后将该数据和查询传递给LLM,以便生成高度准确和个性化的响应。
这种架构有很多复杂性,但它确实有重要的好处:
- 它将你的LLM奠定了准确的专有数据的基础,从而使其更有价值。
- 它将模型带入数据,而不是将数据带入模型,这是一种相对简单且经济有效的方法。
我们可以看到这在现代数据栈中成为现实。最大的参与者正在以极快的速度努力,通过在存储企业数据的环境中提供LLM来简化RAG。
Snowflake Cortex现在使组织能够快速分析数据并直接在Snowflake中构建人工智能应用程序。Databricks的新基础模型API可直接在Databricks中即时访问LLM。微软发布了Microsoft Azure OpenAI服务,亚马逊最近推出了Amazon Redshift Query Editor。
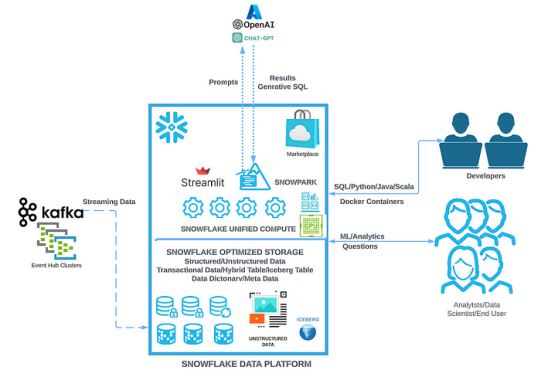
我相信所有这些功能都很有可能被广泛采用。但是,它们也提高了对这些数据存储中数据质量的关注。如果提供给你的RAG管道的数据是异常的、过时的或不可信的,那么你的生成式人工智能计划的未来是什么?
残酷的事实4:你的数据还没有准备好。
仔细审视一下你的数据基础架构。如果你有一个完美的RAG管道、微调的模型和清晰的用例,明天就可以使用了(这不是很好吗?),那么你仍然不会有干净、建模良好的数据集来将其全部插入其中。
假设你希望聊天机器人与客户进行交互。为了做任何有用的事情,它需要了解该组织与客户的关系。如果你现在是一个企业组织,那么这种关系很可能在150个数据源和5个孤立的数据库之间定义的,其中3个仍然是本地数据库。
如果这描述了你的组织,那么你可能需要一年(或两年!)才能使你的数据基础设施准备好GenAI。
这意味着,如果你想在不久的将来使用GenAI做一些事情,你需要在一个现代的数据平台上创建有用的、高度可靠的、统一的、有良好文档记录的数据集……否则,你可能会错过机会,而且会出现尴尬的局面。
数据工程团队是确保数据健康的中坚力量。而且,现代数据堆栈使数据工程团队能够持续监控未来的数据质量。
残酷的事实5:你在不知不觉中已经将关键的Gen AI参与者排除在外。
生成式AI是一项团队运动,尤其是在开发方面。许多数据团队犯了一个错误,就是将关键参与者排除在他们的GenAI团队之外,从长远来看,这会让他们付出代价。
AI团队应该由谁组成?领导层或主要的业务利益相关者,来带头推动这一倡议,并提醒团队关于业务价值。软件工程师负责开发代码、面向用户的应用程序和API调用。数据科学家负责考虑新的应用场景,优化模型,并引导团队朝着新的方向发展。这里缺少了谁?
数据工程师。
数据工程师对GenAI项目至关重要。他们将能够了解提供比ChatGPT更具竞争优势的专有业务数据,并将建立管道,通过RAG向LLM提供这些数据。
如果你的数据工程师不在场,你的团队就不完整。在GenAI方面最具开创性的公司告诉我,他们已经将数据工程师嵌入到所有的开发团队中。
赢得GenAI竞赛
如果这些残酷的事实中有任何一条适用于你,不要担心。生成式人工智能还处于起步阶段,所以你还有时间重新开始,并接受这个挑战。
退后一步,了解人工智能模型可以解决的客户需求,让数据工程师进入早期的开发阶段,以确保从一开始就具有竞争优势,并花时间建立一个能够提供稳定高质量可靠数据的RAG流程。
并且,投资于现代数据堆栈,将数据质量放在首位。因为没有高质量数据的生成式人工智能只是一堆空洞的东西。
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Barr Moses
翻译作者:文杰
美工编辑:过儿
校对审稿:Jason
原文链接:https://towardsdatascience.com/5-hard-truths-about-generative-ai-for-technology-leaders-4b119336bc85





