
数据科学家须知:统计学中的5个悖论
统计学是数据科学的重要组成部分,为我们提供了分析和理解数据的各种工具和技术。但有时统计结果可能与我们的感知相悖,甚至自相矛盾,导致了混乱和误解。在这篇文章中,我们将探讨每个数据科学家都应该熟悉的五个统计悖论。我们将解释每个悖论是什么,为什么会发生,以及如何避免掉进悖论的陷阱中。
看完文章后,你将对统计分析中可能出现的一些奇怪和意外的结果有更好的了解,并在工作中更好地处理它们。如果你想了解更多关于数据科学的相关内容,可以阅读以下这些文章:
数据科学家订阅ChatGPT三周体验:每天节省3小时工作时间!
没有经验?一样能获得数据科学实习机会
14场Kaggle比赛,开启你的数据科学之旅
如何从数据分析师过渡到数据科学家的角色?
目录
- 准确性悖论(Accuracy Paradox)
- 假阳性悖论(False Positive Paradox)
- 赌徒谬论(Gambler’s Fallacy)
- 辛普森悖论(Simpson’s Paradox)
- 伯克森悖论(Berkson’s Paradox)
- 结论
1准确性悖论(Accuracy Paradox)
准确性悖论是指即使模型不具有预测性,也可以实现高度准确的情况。当数据集中的类分布不平衡时,可能会发生这种情况。例如,一个数据集,其中90%的观测值属于一个类,10%属于另一个类,那么,预测所有观测值的多数类的模型将达到90%的准确率,即使它并没有真正预测任何东西。
下面是Python中的一个示例用于说明这个概念:
import numpy as np
from sklearn.metrics import accuracy_score
# create imbalanced dataset
y_true = np.array([0] * 900 + [1] * 100)
y_pred = np.zeros(1000)
# calculate accuracy
accuracy = accuracy_score(y_true, y_pred)
print('Accuracy:', accuracy)在这个例子中,我们创建了一个不平衡的数据集,一个类中有900个观测值,另一个类中有100个观测值。然后,我们创建一个模型来预测所有观测值的多数类(0)。尽管没有实际预测任何东西,但该模型达到了90%的准确率。
我们可以在医学测试中看到准确性悖论的例子。假设有一种罕见的疾病,其发病率仅为十万分之一。如果创建了一种检测疾病的准确率为99.9%的测试,但将其用于只有0.1%的人患有这种疾病的人群,则该测试将具有99.9%的高准确率。然而,它将导致大量的假阳性,这意味着许多健康人将被错误地诊断为这种疾病。
相比使用准确性评估分类任务,精确度和召回率是更好的选择——这些指标与假阳性悖论有关,我们接着看:
2 假阳性悖论(False Positive Paradox)
当模型的准确性很高,但假阳性率也很高时,就会出现假阳性悖论。换句话说,当大量实例实际上是负的时,模型可以将它们分类为正的。这种悖论会导致错误的结论和决策。
示例:
import pandas as pd
import numpy as np
# Define variables
normal_count = 9999
fraud_count = 1
false_positives = 499.95
false_negatives = 0
# Calculate precision
precision = fraud_count / (fraud_count + false_positives)
print(f"Precision: {precision:.2f}")
# Calculate recall
recall = fraud_count / (fraud_count + false_negatives)
print(f"Recall: {recall:.2f}")
# Calculate accuracy
true_negatives = normal_count - false_positives
accuracy = (true_negatives + fraud_count) / (normal_count + fraud_count)
print(f"Accuracy: {accuracy:.2f}")
Output:
Precision: 0.00
Recall: 1.00
Accuracy: 0.95我们假设对一种只影响1%人口的疾病进行医学测试。如果其测试的准确率为99%,那么它在99%的情况下都能正确识别疾病的存在与否。然而,如果对1000人进行检测,即使只有1人实际患有这种疾病,也会有10人检测呈阳性。这意味着阳性检测结果更可能是“假”阳性。
下面是产生悖论的Python代码示例:
from sklearn.metrics import confusion_matrix
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
# generate a binary classification dataset
X, y = make_classification(n_samples=1000, n_features=10, n_informative=5, n_redundant=5, random_state=42)
# split the dataset into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# train a logistic regression model
model = LogisticRegression(random_state=42)
model.fit(X_train, y_train)
# predict on test set and get the confusion matrix
y_pred = model.predict(X_test)
tn, fp, fn, tp = confusion_matrix(y_test, y_pred).ravel()
# calculate the accuracy, precision, and recall
accuracy = (tp + tn) / (tp + tn + fp + fn)
precision = tp / (tp + fp)
recall = tp / (tp + fn)
print(f"Accuracy: {accuracy:.2f}")
print(f"Precision: {precision:.2f}")
print(f"Recall: {recall:.2f}")
Output:
Accuracy: 0.79
Precision: 0.82
Recall: 0.75在这种情况下,精确度和召回率是评估模型性能的更好方法。精确度测量所有阳性分类中真阳性的比例,而召回率测量所有实际阳性实例中真阳性的比例。这些措施可以帮助避开产出假阳性悖论,并为模型的性能提供更准确的评估。
3 赌徒谬论(Gambler’s Fallacy)
赌徒谬论,即相信过去的事件可以在随机过程中影响未来事件的概率。例如,在轮盘游戏中,一些玩家认为,如果球连续几次旋转都落在黑色上,那么下一次落在红色上的机会就会更高,尽管结果仍然是随机的。
通过Python示例,我们使用NumPy模块来模拟抛硬币:
import numpy as np
# Simulate flipping a coin 10 times
results = np.random.randint(0, 2, size=10)
print(f"Coin flips: {results}")
# Count the number of consecutive heads or tails
consecutive = 0
for i in range(1, len(results)):
if results[i] == results[i-1]:
consecutive += 1
else:
consecutive = 0
# Print the result
if consecutive > 0:
print(f"Number of consecutive flips: {consecutive + 1}")
else:
print("No consecutive flips")
Output:
Coin flips: [0 1 0 0 0 0 0 0 1 0]
No consecutive flips在上面的示例中,代码模拟抛硬币10次,然后计算连续正面或反面的数量。赌徒谬论表明,如果连续出现几个正面,那么下一个翻转更有可能是反面,反之亦然。然而,在现实中,每一次抛硬币都是独立的,并且产生正面或反面的机会是均等的。
我们可以在股票市场中看到赌徒谬论的例子。一些投资者可能认为,如果一只股票的价值连续几天持续上涨,那么它更有可能很快下跌,尽管市场走势本质上仍然不可预测,并受到一系列因素的影响。
4 辛普森悖论(Simpson’s Paradox)
辛普森悖论是一种统计现象,即当一个趋势出现在一个小数据集上而数据集被划分为子组时,趋势消失或逆转。如果数据分析不正确,这可能导致错误的结论。

假设我们想要比较一所大学男女生的录取率,我们有两个部门的数据:部门A和部门B.
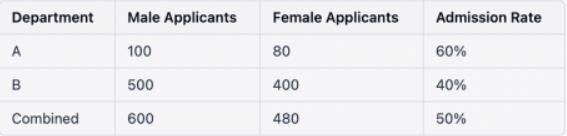
在上述表格中,男性和女性的综合录取率为50%。然而,当我们按部门分析数据时,我们看到在每个部门中,女性的录取率都高于男性的录取率。这似乎违反了我们的感知,因为男性的总体录取率更高。
这一悖论的出现是因为每个系的申请人数和录取率都不一样。A系的整体录取率较高,但女性报考者的比例较低。部门B的整体录取率较低,但女性报考者的比例较高。
在Python中,我们可以使用以下代码来演示:
import pandas as pd
# Create a dataframe
df = pd.DataFrame({'Department': ['A', 'A', 'B', 'B'],
'Gender': ['Male', 'Female', 'Male', 'Female'],
'Applicants': [100, 80, 500, 400],
'Admitted': [60, 40, 40, 70]})
# Calculate admission rates
df['Admission Rate'] = df['Admitted'] / df['Applicants'] * 100
# Display the dataframe
print(df)
# Calculate overall admission rate
overall_rate = df['Admitted'].sum() / df['Applicants'].sum() * 100
print(f"Overall Admission Rate: {overall_rate:.2f}%")
# Calculate admission rates by department and gender
department_rates = df.groupby(['Department', 'Gender'])['Admission Rate'].mean()
print(department_rates)
Ouput:
Department Gender Applicants Admitted Admission Rate
0 A Male 100 60 60.0
1 A Female 80 40 50.0
2 B Male 500 40 8.0
3 B Female 400 70 17.5
Overall Admission Rate: 19.44%
Department Gender
A Female 50.0
Male 60.0
B Female 17.5
Male 8.0
Name: Admission Rate, dtype: float64在上面的代码中,我们使用与上表中相同的数据创建了一个dataframe ,然后,我们计算录取率并显示dataframe 。接下来,我们计算整体录取率,即19.44%。最后,我们按部门和性别对数据进行分组,并计算每个亚组的录取率。我们看到,尽管男性的总体录取率更高,但女性在这两个部门的录取率都更高。这,即是辛普森悖论。
5 伯克森悖论(Berkson’s Paradox)
同样作为一种统计现象,伯克森悖论,指其中两个独立或任意变量之间呈现负相关,但当数据被分成亚组时,尽管它们之间没有实际相关性,还是出现了正相关。当两个自变量具有共同的影响或原因,而该影响或原因不包括在分析中时,就会出现这种悖论。
接下来,我们使用IRIS数据集解释这个悖论——先让我们将萼片长度和宽度作为两个变量。我们可以使用PANDAS中的corr()方法计算这两个变量之间的相关系数:
import pandas as pd
import seaborn as sns
iris = sns.load_dataset('iris')
correlation = iris['sepal_length'].corr(iris['sepal_width'])
print('Correlation between sepal length and width:', correlation)
Correlation between sepal length and width: -0.11756978413300208正如我们所看到的,在整个数据集中,萼片长度和宽度之间存在负相关。
然而,如果我们按物种划分数据集,并分别计算每个物种的相关系数,我们可能会得到不同的结果。例如,如果我们只考虑刚毛藻物种,我们会得到一个正相关:
setosa = iris[iris['species'] == 'setosa']
correlation_setosa = setosa['sepal_length'].corr(setosa['sepal_width'])
print('Correlation between sepal length and width for setosa:', correlation_setosa)
Correlation between sepal length and width for setosa: 0.7425466856651597这意味着刚毛藻的萼片长度和宽度之间存在正相关,与总体负相关相反。
这一悖论的出现是因为与其他物种相比,刚毛属物种的萼片长度和宽度的数值范围较小。因此,当我们只考虑刚毛藻物种时,整个数据集内的负相关性被刚毛藻物种内的正相关性所掩盖。
结论
总之,理解统计悖论对于数据科学家至关重要,它们可以帮助我们避免数据分析中的常见错误和偏差。
- 准确性悖论告诉我们,仅有准确性不足以评估分类任务,精确度和召回率提供的信息更多。
- 假阳性悖论强调了理解假阳性成本的重要性。
- 赌徒谬论提醒我们,每个事件都是独立的,过去的结果不会影响未来的结果。
- 辛普森悖论表明,汇总数据可以模糊变量之间的关系,并导致错误的结论。
- 最后,伯克森悖论表明,当从总体中选择非随机样本时,抽样偏差是如何发生的。

意识到这些悖论可以帮助数据科学家在工作中做出更准确、更明智的决策。你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Simranjeet Singh
翻译作者:高佑兮
美工编辑:过儿
校对审稿:Chuang
原文链接:https://medium.com/@simranjeetsingh1497/5-paradoxes-in-statistics-every-data-scientist-should-be-familiar-with-478b74310099



