
提高ML模型稳健性的5种交叉验证方法
为什么要进行交叉验证?
在我开始销售商品之前,我需要陈述一下主要思想。想象一个你不知道什么是交叉验证的疯狂世界。在这个世界里,你把数据分成一个训练集和测试集,训练你的模型并进行测试。如果对分数不满意,你可以调整你的模型,直到GridSearch(或Optuna)喊出“够了!”。
在这里,有两件事可能会严重出错:
- 这些集合可能无法很好地代表整个群体。例如,类别或数值变量可能在训练集和测试集之间分布不均,从而导致结果偏斜。
- 在超参数调优期间,你可能会面临泄漏测试集知识的风险。调优框架可能会为你提供最适合该特定测试集的参数,这可能会导致过拟合。
在一个接受交叉验证的世界里,这些问题得到了解决。交叉验证的神奇之处在这个5-fold交叉验证过程的示例中得以展现:
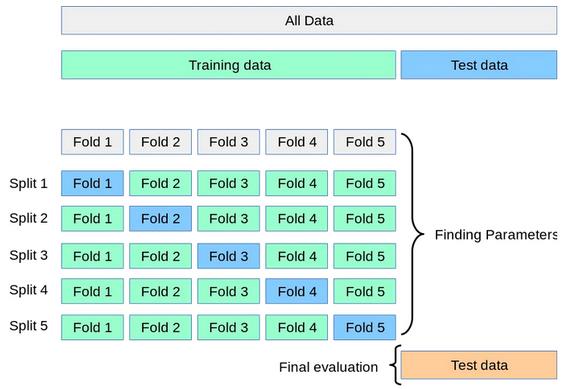
新模型在四个fold上进行训练,并在每次迭代的最后一个fold上测试,以确保使用所有数据。平均分数及其标准差作为置信区间报告,提供了对模型性能的真实度量。
交叉验证有很多变体,我们将在本文中介绍最重要的五种。如果你想了解更多关于机器学习的相关内容,可以阅读以下这些文章:
2023年面向开发者的十大机器学习(ML)工具
CPU与GPU:哪个更适合机器学习,为什么?
MLOps简介:机器学习的实验跟踪
打好数据科学和机器学习的基础——6本书带你学数学
01 KFold
最简单的交叉验证程序是KFold,如上图所示。它在Sklearn中以相同的名称实现。在这里,我们将编写一个快速函数来可视化交叉验证拆分器的拆分索引:
#可视化任意拆分过程的函数
def visualize_cv(cv, X, y):
fig, ax = plt.subplots(figsize=(10, 5))
for ii, (tr, tt) in enumerate(cv.split(X, y)):
p1 = ax.scatter(tr, [ii] * len(tr), c="#221f1f", marker="_", lw=8)
p2 = ax.scatter(tt, [ii] * len(tt), c="#b20710", marker="_", lw=8)
ax.set(
title=cv.__class__.__name__,
xlabel="Data Index",
ylabel="CV Iteration",
ylim=[cv.n_splits, -1],
)
ax.legend([p1, p2], ["Training", "Validation"])
plt.show()现在,让我们将包含七个拆分的KFold拆分器传递给这个函数:
from sklearn.datasets import make_regression
from sklearn.model_selection import KFold
X, y = make_regression(n_samples=100)
# Init the splitter
cv = KFold(n_splits=7)
visualize_cv(cv, X, y)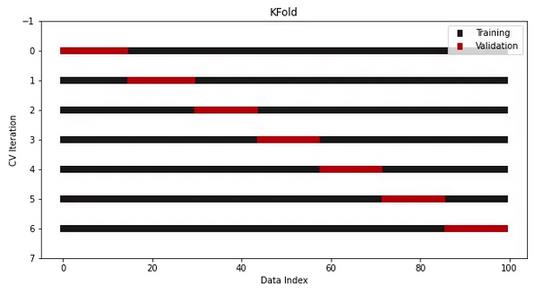
这就是一个vanilla KFold的样子。
另一个版本是在执行拆分之前对数据进行混洗。通过打破样本的原始顺序,进一步降低了过度拟合的风险:
cv = KFold(n_splits=7, shuffle=True)
visualize_cv(cv, X, y)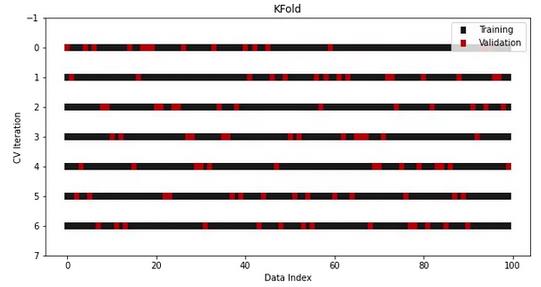
正如你所看到的,验证样本的索引是以一种随机的方式选择的。即便如此,总体样本数仍然是整个数据集的七分之一,因为我们做的是7-fold交叉验证。
KFold是最常用的交叉验证拆分器。它易于理解且非常有效。然而,根据数据集的特点,有时你需要对使用的交叉验证程序更加挑剔。那么,让我们讨论一下其他选择。
02 StratifiedKFold
StratifiedKFold是专门为分类问题设计的KFold的另一个版本。
在分类中,即使将数据分成多个集合,也必须保持目标分布不变。更具体地说,具有30到70个类比率的二元目标在训练集和测试集中应该仍然保持相同的比率。
在vanilla KFold中,这一规则被打破了,因为在拆分之前对数据进行混洗时,类比率将不会被保留。作为解决方案,我们在Sklearn中使用另一个拆分器进行分类——StratifiedKFold:
from sklearn.datasets import make_classification
from sklearn.model_selection import StratifiedKFold
X, y = make_classification(n_samples=100, n_classes=2)
cv = StratifiedKFold(n_splits=7, shuffle=True, random_state=1121218)
visualize_cv(cv, X, y)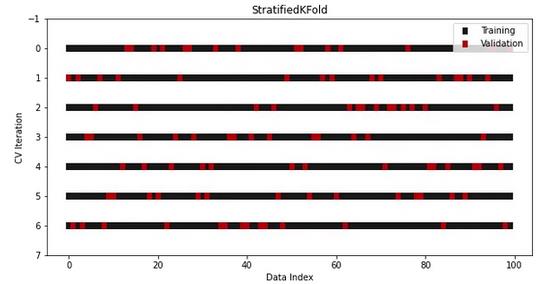
它看起来和KFold一样,但是现在在所有的Fold和迭代中都保留了类比率。
03 LeavePOut
有时,你拥有的数据非常有限,甚至无法将其划分为训练集和测试集。在这种情况下,可以执行交叉验证,在每次迭代中只保留几行数据。这被称为LeavePOut交叉验证,其中P是你选择的参数,用于指定每个保留集中的行数。
最极端的情况是LeaveOneOut拆分器,其中仅使用单行作为测试集,迭代次数等于完整数据中的行数。如果为一个只有100行的小型数据集构建100个模型近乎有些疯狂,我完全能理解你的感受。
即使p值较高,迭代次数也会随着数据集大小的增加呈指数增长。想象一下,当p为5时,而数据只有50行时,将构建多少个模型(提示:使用排列组合公式)。
因此,你很少在实践中看到这种情况,但它出现的次数足够多,Sklearn将这些过程作为单独的类来实现:
from sklearn.model_selection import LeaveOneOut, LeavePOut04 ShuffleSplit
如果我们不进行交叉验证,只是多次重复进行训练/测试集的拆分过程呢?这个方法你可以将其视作为交叉验证的另一种尝试,尽管没有真正实施它。
从逻辑上讲,如果进行足够的迭代,使用不同的随机种子生成多个训练集和测试集应该类似于一个稳健的交叉验证过程。这就是为什么在Sklearn中有一个拆分器来执行这个过程:
from sklearn.model_selection import ShuffleSplit
cv = ShuffleSplit(n_splits=7, train_size=0.75, test_size=0.25)
visualize_cv(cv, X, y)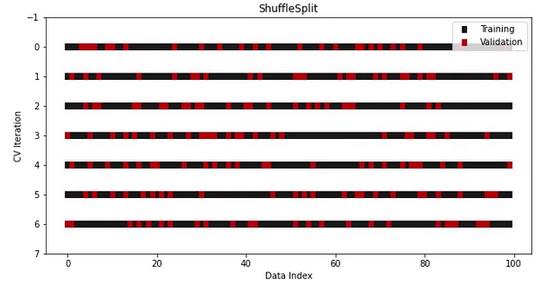
ShuffleSplit的优点是你可以完全控制每个fold中的训练集和测试集的大小。集合的大小不必与拆分的次数成反比。
例如,一个有5个fold且测试集大小为25%的ShuffleSplit:
- 在每个fold中生成75/25比率的训练/测试集
- 在拆分前对数据进行混洗
然而,与其他拆分器不同的是,不能保证随机拆分会在每次迭代中生成不同的fold。所以,要谨慎使用这个类。
顺便说一下,还有一个分层版本的ShuffleSplit用于分类:
from sklearn.model_selection import StratifiedShuffleSplit
cv = StratifiedShuffleSplit(n_splits=7, test_size=0.5)
visualize_cv(cv, X, y)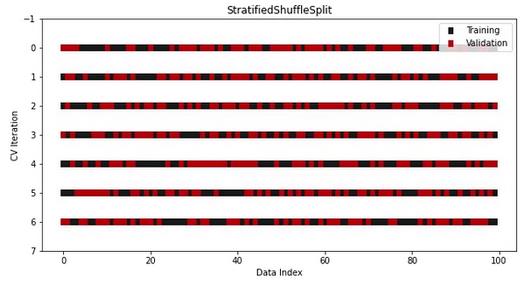
05 TimeSeriesSplit
最后,我们有时间序列数据的特殊情况,其中样本的顺序很重要。
我们不能使用任何传统的交叉验证方法,因为那样很容易出现问题。很有可能会在未来的样本上进行训练并预测过去的样本。
为了解决这个问题,Sklearn提供了另一个拆分器——TimeSeriesSplit,它可以确保上述情况不会发生:
from sklearn.model_selection import TimeSeriesSplit
cv = TimeSeriesSplit(n_splits=7)
visualize_cv(cv, X, y)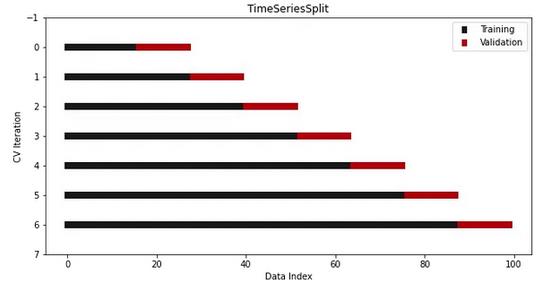
正如你所看到的,测试集总是在训练集的索引之后。由于索引是日期,因此你不会意外地在未来日期上训练时间序列模型并预测之前的日期。
用于非IID数据的交叉验证拆分器
到目前为止,我们一直在处理IID(独立且相同分布的)数据。换句话说,生成数据的过程对过去的样本没有记忆。
然而,在某些情况下,你的数据不是IID,即某些样本组是相互依赖的。例如,在Kaggle上的谷歌大脑呼吸机压力竞赛中,参与者应该使用非IID数据。
这些数据记录了人工肺进行的数千次呼吸(吸气、呼气),并以毫秒为间隔记录每次呼吸的气压。因此,每次呼吸的数据包含大约80行,这使得这些行相互依赖。
在这里,传统的交叉验证拆分器不会像预期的那样工作,因为拆分有可能会发生在“呼吸的中间”。下面是Sklearn用户指南中的另一个例子:
这样的数据分组是特定于某此领域的。例如,从多个患者处收集医疗数据,并从每个患者处采集多个样本。而这些数据很可能取决于个体群体。在我们的示例中,每个样本的患者ID将是其组标识符。
它还在后面陈述了解决方案:
在这种情况下,我们想知道在特定的组上训练的模型是否可以很好地推广到未知的组。为了测量这一点,我们需要确保测试集中的所有样本都来自于成对训练集中根本没有出现的群组。
然后,Sklearn列出了五个可以处理分组数据的不同类。如果你掌握了前几节的想法,并理解了什么是非IID数据,那么处理它们就不会有问题了:
- GroupKFold
- StratifiedGroupKFold
- LeaveOneGroupOut
- LeavePGroupsOut
- GroupShuffleSplit
每个拆分器都有一个groups参数,你应该将存储组ID的列传递给该参数。这告诉类如何区分每个组。
总结
最后,这一切都算是明朗了。
我可能还未回答的一个问题是,“你是否总是使用交叉验证?”答案是肯定的。当数据集足够大时,任何随机拆分都可能与两个集合中的原始数据很相似。在这种情况下,交叉验证并不是一个严格的要求。
然而,统计学家和在StackExchange上比我更有经验的人说,无论数据大小,你都应该执行至少两到三次交叉验证。再谨慎也不为过。
感谢阅读。你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Bex T
翻译作者:文玲
美工编辑:过儿
校对审稿:Chuang
原文链接:https://pub.towardsai.net/5-powerful-cross-validation-methods-to-skyrocket-robustness-of-your-ml-models-5edaab564cd8





