
Pandas初学者容易犯的六个错误
00# 前言
我们都习惯了在编写代码时经常弹出的又大又红的错误信息。幸运的是,人们很少注意它,因为我们总是能修复这些错误。但是那些没有显示有错误消息的错误呢?这些是最棘手的,但专业人士可以很容易地指出来。
这些错误与你正在使用的工具的API或语法无关,但与最佳实践和你在工具上花费的时间直接相关。今天,我们在这里谈谈初学者使用Pandas经常出现的六个错误,以及我们将学习如何解决它们。如果你想了解更多关于编程的相关内容,可以阅读以下这些文章:
数据科学家提高Python代码质量指南
10个很棒的开源AI项目——私人AI、代码修复等
ChatGPT代码解释器:这里有10个令人惊叹的用例!
动动小手,几行python代码让你的邮箱自动化又智能!
01# 使用Pandas自带的函数读取大文件
具有讽刺意味的是,第一个错误与实际使用Pandas执行某些任务有关。具体来说,当今现实世界的表格数据集非常庞大。如果把它们解读到你的Pandas环境中将是一个巨大的错误。
为什么?因为它太慢了!下面,我们加载2021年10月的TPS数据集,该数据集有100万行和约300个特征,占用了2.2GB的磁盘空间。
import pandas as pd
%%time
tps_october = pd.read_csv("data/train.csv")
Wall time: 21.8 s10201.py hosted with ❤ by GitHub
这需要大约22秒的时间。现在,你可能会说22秒不算长,但是想象一下,在一个项目中,你将在不同的阶段进行许多实验。你可能会为清理、特征工程、选择模型以及其他任务创建单独的脚本或笔记本。
多次等待数据加载20秒真的会让你心烦。此外,你的数据集可能会更大。那么,有没有更快的解决方案呢?
解决方案是在此阶段放弃Pandas,并使用为快速IO明确设计的其他替代方案。在这个阶段,我最喜欢的是datatable,但你也可以选择Dask、Vaex、cuDF,甚至是polar。下面是用datatable加载相同数据集所需的时间:
import datatable as dt # pip install datatble
%%time
tps_dt_october = dt.fread("data/train.csv").to_pandas()
------------------------------------------------------------
Wall time: 2 s10202.py hosted with ❤ by GitHub
只需2秒!
02# 没有向量
函数式编程中最重要的规则之一就是永远不要使用循环(以及“无变量”规则)。在使用Pandas时坚持这种“无循环”规则似乎是加快计算速度的最佳方法。
函数式编程用递归代替循环。幸运的是,我们不必对自己太苛刻,因为我们可以使用向量计算!
向量计算是Pandas和NumPy的核心,它对整个数组而不是单个标量执行数学运算。最棒的是Pandas已经拥有一套广泛的向量化函数,无须重新设计新的库。
Python中的所有算术运算符(+,-,*,/,**)在Pandas系列或数据帧上使用时都以向量化的方式工作。此外,你在Pandas或NumPy中看到的任何其他数学函数都已经向量化了。
为了看到速度的提高,我们将使用下面的big_function,它将三列作为输入并执行一些无意义的算术:
def big_function(col1, col2, col3):
return np.log(col1 ** 10 / col2 ** 9 + np.sqrt(col3 ** 3))首先,我们将这个函数与Pandas最快的迭代器apply一起使用:
%time tps_october['f1000'] = tps_october.apply(
lambda row: big_function(row['f0'], row['f1'], row['f2']), axis=1
)
-------------------------------------------------
Wall time: 20.1 s这个操作耗时20秒。让我们以向量化的方式使用NumPy数组来做同样的事情:
%time tps_october['f1001'] = big_function(tps_october['f0'].values,
tps_october['f1'].values,
tps_october['f2'].values)
------------------------------------------------------------------
Wall time: 82 ms它只花了82毫秒,大约快了250倍。
事实上,你不可能完全放弃循环。毕竟,并非所有数据操作都是数学运算。但是,当你发现自己渴望使用一些循环函数(如apply、applymap或itertuples)时,请花点时间看看是否可以对任务进行向量化。
03# Data types, dtypes, types!
不,这不是你在中学学到的“更改Pandas列的默认数据类型”课程。在这里,我们将从内存使用的角度讨论数据类型。
最糟糕和最消耗内存的数据类型是object,这也恰好限制了Pandas的一些功能。接下来,我们有浮点数和整数。实际上,我不想列出所有的Pandas数据类型,所以你可以看一下这个表格:
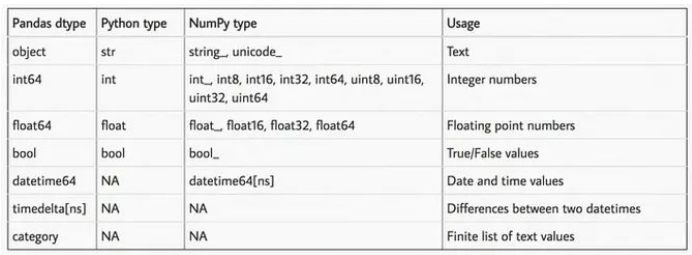
数据类型名称后面的数字表示该数据类型中的每个数字将占用多少位内存。因此,我们的想法是将数据集中的每一列都转换为尽可能小的子类型。你怎么知道该选哪一个呢?这里有另一个表格供你参考。

通常,你希望根据上表将浮点数转换为float16/32,并将包含正负整数的列转换为int8/16/32。你也可以使用uint8来表示布尔值和正整数,以进一步减少内存消耗。
下面是一个方便但很长的函数,它根据上表将浮点数和整数转换为它们的最小子类型:
def reduce_memory_usage(df, verbose=True):
numerics = ["int8", "int16", "int32", "int64", "float16", "float32", "float64"]
start_mem = df.memory_usage().sum() / 1024 ** 2
for col in df.columns:
col_type = df[col].dtypes
if col_type in numerics:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == "int":
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if (
c_min > np.finfo(np.float16).min
and c_max < np.finfo(np.float16).max
):
df[col] = df[col].astype(np.float16)
elif (
c_min > np.finfo(np.float32).min
and c_max < np.finfo(np.float32).max
):
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
end_mem = df.memory_usage().sum() / 1024 ** 2
if verbose:
print(
"Mem. usage decreased to {:.2f} Mb ({:.1f}% reduction)".format(
end_mem, 100 * (start_mem - end_mem) / start_mem
)
)
return df让我们把它用在10月份的TPS数据上,看看我们能减少多少:
>>> reduce_memory_usage(tps_october)
Mem. usage decreased to 509.26 Mb (76.9% reduction)
我们将数据集从最初的2.2GB压缩到510MB。不幸的是,当我们将数据帧保存到文件中时,这种内存消耗的减少就会消失。
为什么这又是一个错误?当使用大型机器学习模型处理此类数据集时,RAM消耗起着很大的作用。一旦遇到一些OutOfMemory错误,你就会开始学习类似这样的技巧来保持计算机正常运行。
04# 不设置样式
Pandas最美妙的特性之一是它能够显示样式化的数据帧。原始数据帧以HTML表格的形式呈现,其中包含一些Jupyter内部的CSS。
对于那些有品味并希望为其笔记本增添色彩和吸引力的人来说,Pandas允许通过样式属性对其数据帧进行样式设置。
tps_october.sample(20, axis=1).describe().T.style.bar(
subset=["mean"], color="#205ff2"
).background_gradient(subset=["std"], cmap="Reds").background_gradient(
subset=["50%"], cmap="coolwarm"
)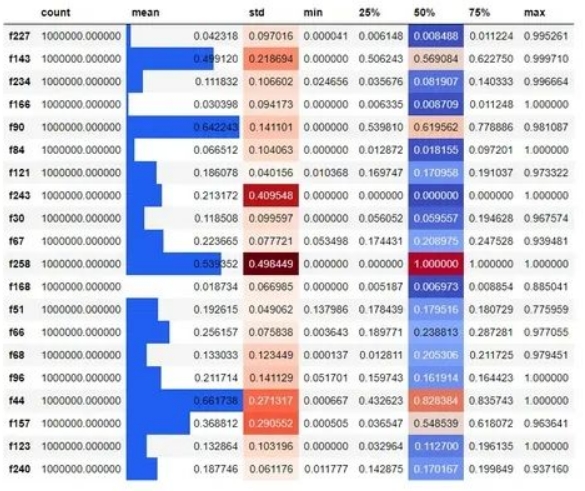
在上面的示例中,我们随机选择20列,为它们创建一个5个数字的摘要,转置结果,并根据它们的大小为平均值、标准差和中位数列上色。
这样的更改可以更容易地在原始数据中发现模式,而无需求助于可视化库。你可以通过此链接了解如何对数据帧进行样式设置的全部细节。
实际上,不对数据帧进行样式化并没有什么错。然而,这似乎是一个很好的功能,不使用它将是一个很大的损失。
05# 使用CSV格式保存文件
就像读取CSV文件非常慢一样,将数据保存回CSV文件也是如此。以下是将TPS 10月数据保存为CSV文件所需的时间:
%%time
tps_october.to_csv("data/copy.csv")
------------------------------------------
Wall time: 2min 43s这个过程花费了将近3分钟的时间。为了节省时间和成本,请将你的数据帧保存为其他轻量级格式,如Feather或Parquet。
如你所见,将数据帧保存为Feather格式所需的运行时间减少了160倍。此外,Feather和Parquet占用的存储空间也少得多。Dario Radecic有一个专门介绍CSV替代品的完整系列,你可以点击这里查看。
06# 不阅读用户指南!
实际上,这个列表中最严重的错误是没有阅读Pandas的用户指南或文档。
我理解。当涉及到文档时,我们都有一种奇怪的心里。我们宁愿在互联网上搜索几个小时,也不愿阅读文档。
然而,对于Pandas来说,就完全不是这样了。它有一个优秀的用户指南,涵盖了从企业用户的基本概念到高级概念的各种主题。
事实上,你可以从用户指南中了解到我今天提到的所有内容。事实上,关于读取大型数据集的部分明确告诉你要使用其他包(如Dask)来读取大文件,并远离Pandas。如果我有时间从头到尾阅读用户指南,我可能会提出50多个针对常见错误的最佳实践方案,但现在你知道该怎么做了,剩下的就交给你了。
07# 总结
今天,我们学习了初学者在使用Pandas时最常犯的六个错误。如果你还在处理小数据集,你可能会忘记它们,因为这些解决方案不会有太大的不同。然而,当你提高技能并开始处理现实世界的数据集时,这些概念最终将是有益的。
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Bex T.
翻译作者:文玲
美工编辑:过儿
校对审稿:Chuang
原文链接:https://pub.towardsai.net/6-pandas-mistakes-that-silently-tell-you-are-a-rookie-f075c91595e9





