
如何让你的Pandas函数更有用?
可以说,Pandas是数据科学系统中最常用的库。它的功能让复杂的数据清理和分析任务变得简单。但是,我们大部分人都会用默认设置的 Pandas 功能,这让我们无法充分利用它们。在大多数情况下,参数可以让函数们更灵活、更强大。
此外,通过正确使用参数,我们可以在一个步骤中完成包含多个步骤的任务。作为结果,我们的代码会变得更加高效和干净。
在本文中,我们将通过一些实际案例来展示使用参数的好处。如果你想了解更多数据分析相关内容,可以阅读以下这些文章:
数据分析新工具MindsDB–用SQL预测用户流失
DS数据科学家和DA数据分析师:要学习什么不同内容?
数据分析师需要知道的10个Excel函数
数据分析如何在Fintech中发挥作用?
让我们从导入库和创建DataFrame 开始。
import pandas as pd
import numpy as np
import random# create a DataFrame with mock data
pg = ["A","B","C","D","E","F","G"]
sales = np.arange(1,1000)df = pd.DataFrame({"product_group":random.choices(pg, weights=[12,10,8,5,1,1,1],k=300),
"product_code":np.arange(1000,1300),
"sales_qty":random.choices(sales, k=300)})# add some missing values
df.loc[150:170, "product_group"] = np.nan
df.loc[210:230, "sales_qty"] = np.nan
我们的DataFrame中,包含了一些产品、产品组、以及随机生成的销售数量。
假设我们要计算每组中的产品数量。最简单的方法是value_counts函数。
df["product_group"].value_counts()# output
A 88
B 69
C 56
D 37
F 11
E 9
G 9
Name: product_group, dtype: int64我们的列中应该有一些缺失值,但在输出结果中看不到它们。这种情况的原因是value_counts函数会默认忽略缺失值。
在某些任务中,忽略缺失值可能会产生数据的误导。当然,我们可以用isna函数检查缺失值。但是, value_counts函数其实可以为我们提供缺失值的信息。我们只需要改变dropna的范围。
df["product_group"].value_counts(dropna=False)# output
A 88
B 69
C 56
D 37
NaN 21
F 11
E 9
G 9
Name: product_group, dtype: int64可以看到,缺少产品组信息的产品有 21 个。
现在,我们来回顾一下输出结果。可以看到,A组有88个产品。
A 组有最多的产品,但 A 在整个DataFrame中所占的百分比是多少?我们可以通过简单的数学运算来计算它,但有一种更简单的方法:normalize参数。
df["product_group"].value_counts(normalize=True, dropna=False)# output
A 0.293333
B 0.230000
C 0.186667
D 0.123333
NaN 0.070000
F 0.036667
E 0.030000
G 0.030000
Name: product_group, dtype: float64A 组占整个产品系列的 29%。
改变normalize 参数对许多任务都很方便。假设我们正在处理一项任务,并且只想包含产品中 75% 的产品组。我们可以用value_counts和cumsum函数,轻松找到范围内的产品组,如下所示:
df["product_group"].value_counts(normalize=True).cumsum()# output
A 0.315412
B 0.562724
C 0.763441
D 0.896057
F 0.935484
E 0.967742
G 1.000000
Name: product_group, dtype: float6476% 的产品属于产品组 A、B 或 C。你可能已经注意到,这里的百分比份额和前面的示例不同。这是因为我们这次忽略了缺失值。
对观察结果进行排序也是一项非常常见的任务,可以用 Pandas 的sort_values函数来完成。让我们根据销售数量按降序对行进行排序。
df = df.sort_values(by="sales_qty", ascending=False)
df.head()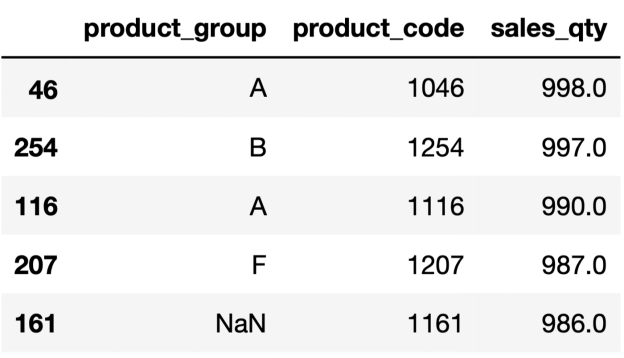
输出结果中的索引和DataFrame中的索引相同。在很多情况下,这可能不是问题,但最好有一个更适当的索引。我们可以使用reset_index函数更新索引,但sort_values函数有一个用于此任务的参数:ignore_index 。
df = df.sort_values(by="sales_qty", ascending=False, ignore_index=True)
df.head()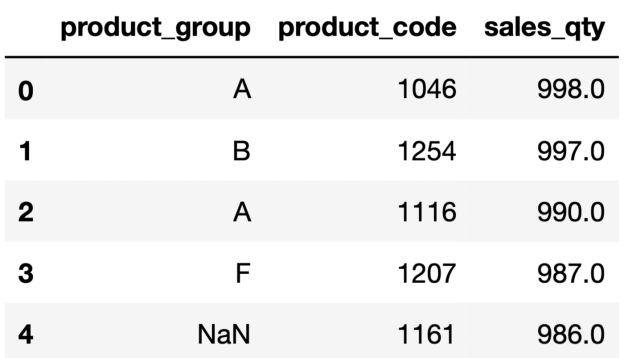
现在看起来好多了。
小技巧:用来组合多个DataFrame的concat函数也有ignore_index参数。
groupby是数据分析中最常用的 Pandas 函数之一。它根据给定列中的不同值对行进行分组。然后我们可以计算每个组的合计值。
例如,我们可以计算每个组的平均销售量:
df.groupby("product_group").agg(avg_sales=("sales_qty","mean"))
# output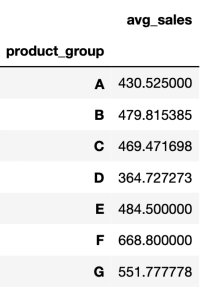
这个命令的输出是一个DataFrame ,产品组作为索引显示。但是,把产品组单独放在DataFrame中的一列中会更好、更实用。这在我们有嵌套组时(按多列分组时)会特别有用。
我们也可以用reset_index函数,将组从索引带到新列。但其实, groupby函数专门为这个目的提供了一个参数:as_index 。
df.groupby("product_group", as_index=False).agg(avg_sales=("sales_qty","mean"))
# output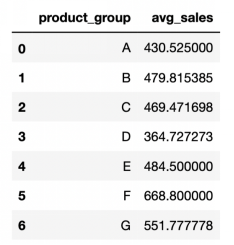
新的结果看起来好多了,因为后面的分析我们可能需要用到产品组的列。
本文中,我介绍了一些可以改变函数行为的参数。它们帮助我们添加新功能、或者调整功能来更好地满足我们的需求。这几个参数使函数更加灵活、实用和有用。我强烈建议你在运行函数之前检查参数,让你的代码更加整洁、灵活、高效。感谢你的阅读!你还可以订阅我们的YouTube频道,观看大量数据科学相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Soner Yıldırım
翻译作者:Jiawei Tong
美工编辑:过儿
校对审稿:Jiawei Tong
原文链接:https://towardsdatascience.com/how-to-make-pandas-functions-more-useful-25649f71cc21





