
Python使用者必看!简明指南教你使用OpenAI API
立即学习如何使用 OpenAI API!

立即学习如何使用 OpenAI API!
通过立即学习 OpenAI API,你将能够访问OpenAI的强大模型,例如用于自然语言任务的 GPT-3、将自然语言转换为代码的Codex以及用于创建和编辑原始图像的DALL-E。
在本指南中,我们将学习如何将OpenAI API与Python一起使用。如果你想了解更多关于数据科学的相关内容,可以阅读以下这些文章:
数据科学家订阅ChatGPT三周体验:每天节省3小时工作时间!
没有经验?一样能获得数据科学实习机会
14场Kaggle比赛,开启你的数据科学之旅
如何从数据分析师过渡到数据科学家的角色?
首先要做的是—生成你的API密钥(https://beta.openai.com/account/api-keys)
在我们开始使用OpenAI API之前,我们需要登录我们的OpenAI帐户并生成我们的API密钥。
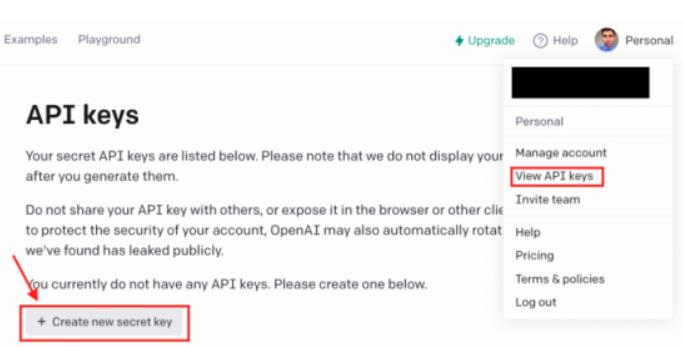
请记住,OpenAI 在你生成私有API密钥后不会再次显示它,因此请复制你的API密钥并保存它。
我将创建一个名为OPENAI_API_KEY的环境变量,该变量将包含我的API密钥,并将在下一节中使用。
使用Python探索OpenAI API
要与OpenAI API交互,我们需要通过运行以下命令来安装官方的Python库。
pip install openai我们可以用这个API做很多事情。在本指南中,我们将进行文本补全、代码补全和图像生成。
1 文本补全
文本补全可用于分类、文本生成、对话、转换、转换、摘要等。要使用它,我们必须使用完成终点并为模型提供提示。然后,模型将生成尝试匹配给定上下文/模式的文本。
假设我们要对以下文本进行分类。
确定推文的情绪是积极的、中立的还是消极的。
推特:我不喜欢新的蝙蝠侠电影!
情绪:
以下是我们将如何使用OpenAI API执行此操作:
import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
prompt = """
Decide whether a Tweet's sentiment is positive, neutral, or negative.
Tweet: I didn't like the new Batman movie!
Sentiment:
"""
response = openai.Completion.create(
model="text-davinci-003",
prompt=prompt,
max_tokens=100,
temperature=0
)
print(response)根据 OpenAI 文档,GPT-3模型旨在与文本完成端点一起使用。这就是为什么我们在本例中使用模型text-davinci-003。
这是打印输出的一部分。
{
"choices": [
{
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"text": "Negative"
}
],
...
}在此示例中,推文的情绪被归类为负面。
让我们看一下此示例中使用的参数:
model:要使用的模型的ID(在这里你可以看到所有可用的模型)
prompt:生成完成的提示
max_token:完成中要生成的最大令牌数(在这里你可以看到 OpenAI 使用的标记器:https://beta.openai.com/tokenizer)
temperature:要使用的采样温度。接近1的值将赋予模型更多的风险/创造力,而接近0的值将生成明确定义的答案。
你还可以分别使用completion和edit endpoint插入和编辑文本(https://beta.openai.com/docs/guides/completion/editing-text)。
2 代码完成
代码完成的工作方式与文本完成类似,但此处我们使用 Codex 模型来理解和生成代码。
Codex模型系列是经过自然语言和数十亿行代码训练的GPT-3系列的后代。借助 Codex,我们可以将注释转换为代码,重写代码以提高效率,等等。
让我们使用模型code-davinci-002 和下面的提示生成 Python 代码。
创建洛杉矶天气温度阵列
import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
response = openai.Completion.create(
model="code-davinci-002",
prompt="\"\"\"\nCreate an array of weather temperatures for Los Angeles\n\"\"\"",
temperature=0,
max_tokens=256,
top_p=1,
frequency_penalty=0,
presence_penalty=0
)
print(response)这是打印输出的一部分。
{
"choices": [
{
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"text": "\n\nimport numpy as np\n\ndef create_temperatures(n):\n \"\"\"\n Create an array of weather temperatures for Los Angeles\n \"\"\"\n temperatures = np.random.uniform(low=14.0, high=20.0, size=n)\n return temperatures"
}
],
...
}
}如果你为生成的文本提供正确的格式,你会得到这个。
import numpy as np
def create_temperatures(n):
temperatures = np.random.uniform(low=14.0, high=20.0, size=n)
return temperatures你可以做更多的事情,但首先我建议你在Playground测试Codex(这里有一些例子可以帮助你入门:https://beta.openai.com/docs/guides/code/quickstart)
此外,我们应该遵循最佳做法,最大限度地发挥Codex的作用。我们应该在说明中指定要使用的语言和库,在函数中放置注释,等等。
3 图像生成
我们可以使用 DALL-E 模型生成图像。为此,我们必须使用图像生成端点并提供文本提示。
这是我们将使用的提示(请记住,我们在提示中提供的详细信息越多,我们就越有可能获得所需的结果)。
一只毛茸茸的白猫,蓝色的眼睛,坐在花篮里,可爱地抬头看着镜头。
import openai
response = openai.Image.create(
prompt="A fluffy white cat with blue eyes sitting in a basket of flowers, looking up adorably at the camera",
n=1,
size="1024x1024"
)
image_url = response['data'][0]['url']
print(image_url)打开打印的URL后,我得到了以下图像。

但这还不是全部!你还可以使用图像编辑和图像变体端点编辑图像并生成给定图像的变体。(https://beta.openai.com/docs/guides/images/usage)
现在就是这样!如果你想检查可以使用OpenAI API执行的更多操作,请查看其文档(https://beta.openai.com/docs/introduction)。
感谢阅读。你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:The PyCoach
翻译作者:马薏菲
美工编辑:过儿
校对审稿:Chuang
原文链接:https://artificialcorner.com/a-simple-guide-to-openai-api-with-python-3bb4ed9a4b0a





