
作为一个数据科学家/分析师,不要重复这5个编程错误
在我目前担任数据科学经理的职位上,我与多位数据科学家一起工作,我发现他们中的许多人在处理大数据时犯了一些基本的数据处理错误(我也曾经犯过其中一些错误!)。这些错误会导致代码执行时间急剧增加,有时还会导致大量的返工和浪费精力。
在这篇文章中,你将了解到如果想成为一个更好(更高效)的数据科学家,你应该避免的5大编程错误。如果你想了解更多关于数据科学的相关内容,可以阅读以下这些文章:
数据科学家订阅ChatGPT三周体验:每天节省3小时工作时间!
没有经验?一样能获得数据科学实习机会
14场Kaggle比赛,开启你的数据科学之旅
如何从数据分析师过渡到数据科学家的角色?
处理大数据时要避免的5大错误
1 在不知道数据级别/主键的情况下连接数据集
数据级别定义为每行具有唯一值的列或列组合。数据级别通常由某些ID变量(如客户ID)定义。让我们通过示例来理解这一点:
i. 单列作为级别:在下面的数据集中,订单ID列没有两行具有相同的值,因此订单ID是此数据集的数据级别(主键)。
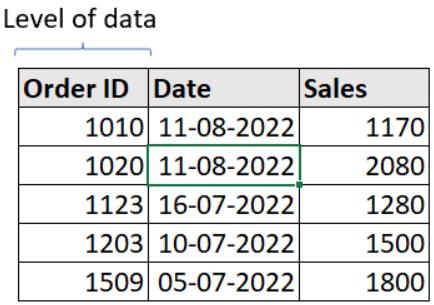
连续列(如“销售额”)不能定义为数据级别。
ii. 多列作为级别:在下面的数据集中,我们可以看到多行的订单ID是相同的,所以它不是这个数据集的级别。如果我们仔细观察,可以看到没有两行的订单ID和产品ID组合具有相同的值,因此这两列都是此数据集的数据级别(主键)。
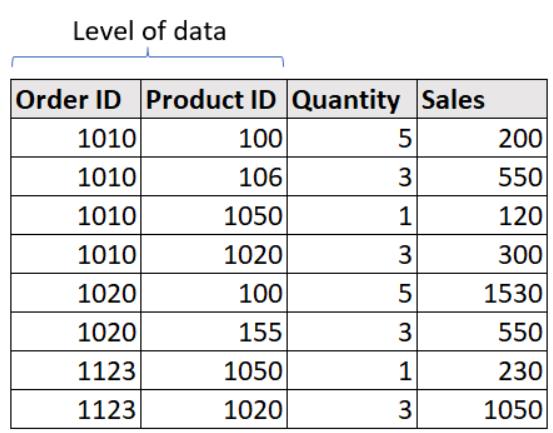
在执行联接时,了解数据级别变得非常重要,因为联接主要在数据集的主键上执行。
在非主键上联接数据集可能会导致错误的结果。
2 不过滤所需行
有时,数据科学家不会在查询开始时筛选所需的行,而是等到最后一个查询来筛选行。在处理大数据时,这是一种犯罪,因为它大大增加了执行时间,特别是如果你正在应用复杂的操作(如连接)。
不良做法
- 步骤 1:转换数据
- 步骤 2:应用联接操作
- 步骤 3:更多转换
- 步骤 4:筛选行
良好做法
- 步骤 1:筛选行
- 步骤 2:转换数据
- 步骤 3:应用联接操作
- 步骤 4:更多转换
3 使用大量联接/自联接
自连接就像一把双刃剑,如果你适当地使用它们,它们可能是一个福音,但如果你太频繁地使用它们,那就是一个祸根,因为加入是分布式环境中代价最高的任务,如Hadoop,Hive,Spark等。
想象一下,我们有关于组织内员工工资的数据。
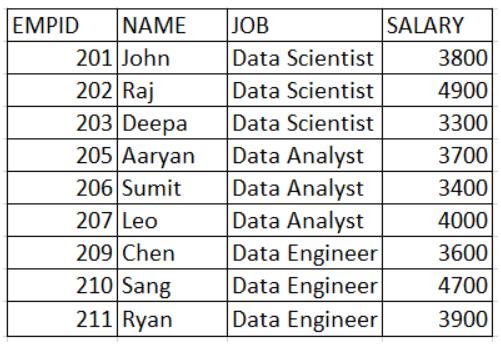
我们希望添加一列,其中包含与当前行(数据科学家、数据分析师、数据工程师)对应的工作角色中所有员工的总工资。我们希望输出如下所示:
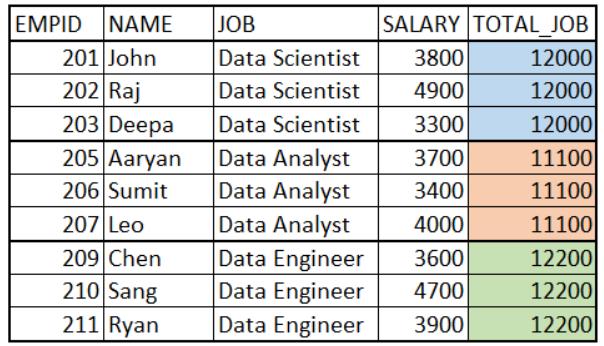
你会使用自联接来获取上述输出吗?这是最好的方法吗?
不,自连接不是获取此输出的最佳解决方案,而是我们应该使用window函数来获取所需的结果(如下所示)。
不良做法
## Using Joins
select a.EMPID, a.NAME, a.JOB, b.TOTAL_JOB
FROM employee_table a
INNER JOIN
(select EMPID, NAME, sum(SALARY) as TOTAL_JOB
FROM employee_table
GROUP BY EMPID, NAME) b
on a.EMPID = b.EMPID
and a.NAME = b.NAME良好做法
## Using the window function
select EMPID, NAME, JOB, SALARY,
sum(SALARY) over() as TOTAL
FROM
employee_table4 不筛选必填列
在处理具有数百万行的大型数据集时,数据集中的列数超过所需列可能会导致运行时间增加。因此,建议在读取数据集时仅选择所需的列。
不良做法
### Selecting all the columns #######
select a.*, b.*
from
member_data as a
join
claims_data as b
on a.member_id = b.member_id良好做法
### Selecting the required columns
select a.member_id, a.age,
a.address, b.claim_id
from
member_data as a
join
claims_data as b
on a.member_id = b.member_id5 每次查询后不进行质量检查
质量检查对于及时发现错误并确保我们提供正确的输出非常重要。很多时候,我们跳过这一步,并在分析的后期发现最终结果不正确,因此我们必须进行大量回溯以找到错误的根本原因,然后重新运行查询。这导致分析的周转时间急剧增加。
为了避免上述问题,我们可以按照以下简单步骤对数据集执行质量检查:
- 计算查询的输入行/列数和输出行/列数,并确保获得预期的行/列数。
- 检查操作列上的汇总统计信息(非重复值、百分位数等)。这将确保您在列中获得预期值。
- 检查数据集的前几行。这就像检查行样本以推断数据集的正确性。
在评论中分享你在处理数据时执行的质量检查步骤。
总结
我们研究了通过增加分析周转时间来降低数据科学家工作效率的一些常见错误。
我们可以通过了解我们的数据(数据级别)、只处理所需的行和列、不使用多余的连接以及对我们的查询执行质量检查来克服这些错误。
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Anmol Tomar
翻译作者:马薏菲
美工编辑:过儿
校对审稿:Chuang
原文链接:https://towardsdatascience.com/avoid-these-5-programming-mistakes-as-a-data-scientist-analyst-4b7017d509fe





