各算法原理概述")
推荐系统(Recommender Systems)各算法原理概述
在本文中,我概述了推荐系统的广泛领域,并解释了各个算法的工作原理。
我将从定义开始。推荐系统是部署在将商品(产品,电影,事件,文章) 推荐给用户(客户,访客,应用程序用户,读者)或相反对象的环境中的一种技术。通常,环境中存在许多物品和许多用户,导致该问题解决难度大且昂贵。想象一下一家商店,好商人知道顾客的个人喜好,她/他的高质量推荐会使客户满意并增加利润。如果是线上营销和购物,则可以由人工商家生成个人推荐,也就是推荐系统。

要构建推荐系统,您需要关于商品和用户的数据集,理想情况下还需要用户与商品的交互数据。有许多应用程序域 — 通常,用户是客户,物品产品和交互是个人购买行为。在此图中,用户是持卡人,商品是卡终端,交互是购物交易。从此类数据集中,可以生成规则,以显示用户如何与商品进行交互。在这种情况下,可以使用基于捷克共和国卡交易的规则来为客户推荐要参观的商店。
基于知识的推荐系统(Knowledge based recommender systems)
用户和商品都具有属性。您对用户和商品的了解越多,预期的效果就越好。下面,我举一个与推荐相关的商品属性示例:
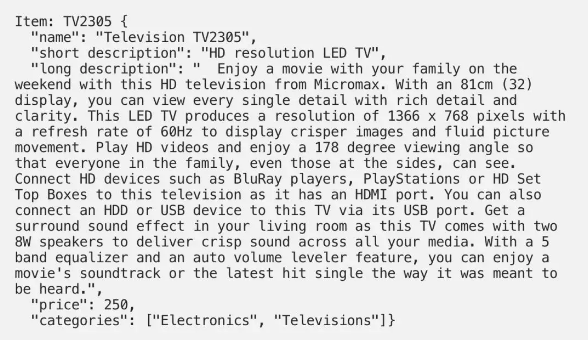
这些属性非常有用,并且可以使用数据挖掘的方法以规则和模式的形式来提取知识,随后将其用于推荐。例如,上面的商品由可用于测量商品相似性的几个属性表示,长文本描述也可以通过高级NLP(自然语言处理)工具进行处理。然后,基于商品相似性生成推荐。如果也用相似的属性(例如,从求职者的简历中提取的文字)来描述用户,则可以根据用户与商品的属性相似性来推荐商品。请注意,在这种情况下,我们根本不使用过往的用户交互。因此,这种方法对于所谓的“冷启动”(”cold start”)用户和商品非常有效,那些通常是新用户和新商品。
基于内容的推荐系统(Content based recommender systems)
这样的系统推荐与指定用户过去喜好相似的商品,而不管其他用户的偏好如何。基本上,有两种不同类型的反馈。
显示/明确反馈是指用户特意点击“喜欢” /”不喜欢”按钮,通过标星数给产品服务打分,等等。在许多情况下,明确的反馈数据是很难获取的,仅仅是因为用户不愿意提供。他/她宁愿离开网页或切换到另一个电视频道,也不愿对用户认为不感兴趣的商品单击“不喜欢”。
但是,隐式反馈数据(例如“用户查看了商品”,“用户阅读完文章”或“用户订购了产品”)通常更容易收集,也可以帮助我们计算出良好的建议。各种类型的隐式反馈可能包括:
· 互动(隐式反馈):
o 用户查看了商品
o 用户查看了商品的详细信息
o 用户将商品添加到购物车
o 用户购买了商品
o 用户已阅读完文章
同样,当获得的反馈丰富时,您可以期待推荐系统会有更好表现。
基于内容的推荐系统仅作用于给定用户的过往交互行为,而没有考虑其他用户。比较流行的方法是计算最近的几个商品的属性相似度,并推荐相似项。在这里,我需要指出一项有趣的观察,推荐最近的商品本身通常就是非常成功的策略,当然它仅在某些领域和某些职位上有效。
协同过滤(Collaborative filtering)
最后一组推荐算法是基于整个用户群的过去交互。当很好地定义了“近邻”(“neighbors”)并且交互数据很整洁时,这种算法比前几节中描述的算法要精确得多。

上述基于近邻的算法(K-NN)是非常简单且流行的。为了构建对用户的推荐,k个最近的邻居用户(排名情况最相似)会被检查。然后,前N个未被排名的额外商品会被推荐。
这种方法不仅适用于主流用户和流行商品,还适用于“长尾”(“long-tailed”)用户。通过控制要考虑推荐的近邻数量,可以优化算法并在推荐畅销商品和小众商品之间找到平衡。良好的平衡对于系统的性能至关重要,这将在本文的第二部分中进行讨论。
近邻算法有两种主要的变体。在基于商品的(item-based)和基于用户(user-based)的协同过滤。两种算法都在用户-商品的评分矩阵上运行。
在基于用户的方法中,对于用户u, 通过组合类似于u的用户的评级来生成未评级商品的分数。
在基于商品的方法中,通过查看类似于i的一组商品(交互相似性)来产生评分(u,i),然后将相似商品的u评分组合为预测评分。
基于商品的方法的优势在于,商品相似性更加稳定,可以有效地进行预先计算。
根据我们的经验,在大多数方案和数据库中,基于用户的算法要优于基于商品的算法。唯一的例外是商品数比用户少得多且交互数少的数据库。

K最近邻算法不仅是协同过滤问题的解决方案。上面的基于规则(rule-based)的算法使用APRIORI方法从交互矩阵生成规则集。具有足够支持的规则随后可用于生成建议的候选。
K-NN和基于规则的算法之间的重要区别是学习和召回的速度。机器学习(machine learning)模型分两个阶段运行:在学习(learning)阶段构建模型,在召回(recalling)阶段将模型应用于新数据。基于规则的算法训练起来很昂贵,但是召回速度很快。K-NN算法正好相反-因此也被称为惰性的学习者。在推荐系统中,(在每次用户交互之后)经常更新模型是很重要的,以便能够立即生成新的推荐。懒惰的学习者易于更新,而基于规则的模型则必须重新训练,这在大型生产环境中尤其具有挑战性。
在Recombee中,我们设计了一个基于规则的推荐的惰性变体,使我们能够即时挖掘规则并通过传入的交互立即更新模型。

规则可以可视化,它是检查数据库中数据质量和问题的好工具。该图显示了在交互矩阵中具有足够支持的规则。每个箭头都是一个规则(或暗示),即有足够的用户与源商品以及随后与目标商品进行交互。连接的力量是可信度(confidence)。

这些特定规则是根据银行提供的卡交易数据生成的。商品是“卡终端”,用户是“卡持有者”,互动是个人交易。我们省略标签是因为数据是机密的,并且很多可以从规则中导出。在第一张图中,规则簇(clusters of rules)很明显,这些显然是靠近其地理位置的卡终端。有一些有趣的规则可以显示用户的购物习惯。当您将数据上传到我们的推荐器时,我们可以为您生成此类规则,并且您可以检查自己数据中的有趣规则。
但是上述规则的主要目的不是数据分析,而是推荐。由此可以根据持卡人的近期交易为他们提供建议(例如,从此ATM提款的人通常将其用于以下商店)。银行可以在此类建议的基础上构建智能数据产品(例如,为在推荐地点购物提供奖金)。这样的数据产品几乎可以在任何地方生成。您是否想到,以数据推荐为基础的数据产品会如何改善您的业务?我们可以帮助您进行验证。

这里描述的最后一类,也许是最有趣的协同过滤算法是基于分解的方法(factorization based approaches)。上面,交互矩阵分解为两个小矩阵,一个用于用户,一个用于具有一定数量潜在成分(通常为数百个)的商品。通过将这两个小矩阵相乘获得(u,i)等级。有几种方法可以分解矩阵并对其进行训练。上面显示的是一种简单的梯度下降(gradient descent)技术。可以通过Stochastic Gradient Descent,Alternating Least Squares或者Coordinate Descent Algorithm将误差最小化。还有基于SVD的方法,将排名矩阵分解为三个矩阵。
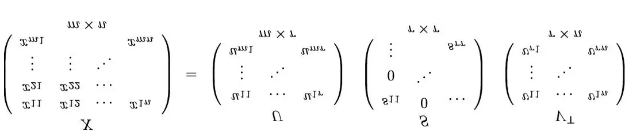
如您所见,每个算法都有参数可以帮助我们找到模型的良好可塑性。
如何衡量算法的质量?这是另一个复杂的问题。
一般而言,“错误”建议很难被发现和预防。他们通常是限定于领域的,需要被过滤掉。
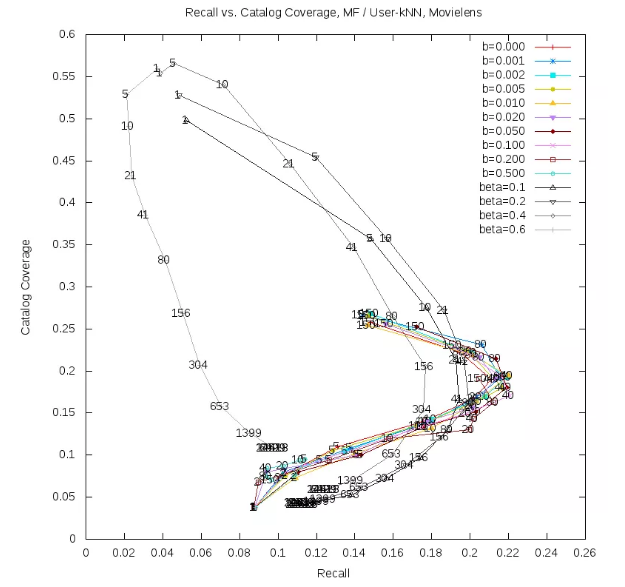
推荐算法的离线评估,显示了基于ALS的矩阵分解可以如何胜过基于用户的K-NN。
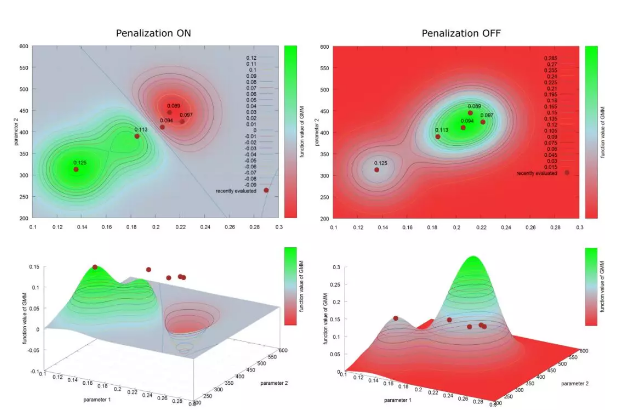
我们有几种策略可以对推荐进行离线和在线评估。在Recombee中,准确的质量估算可以帮助我们自动优化系统参数,并针对所有情况提高推荐程序的性能。
· 原作者: Pavel Kordik
· 翻译: Cloris Li





