
如何在15分钟内构建属于自己的基于聚类的推荐系统?
推荐引擎是当前互联网时代最受欢迎的机器学习技术应用之一,并广泛用于电子商务网站、推荐类似产品和电影推荐网站等场景。推荐系统负责为我们生成各种私人订制。它可以提高用户更多内容的参与度,从而带来更好的用户体验和为企业带来更多收入。在当今的行业发展中起到了至关重要的作用。
推荐引擎简单来讲就是过滤数据并向用户推荐最相关的结果。推荐这些结果的方式使得对结果感兴趣的可能性最大。现在,所有推荐引擎都有用户数据及其历史记录,可用于创建过滤算法,并最终帮助公司为每个独特用户生成非常准确的建议。
在协同过滤(collaborative filtering)中,“User Behavior”(用户行为)被用于建立推荐系统。可以利用“用户 – 用户”之间的相似性或基于“项目 – 项目”相似性来生成某些推荐。并且基于该相似性度量,向用户提供建议。但是,我们仍然需要考虑一下当我们无法获得用户数据的情况:这时,如果我们仍然需要向用户推荐某些项目的情况该怎么办呢?
现在给用户做推荐的问题简单地转变为类似聚类的问题。相似性度量基于“两个项目有多接近,同时生成建议”。用于生成推荐的度量将基于两个项目的相似性,例如这些项目之间的向量距离。我们将对Pluralsight的在线课程文本数据进行讨论,根据我们可用的商品数据制作推荐系统。
1. 介绍:了解你的数据
用于项目的数据是在Pluralsight网站上的课程。如需获取课程数据只需运行下面提到的ReST API查询的技术。但是为了获得用户注册数据,基于协作过滤器的引擎首先我们要获取文档中提到的ReST api-token,然后生成ReST查询以获取有关此网站上所有课程以及注册其中的相应用用于项目的数据是在Pluralsight网站上的课程。如需获取课程数据只需运行下面提到的ReST API查询的技术。但是为了获得用户注册数据,基于协作过滤器的引擎首先我们要获取文档中提到的ReST api-token,然后生成ReST查询以获取有关此网站上所有课程以及注册其中的相应用
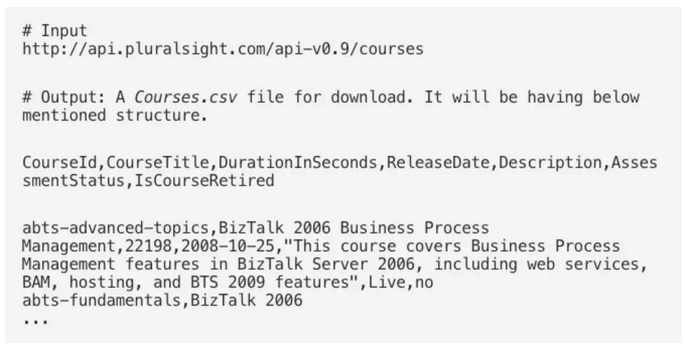
在本文中,我们用仅限于发动机构造的课程数据。通过查看这些数据,我们观察了在训练模型时非常重要的以下几点。您可以打开Courses.csv文件并自行进行以下观察。
- 课程数据的文本描述存在于CourseId,课程标题和课程描述还有columns。在构建我们的推荐系统时这些列是非常有意义的。利用这些列中的文本数据,我们将能够构建在预测结果时由我们的模型使用的文字向量。此外,大多数信息仅出现在“说明”列中。因此,我们将没有描述的课程将从训练集中删掉。
- ‘IsCourseRetired’栏目描述了网站上当前的课程状态, 举个例子: 目前网站上是否提供某个课程。因此,我们不希望从我们的模型中推荐已经结课的课程。但我们绝对可以在我们的训练数据中使用它们。
- 此外,继续讨论有关此数据的预处理。显然,数据中存在一些额外的“- ”标记,不同的案例和停用词。我们将相应地预处理我们的文本,并仅关注名词及名词 – 短语。
2. 建筑设计:构建实用工具
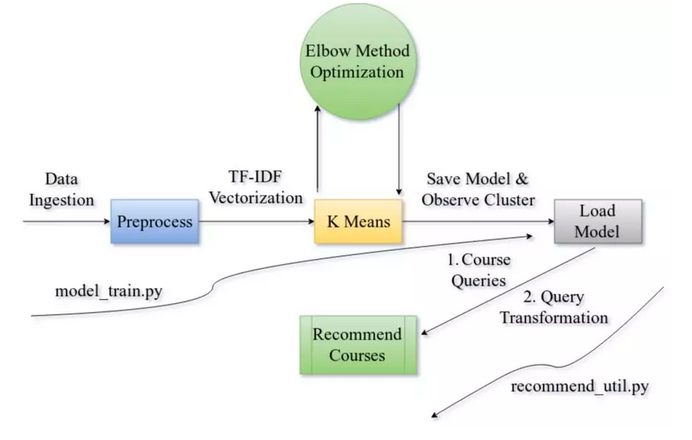
下图清楚地说明了我们这个数据科学项目的pipeline。请按从左到右的顺序阅读。
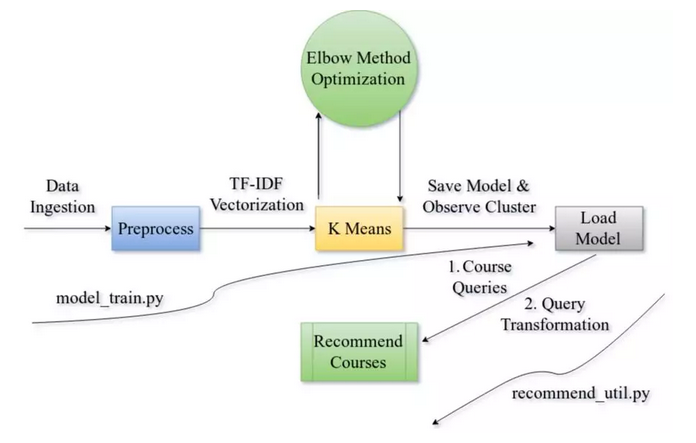
该工具主要分为三个部分,我们将在后面的部分中详细讨论细节。我们将训练模型并对其进行优化以减少误差,并对实用工具进行编码,该工具将根据唯一课程ID的输入查询生成建议。
让我们先转到预处理步骤,开始为我们的模型处理数据提取数据。
3. 预处理步骤
按照下面的代码片段,我们将在其中执行一些小文本预处理,例如删除所有标点符号。此外,在很多术语中,“ll”用于我们将要使用的情况等。这些也会从“描述”文本中删除。我们还将删除停用词并以适当的方式组合:包含描述,课程ID,标题的列。请参阅下面的代码段,按照上述步骤进行操作。

在对上述数据执行基本清洁步骤后,’comb_frame’包含与课程相关的所有必要的单词描述。之后,让我们转向这个文本的矢量化并训练我们的模型。
4. 问题讨论,模型训练和优化
现在,我们将所有必需的文本数据存在于单个数据中。但是,我们需要将其转换为有意义的形态以便让它可以以正确形态输入到我们的机器学习模型中。
为此,我们使用tf-idf权重表示文字在文档中的重要性。它是文档中单词重要性的统计度量。该权重与单词不仅在语料库中出现的次数有关,而且与语料库中单词的频率相关。
tf-idf权重中的Tf测量文档中术语的频率,并且idf衡量给定语料库中给定术语的重要性。这可以从下面提到的公式推断出来。

我们将使用scikit learn将我们的文本数据转换为上述公式中指定的矢量矩阵。请按照下面的代码段进行此转换。

在此之后,我们可以将这些数据直接输入我们的k-means算法。但是,对于我们的k-means算法,我们将需要’k’的值。我们可以使用k = 8作为首个值来测试,因为Pluralsight具有八种不同类型的课程的类别,并且相应地训练我们的模型的预测能力。请按照下面提到的代码片段进行操作。

我们可以观察每个聚类中的顶部的单词,看看形成的聚类是否定性良好,或者在某种意义上它们是否需要改进。运行下面提到的片段,以观察形成的每个群集中的顶部单词。

在观察完这些单词之后,你可能会注意到所有形成的集群都不是很合适,并且一些课程类别正在多个集群上重复(请参阅README.md文件)。对于第一次k值的实验来说这仍然很好,我们的模型已经将更广泛的课程类别细分为其他子类别。给定类别的课程数量的基数问题暴露出来了,但我们的这个模型无法应对。
我们可以看到,细分类别的图形艺术,电影设计,动画由’创意 – 专业’类别组成。这些子类别形成为课程类别中的数据不是等分布的,即与数据的基数有关。因此,课程类别如“商务专业”,课程数量较少,因为经常发生的商业相关术语容易失去它的重要性,机器学习模型中的对此类术语的训练就因此减少。
因此,通过进一步划分为其他群集,可以进一步划分具有较少课程数量的较小课程类别来改进从该方法导出的群集。因为这些进一步的划分可以被表述为具有误差最小化的优化问题。我们不想过度拟合我们的模型,因为我们将使用’elbow-test’方法来找到理想的k值。这个想法是,当给定的’k’值出现误差急剧下降时,该值足以形成簇。这些形成的簇将具有错误的尖锐最小值,并将为我们的模型提供令人满意的解决方案。按照下面提到的代码对我们的数据进行测试。

在运行上面的代码之后,我们得到了下面的图表,在此基础上我们训练了k = 30的模型。并为我们的推荐引擎工具实现了相对更好的集群。
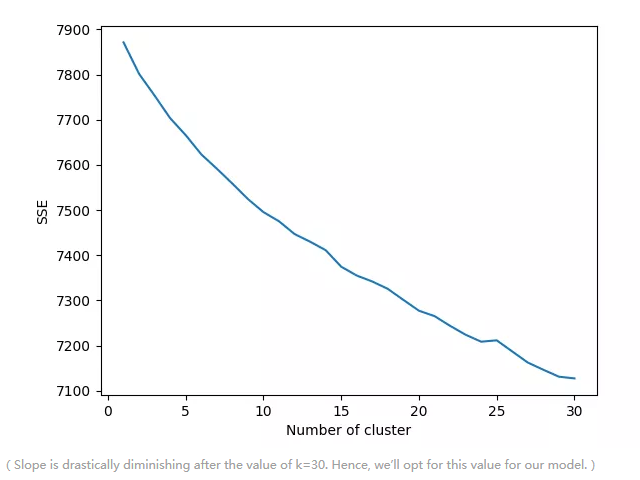
(Slope is drastically diminishing after the value of k=30. Hence, we’ll opt for this value for our model.)
最后,让我们保存我们的模型,继续我们的推荐实用程序脚本并讨论未来的改进方法。所有这些提到的片段都以model_train.py的形式提供,您可以将其引用以直接执行。请提取courses.csv数据文件。

5. 创建推荐系统
我们将为此推荐模块创建一些实用程序功能。cluster_predict函数,它将预测输入到其中的任何描述的集群。首选输入是我们之前在model_train.py文件中的comb_frame中设计的“Description”之类的输入。

之后,我们将根据新数据列中的描述向量为每个课程分配类别,即“ClusterPrediction”。见下文。

我们将为仅具有直播课程的数据框存储该群集类别分数,即删除具有“否”实况的课程。之后,我们将为数据框和存储集群类别中的每个课程运行我们的预测函数实用程序。这些存储的类别将在未来与输入查询及其预测类别进行匹配,以生成建议。

最后,推荐效用函数将预测具有course-id的输入查询的课程类别,并将推荐来自上述变换数据帧’course_df’的几个随机课程,其具有每个课程的预测值。

使用给定的以下查询测试训练有素的推荐引擎。您也可以通过从courses.csv中选择课程ID来添加您的查询。

结论和未来的改进:
推荐引擎的当前实现本质上是非常简单的。对于形成集群的方法而言,给出了使用K-mean集群算法实现这些想法。此外,所产生的建议本质上是随机的,可以采用更具体的方法,如基于最高评分的推荐方法作为改进。
从根本上说,为了将来的改进,可以改变用于培训的类别分配机制和模型。可以采用更多、更先进和复杂的主题建模机制,如Latent Dirichlet Allocation(LDA)。Topic modeling是NLP的统计分支,它从文档集合中提取摘要。我们将使用LDA,它将特定主题分配给特定主题,并使用与相应主题的单词相关联的实数重量分数。
原文作者:Ashish Rana
翻译作者:Zihao Wang
美工编辑:悦
校对审稿:Dongdong





