
Apache Spark——一个灵活的数据处理框架
Apache Spark和MapReduce是两种最常见的大数据处理框架。在这篇文章中,我们将一起研究 Spark的特性,并展开讨论它与MapReduce相比的具体优势。如果你想了解更多数据分析相关内容,可以阅读以下这些文章:
Spark/Hadoop/MapReduce入门101
使用 PySpark 和 MLlib 构建线性回归预测波士顿房价
数据科学和人工智能岗位有何差别?
“数据全才”心酸职场求生指南
MapReduce采用拆分-应用-合并的策略进行数据分析,把拆分后的数据存储到集群的磁盘上。相比之下,Spark在其数据存储之上使用内存,可以在整个集群中并行地加载、处理数据。比起MapReduce,Spark更有速度优势,因为它的数据分布和并行处理是在内存中完成的。
功能特点
- 高速(Speed)→因为它是内存处理的
- 缓存(Caching)→Spark有一个缓存层来缓存数据,加速处理进程
- 部署(Deployment)→可以部署在Hadoop集群或自己的Spark集群中
- 多语言(Polyglot)→代码可以用 Python、Java、Scala 和 R 编写
- 实时(Real-time)→开发它的目的就是为了支持“实时”用例。
下表总结了Apache Spark和MapReduce之间的主要区别:
| Apache Spark | MapReduce |
| 可用于批量处理和流水式处理 | 可用于批量处理 |
| 由于内存计算,与MapReduce相比速度更快 | 由于 I/O 延迟而变慢 |
| 有许多内置的API来支持大数据处理 | 内置 api 的数量相对较少 |
| 使用RDD进行容错 | 它通过复制来容错 |
| 使用Spark编写的程序代码行数较少 | 使用MapReduce编写的程序代码行数较相对较多 |
| Apache spark安全功能还不太成熟,还在不断发展 | 与Apache spark相比,MapReduce框架更为安全 |
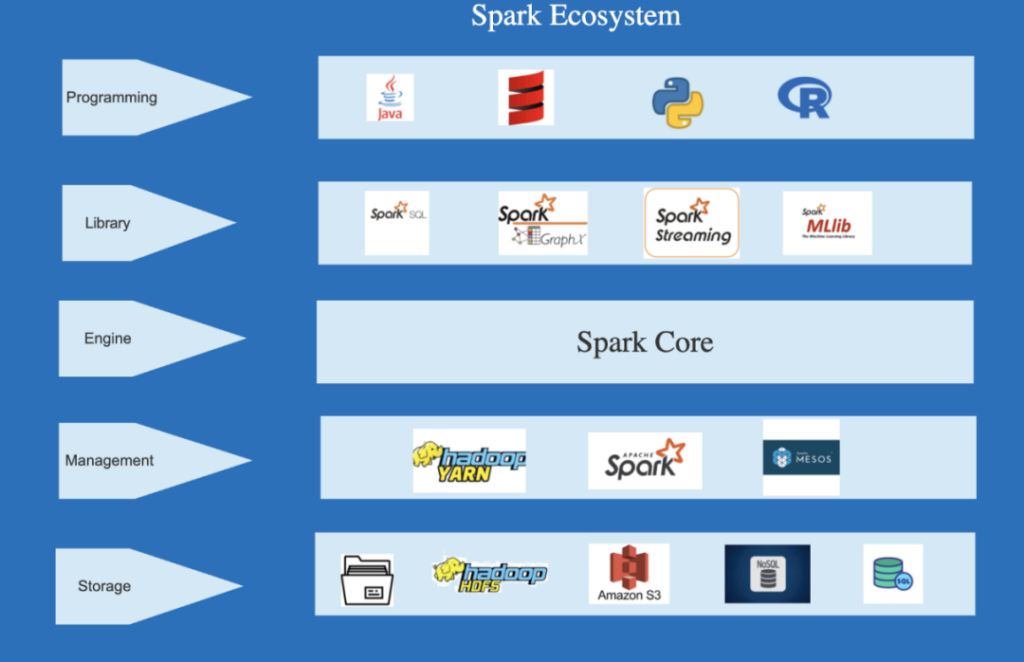
Spark的生态系统
- 引擎(Engine)— Spark Core是Spark生态系统的基础核心组件,整个生态系统都建立在它之上。它执行调度、监控、和基本的IO功能
- 管理(Management)— Spark集群可以通过Hadoop YARN、Mesos 或 Spark集群管理器进行管理。
- 库(Library)— Spark生态系统包括Spark SQL(用于RDD或外部数据源的类似SQL查询的运行)、Spark Mlib(用于机器学习)、Spark Graph X(用于构建更好的数据可视化图)、Spark流(用于同一应用程序中的批量处理和流水式处理)
- 可以用Python、Java、Scala和R进行编程
- 存储(Storage)—数据可以存储在HDFS, S3和本地存储中,同时支持SQL和NoSQL数据库。
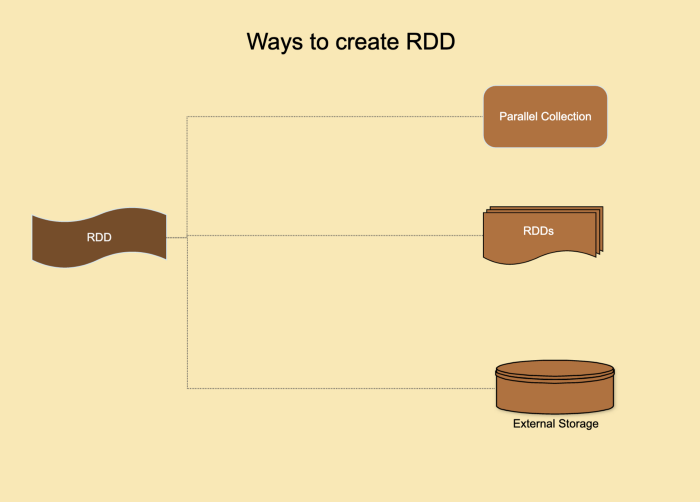
Resilient Distributed Dataset(RDDs)
Spark提供的主要概念是一个弹性的分布式数据集(RDD),它是跨集群节点划分的元素集合,可以进行并行的操作。RDD是通过从Hadoop文件系统(或任何其他Hadoop支持的文件系统)中的文件或驱动程序中现有的Scala集合开始,然后对其进行转换来创建的。用户还可以要求Spark将RDD持久化在内存中,或缓存RDD来提高性能,从而能让它在并行操作中有效地重用。最后,RDD 会自动从节点故障中恢复。
RDD是不可变的,这在自我恢复中起了很大的作用。不可变意味着需要存储用于生成RDD的转换序列。这是一个有向无环图(DAG),可以把数据集复制到多个节点上。所以,如果处理数据集分区的特定节点发生故障,集群管理器就可以把这个节点分配给沿袭的其他节点,并恢复正在处理的数据。
RDD是一种无模式的数据结构,可以处理结构化和非结构化数据。所有的操作都是在RDD上完成的,从一个RDD转换到另一个RDD,最终把它们存储在持久存储中。它是一个不可变的分布式对象的集合,这些对象甚至可以是用户自定义的类别。RDDs支持延迟评估,直到执行了某一个操作,结果才被评估。转换产生新的RDD,操作产生结果。
Spark主要有以下三种工作模式
- 1. 批处理模式——调度作业,并且有一个队列用于运行该作业的批处理,此过程无需人工干预。
- 2. 流水式(Stream)处理模式—当数据流到来时,程序进行运行和处理
- 3. 交互(Interactive)模式——用户在shell上执行命令,主要用于开发目的。
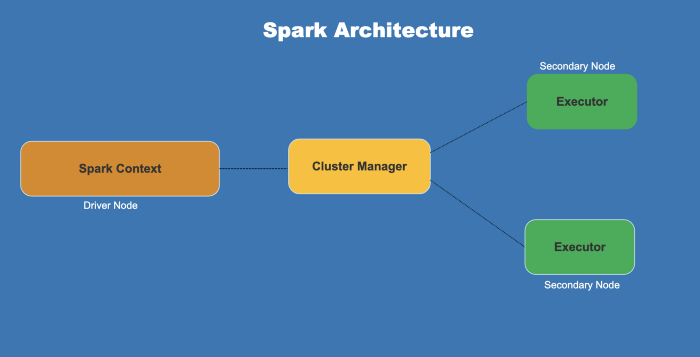
Spark架构
- SparkSpark是由一个驱动节点、集群管理器和多个辅助节点组成的
- 驱动节点包含具有Spark环境的驱动程序
- 驱动程序把用户提交的程序转换为DAG
- Spark环境在集群管理器的帮助下,把任务(作业的可执行部分)分配给次要节点
- 集群管理器分配驱动程序,执行作业所需的资源
- 次要节点是执行任务,并将结果返回到环境的地方
总结
本文我们讨论了Apache Spark,它的生态系统、架构、特性,以及与其他流行的数据处理框架(即MapReduce)的不同之处。Spark的流行,是因为它在内存中处理数据集,所以可以提供快速的结果和MapReduce所缺少的实时处理能力。RDD是提供Spark特性的支柱。如果你想了解有关Spark的更多信息,此项目文档提供了关于不同实现的更多信息。你还可以订阅我们的YouTube频道,观看大量数据科学相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Aneshka Goyal
翻译作者:Lea
美工编辑:过儿
校对审稿:Jiawei Tong
原文链接:https://medium.com/expedia-group-tech/an-introduction-to-apache-spark-f0795f2d5201





