
Spark/Hadoop/MapReduce入门101
当今世界靠着数据运转,每天都会生成TB级的数据。似乎一夜之间,传统系统都变得那么过时,大数据系统反而成了必需品。虽然,我们可以争辩说,大部分公司都不需要处理这种大规模的数据,但随着我们对更好的数据管理的需求的不断增长,促使着公司快速向全球标准发展。
SQL表格正在被NoSQL或Graph数据库取代。Pandas和Numpy数据框即将成为大数据框架的一部分。Hadoop、Spark和Hive也将成为行业中的必需品。在这里,我强烈推荐一个常用的大数据框架—- Apache Spark。不过,在理解Apache Spark之前,我们需要了解几个最基本的系统。如果你想了解更多数据分析相关内容,可以阅读以下这些文章:
使用 PySpark 和 MLlib 构建线性回归预测波士顿房价
来自Twitter数据科学家的关于NLP的4个技巧
如何扩充你的数据科学工具包?这里有24款免费的数据科学工具!
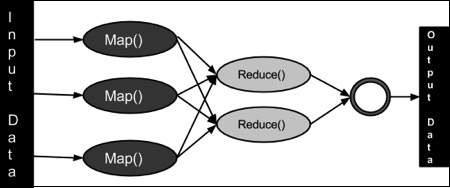
#Q1 什么是MapReduce?
MapReduce是一种编程模型,用于支持能够并行处理的大型数据集。需要注意的是,在某些用例中,并行处理并不起作用,而且在这种情况下,Map Reduce和Apache Spark都不会起作用。
MapReduce是Hadoop生态系统和Spark中的一个重要组件。通过把工作拆分成较小的数据集,完成一些独立任务,来支持大量数据的并行处理。MapReduce从用户那里获取整个数据集,把它分割为更小的任务(MAP),然后把它们分配到各个工作节点。一旦所有工作节点成功地完成了它们各自的独立任务,就会聚合(REDUCE)它们独立活动的结果,然后返回整个数据集的结果。通常,Map和Reduce函数是用户定义的函数,它们解决了以往需要用代码解决的业务用例。
#Q2 什么是Spark?
Apache Spark是一个通用的集群计算系统。和MapReduce一样,它是与一组计算机(节点)一起工作、并行处理,来提高响应的时间。不过,跟MapReduce不同的是,Spark集群有内存特性。它的内存特性能让Spark Clusters把数据缓存到节点上,而不是每次都从磁盘中获取数据。因为数据量巨大,所以通常需要很长时间的读写操作,现在,变成了每个节点的一次性操作,节省了时间,并提高了处理的速度。
数据的内存处理是使用弹性分布式数据集(Resilient Distributed Datasets—-RDD)完成的。用户必须指定操作,RDD负责数据的分发以及所有节点内存中操作。
Spark生态系统的设计分为两层——第一层是Spark Core,第二层是含有libraries和API的包。
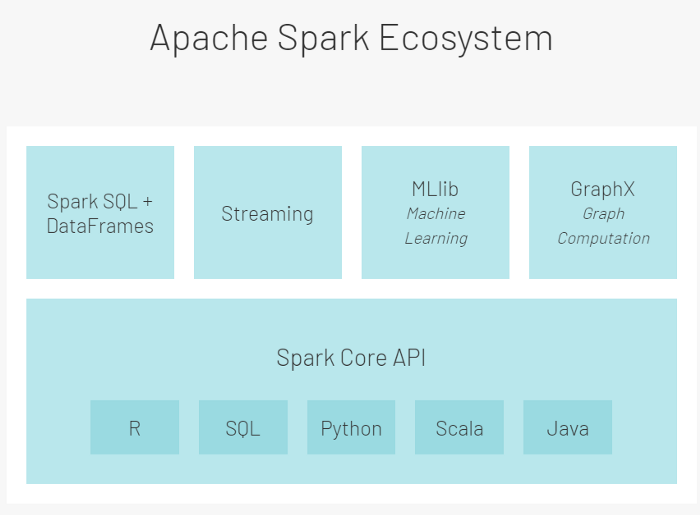
Apache spark不提供集群管理或存储管理工具。通常,人们使用YARN进行集群管理,并将分布式数据存储在Hadoop文件系统(HDFS)或AWS的S3系统上。Spark还有一个名为SPARK ENGINE的计算引擎,它负责将任务分解成更小的任务,调度任务、进行并行处理、向集群提供数据、并报告故障。它也是与集群管理器和数据管理器交互的管理中枢。
Apache Spark Core API(在 R、SQL、Python、Scala 和 Java 中可用)最初是用来编写数据处理逻辑的。这些基于RDD的 API ,缺少了一些性能优化器。但是,因为没有额外的开销,所以它们还为用户提供了最大程度的个人定制和灵活性,可以根据公司的要求进行编程。
为了克服核心API的不足,提供更有针对性的支持,Apache Spark在核心API的基础上引入了第二层。第二层通常分为 4 组逻辑 API/库:
01 SparkSQL和Dataframes.
这允许用户在Spark数据帧上执行SQL命令。它们主要用于结构化和半结构化数据。
02 Streaming.
这些API用于处理连续传入的无界数据流。
03 Mllib.
这个库支持所有可以部署在Spark框架上的机器学习活动。
04 GraphX.
是一个能让图形处理算法实施到可用数据集的库。
/ Spark v.s.Hadoop/
有个常见问题是:当MapReduce已经成为Hadoop中的一部分时,为什么还要使用Spark ?或者,当Spark构建在Hadoop生态系统之上时,它有什么优势?

接下来,我们就一起来看一下Spark和Hadoop之间几个关键的区别:
- 性能——因为是磁盘操作,所以与Spark相比,Hadoop相对较慢。而且Spark因为它内存中的特性,所以速度更快、更适用于实时分析。Spark在内存中运行要快100倍,在磁盘上快了10倍。但是,当有其他需要资源的服务正在运行时,执行的速度可能会减少。
- 数据处理——hadoop只对数据进行批量处理,即连续步进式处理(sequential step-wise processing)。而Spark是以批量、实时和图形的方式处理数据。
- 机器学习——hadoop使用Mahout进行代数运算,但缺乏ML库支持。Spark有一个大型的ML库来构建管道、执行超参数调优(hyperparameter tuning)。
- 易于使用——Hadoop MapReduce没有交互模式,需要大量编程。另一方面,Spark有很多高级 API,所以编程和交互较少。
- 成本——Hadoop更便宜,因为它需要更多的磁盘内存。Spark需要更高的RAM才能在内存中运行,所以成本更高。
- 容错——Hadoop跨多个节点复制数据,所以具有容错性。Spark RDD因为它的内存特性,所以也具有一定的容错性。
总的来说,当系统需要更便宜、更独立的时间以及更大的容错能力时,要选择Hadoop。当算法是迭代的,并且需要交互式数据处理或机器学习时,就要选择Spark。在需要实时预测结果的时候,选择Spark也有一定优势。
上文中,我们只是简单介绍了Spark生态系统和它的明显优势,在以后的文章中,还会继续讲述 SparkSQL和PySpark等相关概念。
感谢你的阅读!你还可以订阅我们的YouTube频道,观看大量数据科学相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Ch Ravi Raj
翻译作者:Lea
美工编辑:过儿
校对审稿:Jiawei Tong
原文链接:https://chraviraj.medium.com/introduction-to-apache-spark-b2d4ff8aacec





