
数据泄露Data Leakage是什么?你为什么要注意?
在执行机器学习任务时,维护数据的干净卫生是至关重要的。目前,这个话题已经得到了人们的很多关注,其中很多关注点都放在了处理过时、不完整或不正确的数据上。毕竟,忽视数据卫生会毁掉你建立可靠模型的机会。
然而,尽管现在大家对这个主题都进行了充分的探讨,但对数据卫生的巨大威胁却缺乏认识,比如数据泄漏—Data Leakage。
在本文中,我们将探讨什么是数据泄漏,它是如何发生的,以及如何防止。如果你想了解更多数据分析相关内容,可以阅读以下这些文章:
数据分析新工具MindsDB–用SQL预测用户流失
DS数据科学家和DA数据分析师:要学习什么不同内容?
数据分析师需要知道的10个Excel函数
数据分析如何在Fintech中发挥作用?
数据泄露
首先,让我们快速回顾一下训练集(Training Set)和测试集(Testing Set)之间的关系。
训练集是用于训练机器学习模型的数据子集,而测试集是用于测试模型的数据子集。很直接简单,对吧?
但是,关于这种关系需要特别强调的是,训练数据需要完全独立于测试数据。测试集中的值应该与训练集中的值无关。
数据泄露是使用训练数据之外的信息去训练模型时发生的现象。它本质上违反了训练数据的独立性,导致它被来自外部来源的信息所改变。
同理,因为提供了误导性的评估指标,会掩盖模型性能的缺陷。如果在这种情况下无法识别数据泄漏,您可能会误以为您的模型是稳固的,只能在部署后才发现它完全不可靠。
因此,你要确认在处理数据时,不会无意中导致任何数据泄漏。
数据泄露案例
类似于厨师们会小心处理肉类和农产品,以避免交叉污染,数据科学家必须正确处理他们的训练和测试集,以避免数据泄漏。
好消息是,只要你足够小心谨慎,就很容易避免数据泄漏。防止数据泄露也不需要编写额外的代码。
坏消息是,你可能会犯一些看似无害的错误,使你的项目暴露在数据泄露之下。你的模型不会通知你这类错误,因此你需要警惕才能避免它们。
下面,让我们介绍一些可能导致数据泄露的错误。
01 不删除重复项
这是从一开始就会危害你的项目的常见问题。
由于包含了重复项,你将面临训练集和测试集中都存在相同记录的风险,从而破坏了两个数据集之间的独立关系。
最简单的处理方法是,在把数据拆分为训练和测试集之前就删除重复记录。
02 在分割数据前进行特征缩放
特征缩放(Feature Scaling)是预处理中的一个重要步骤,它能确保模型不会偏向于某个特定的特征。
但不幸的是,在将数据拆分为训练集和测试集之前,有时会错误地应用标准化(Standardization)和归一化(Normalization)等特征缩放技术。这是一个错误,因为它会让测试数据的值影响训练数据的缩放方式。
特征缩放需要在数据拆分后进行。正确的特征缩放事,需要只根据训练集中的值对训练数据集来执行。然后后,测试集的缩放需要根据用于缩放训练集的参数来进行。
03 分割数据前进行数据增强
数据增强(Data Augmentation)是对抗数据不平衡和增强模型性能的一个非常好的方法。
但是,它的有效性取决于你在训练模型时如何应用。
数据增强不是凭空创建数据,它依靠真实数据和特定的算法来人工生成记录。
自然,自己创建的数据类型也取决于输入生成算法中的数据。测试集中的这些人工数据将不可避免地影响添加到训练集的数据。
基于这个原因,数据增强只能在拆分数据后进行。为了正确执行数据增强,你为训练模型生成的人工数据必须只来自训练数据。
案例分析
为了巩固以上内容,下面让我们通过一个快速案例来应用一下我们学到的内容。我们使用的是保险公司提供的客户信息数据集。数据可以在这里获取https://www.kaggle.com/arashnic/imbalanced-data-practice。
下面是数据集的预览。
import pandas as pd# load datasetdf = pd.read_csv('aug_train.csv')# previewdf.info()
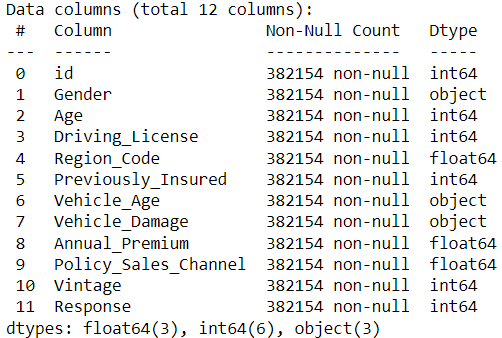
我们的目标变量是“Response”,代表客户是否有兴趣申请保险。
首先,我们可以删除所有缺失值的记录,并用 one-hot-encoding 对分类变量进行编码。
# remove records with missing valuesdf = df.dropna()# find categorical variablescat_var = [col for col in df.columns if df[col].dtypes==object]# perform one-hot-encoding on categorical variablesdf = pd.concat([df, pd.get_dummies(df[cat_var])], axis=1)# drop original categorical variablesdf = df.drop(cat_var, axis=1)
接下来,我们可以用drop_duplicates()方法删除所有重复项,这样所有客户都会是唯一的。需要注意的是,此步骤必须在将数据拆分为训练集和测试集之前进行。
# remove duplicatesdf = df.drop_duplicates()
现在重复数据已被处理,我们可以将数据拆分为训练集和测试集了。
from sklearn.model_selection import train_test_split# split the data into training and testing setX = df.drop(['Response', 'id'], axis=1)y = df['Response']X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42, stratify=y)
接下来,我们使用sklearn的MinMaxScaler,通过归一化来缩放特征。为避免数据泄漏,MinMaxScaler应首先转换训练数据,然后再根据用于缩放训练数据的参数转换测试数据。
# scale the features after splitting the datamms = MinMaxScaler()# transform the values in each feature to fall in the range of (0,1)X_train_scaled = mms.fit_transform(X_train)# transform the values in each feature based on the parameters used to transform the training setX_test_scaled = mms.transform(X_test)
最后,我们可以通过用SMOTE来处理所有不平衡数据。在此之前,让我们看看当前的训练和测试集有多不平衡。
from collections import Counter# frequency of each class before SMOTEprint('Training set: {}'.format(Counter(y_train)))print('Testing set: {}'.format(Counter(y_test)))
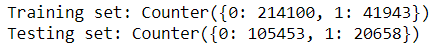
可以看到,训练集和测试集都存在很大的不平衡。
这种情况可以通过SMOTE给训练数据生成人工记录来解决。
from imblearn.over_sampling import SMOTE# add artificial samples to training data onlysm = SMOTE(random_state=42)X_train_sm, y_train_sm = sm.fit_resample(X_train, y_train)
再让我们看看现在训练集和测试集有多不平衡。
# frequency of each class after SMOTEprint('Training set: {}'.format(Counter(y_train_sm)))print('Testing set: {}'.format(Counter(y_test)))
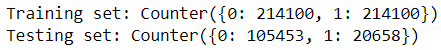
由于此步骤是在训练测试拆分后才执行的,因此SMOTE只会用训练数据创建人工数据。测试集在整个过程中保持不变并且保持不平衡。
在这个案例中,我们将许多技术应用在了我们的数据集。然而,由于我们仔细地处理了训练和测试集,从而避免了数据的泄漏。
结论

文章到这里,你可以发现,数据泄漏是很容易避免的。
我们可以看到,所有提供的例子都演示了当一个步骤在错误的时间执行时,或不是完全执行时,数据泄漏是如何发生的。
与其不注意顺序、任意执行预处理步骤,不如事先计划好你的操作流程。这样,你才能够检查每个步骤,并确保训练数据在整个过程中独立于测试数据。
祝你在数据科学工作中好运!你还可以订阅我们的YouTube频道,观看大量数据科学相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
参考文献
1. Möbius. (2022). Learning From Imbalanced Insurance Data, Version 4. Retrieved February 13th, 2022 from https://www.kaggle.com/arashnic/imbalanced-data-practice.
原文作者:Aashish Nair
翻译作者:Chuang Zhang
美工编辑:过儿
校对审稿:Jiawei Tong
原文链接:https://towardsdatascience.com/an-introduction-to-data-leakage-f1c58f7c1d64





