Python机器学习库:pycarets新增时间序列模块
PyCaret 是一个开源、低代码的 Python 机器学习库,可实现机器学习工作流的自动化。这是一种端到端的机器学习和模型管理工具,可以成倍地加快实验周期,提高工作效率。
与其他开源机器学习库相比,PyCaret 是一个低代码库,可以仅用几行代码替换数百行代码,使得实验速度和效率成倍增长。本质上来说,PyCaret 是一个围绕多个机器学习库和框架的 Python 包装器,例如 scikit-learn、XGBoost、LightGBM、CatBoost、spaCy、Optuna、Hyperopt、Ray 等。
PyCaret 的设计构造和操作简单的特点,是受到了公民数据科学家这一新兴职位的启发,这个术语最早由Gartner使用。公民数据科学家(Citizen Data Scientist)是高级用户,他们可以执行简单和中等复杂的分析任务,这在以前需要更多的技术能力。本文将带你了解pycarets库中新增的时间序列模块。如果你想了解更多数据分析相关内容,可以阅读以下这些文章:
DS vs DE:数据科学家与数据工程师的薪资对比
Pandas和SQL,数据科学家应该用哪个?
如何准备DS数据科学家面试?
在微软成功的数据科学家身上,我学到这5个习惯
PyCaret时间序列模块
PyCaret 新增时间序列模块现已开始了测试阶段。该Beta版保留了 PyCaret 操作简单的特点,与现有 API 保持一致,附加许多其他模块,例如统计测试、模型训练和选择(30 多种算法)、模型分析、自动超参数调优、实验记录、云部署等。只需简单几行代码(与 pycaret 的其他模块一样)即可实现。如果你想试试这些操作,请查看官方快速入门指南。
你可以使用 pip 安装这个库。如果你在相同环境中安装了 PyCaret,由于相依冲突,你必须为 pycaret-ts-alpha 创建一个单独的环境。在下一个主要更新版本中,pycaret-ts-alpha 会与主要的 pycaret 包合并。
pip install pycaret-ts-alpha工作流示例
PyCaret 时间序列模块的工作流非常简单。从setup函数开始,你可以在其中定义预测范围 fh 和fold次数。你还可以将 fold_strategy 定义为expanding或sliding。
setup完成后, compare_models 函数会训练和评估从 ARIMA 到 XGboost(TBATS、FBProphet、ETS 等)的 30 多种算法。
你可以在训练之前或之后使用plot_model 函数。如果在训练前使用,你可以通过 plotly 界面收集大量时间序列 EDA 图。如果与模型同时使用,plot_model 可处理模型残差,并可以用于访问模型拟合。
最后,predict_model 函数被用于生成预测。
数据加载
import pandas as pd
from pycaret.datasets import get_data
data = get_data('pycaret_downloads')
data['Date'] = pd.to_datetime(data['Date'])
data = data.groupby('Date').sum()
data = data.asfreq('D')
data.head()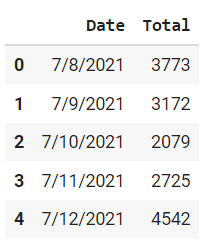
# plot the data
data.plot()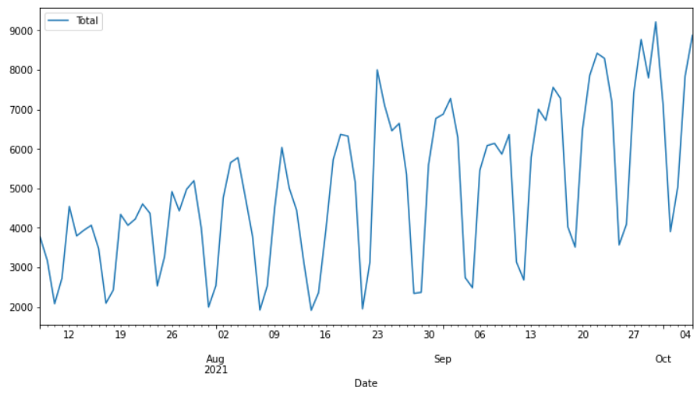
这个时间序列展示的是每天从pip下载PyCaret库的次数。
初始化设置
# with functional API
from pycaret.time_series import *
setup(data, fh = 7, fold = 3, session_id = 123)
# with new object-oriented API
from pycaret.internal.pycaret_experiment import TimeSeriesExperiment
exp = TimeSeriesExperiment()
exp.setup(data, fh = 7, fold = 3, session_id = 123)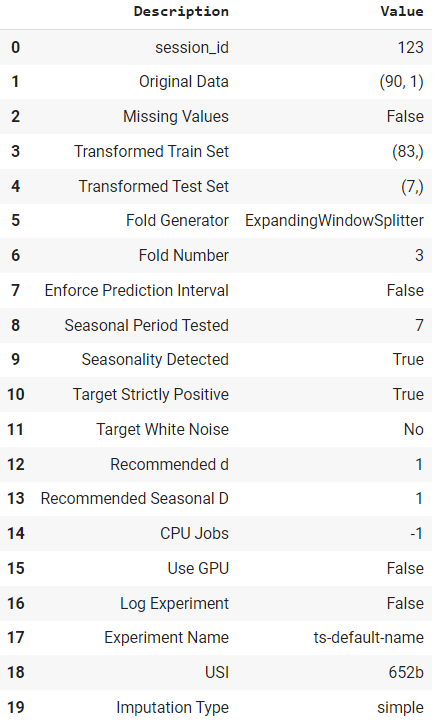
统计测试
check_stats()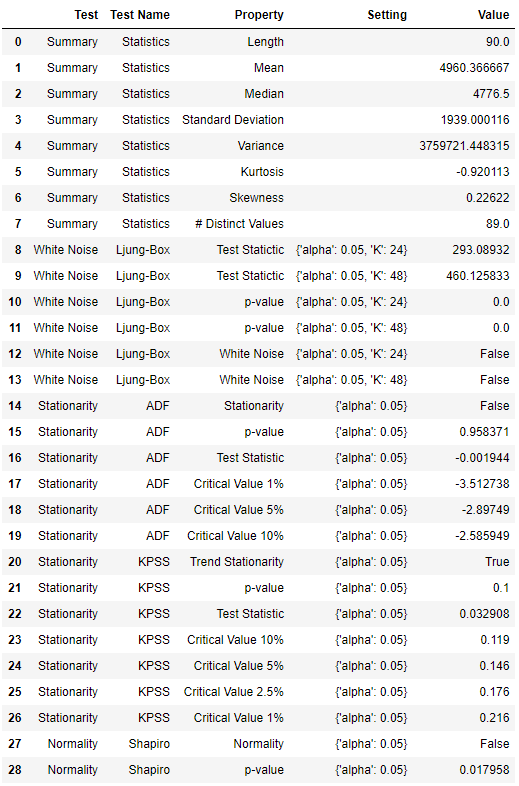
探索性数据分析
# functional API
plot_model(plot = 'ts')
# object-oriented API
exp.plot_model(plot = 'ts')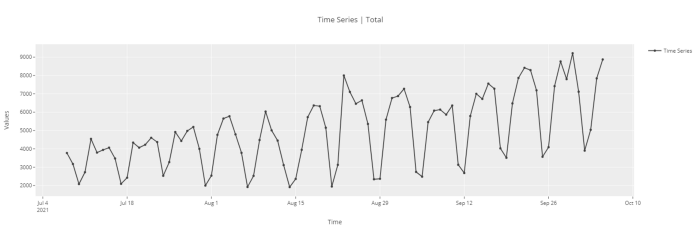
# cross-validation plot
plot_model(plot = 'cv')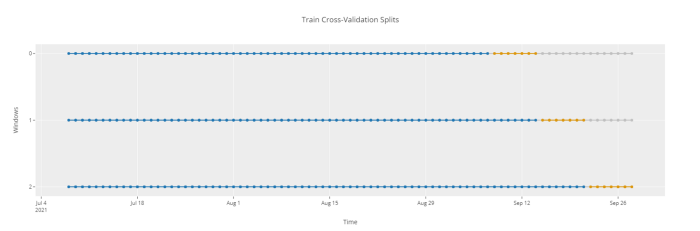
# ACF plot
plot_model(plot = 'acf')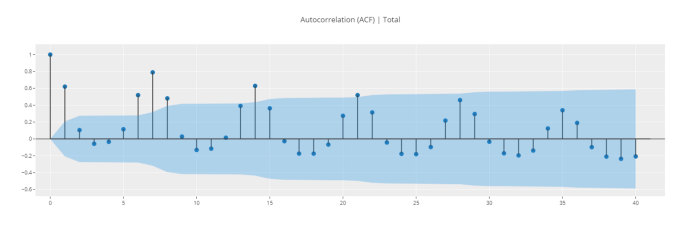
# Diagnostics plot
plot_model(plot = 'diagnostics')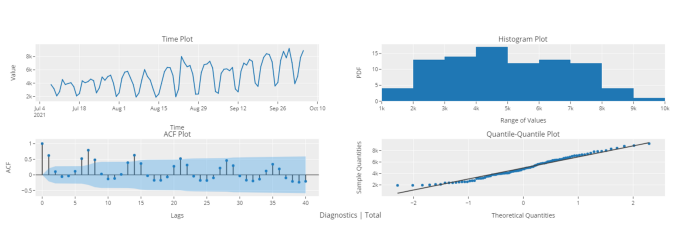
# Decomposition plot
plot_model(plot = 'decomp_stl')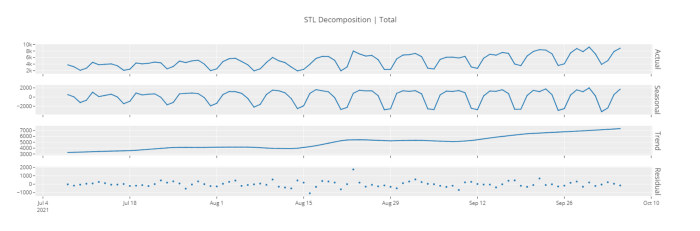
模型训练和选择
# functional API
best = compare_models()
# object-oriented API
best = exp.compare_models()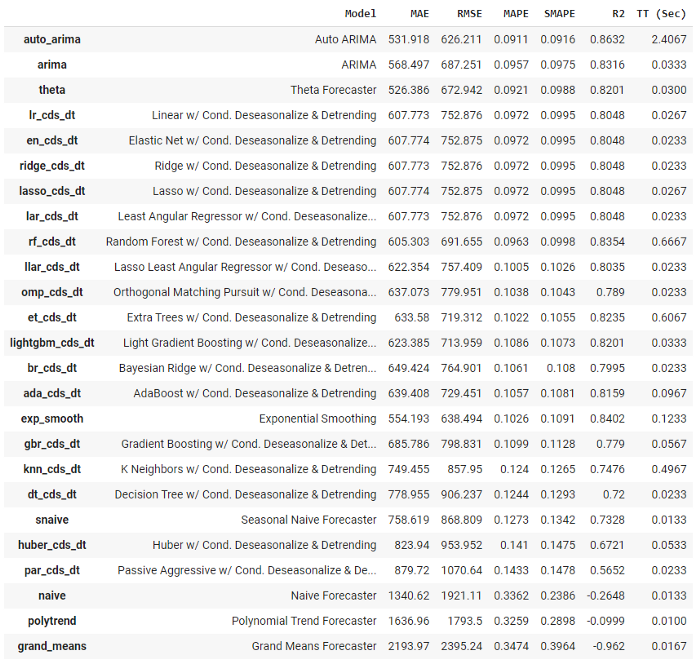
时间序列模块中的 create_model 的运行方式与其他模块中的运行方式一样。
# create fbprophet model
prophet = create_model('prophet')
print(prophet)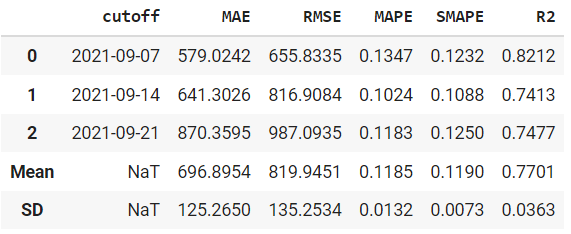

tune_model 的运行也没有很大差别。
tuned_prophet = tune_model(prophet)
print(tuned_prophet)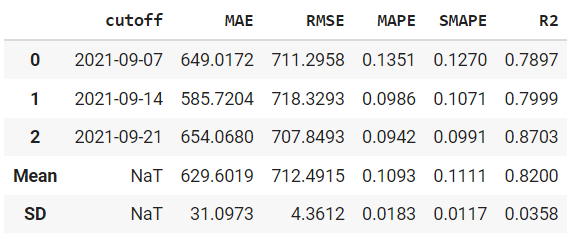

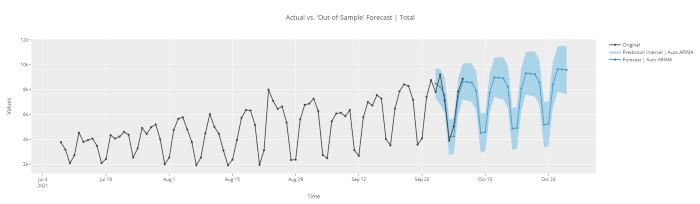
plot_model(best, plot = 'forecast')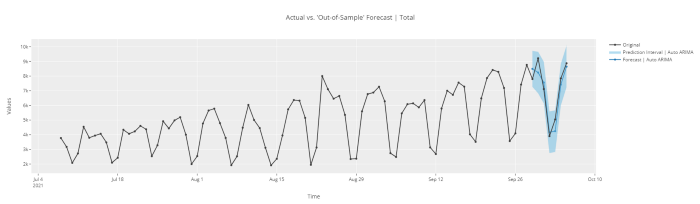
# forecast in unknown future
plot_model(best, plot = 'forecast', data_kwargs = {'fh' : 30})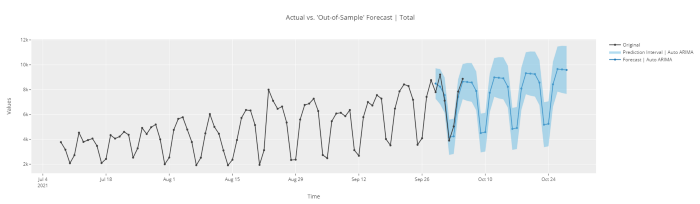
# in-sample plot
plot_model(best, plot = 'insample')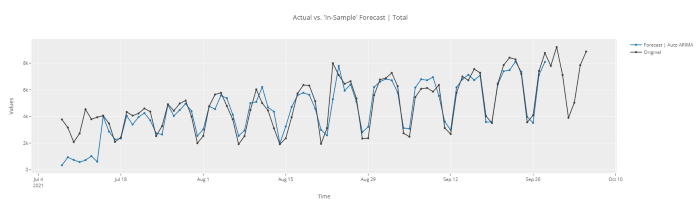
# residuals plot
plot_model(best, plot = 'residuals')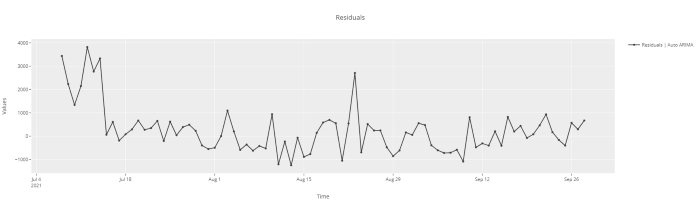
# diagnostics plot
plot_model(best, plot = 'diagnostics')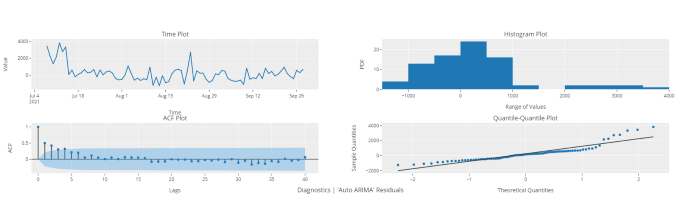
部署
# finalize model
final_best = finalize_model(best)
# generate predictions
predict_model(final_best, fh = 90)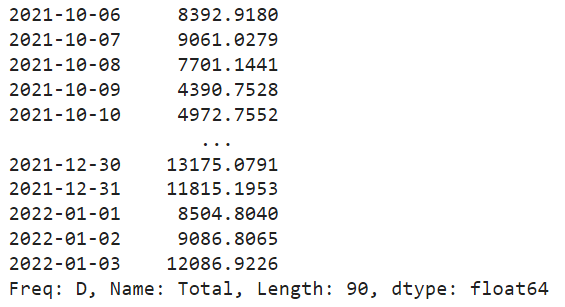
# save the model
save_model(final_best, 'my_best_model')
再次提醒,这个模块仍处于测试阶段。每天都在添加新功能,每周不定时在 pip上发布。你需要创建单独的python环境,避免与主pycaret的相依冲突。此模块的最终版本将在下一个主要版本中与主要 pycaret 合并。
通过使用Python轻量级工作流自动化库,可以实现的功能超乎你的想象。想要了解更多关于数据科学相关的信息,欢迎在 LinkedIn 和 Youtube 上关注我们。感谢你的阅读~!你还可以订阅我们的YouTube频道,观看大量数据科学相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Moez Ali
翻译作者:Lia
美工编辑:过儿
校对审稿:Jiawei Tong
原文链接:https://towardsdatascience.com/announcing-pycarets-new-time-series-module-b6e724d4636c





