
正态分布在数据科学中的应用与使用
在开始学习数据科学时,有一件事可能非常困难,那就是弄清楚这段旅程的起点和终点。关于数据科学旅程的结束,重要的是要记住,这个领域每天都在取得进步,一定会有新的进步——准备好学习很多东西。数据科学不仅包括科学、统计和编程,还包括其他几个学科。
为了最大限度地降低学习难度,重要的是要学会分批获取信息。深入研究和学习特定领域的细节是一件有趣的事情——无论是数据、编程、机器学习、分析还是科学。虽然这让我很兴奋,但有时缩小关注范围也很好,这样我们就可以尽可能地了解一个特定主题。对于初学者来说,当涉及到数据科学时,统计学和正态分布是一个很好的起点。我写了一篇文章,概述了原因并详细介绍了正态分布。我们将在这里对这篇文章做一个简短的总结,但会略去很多细节。如果你想了解更多关于数据科学的相关内容,可以阅读以下这些文章:
苹果面试流程:数据科学家的完整指南
每个数据科学家都应该知道的关于回归的三个简单的事情
5个ChatGPT插件,让你领先于99%的数据科学家!
数据科学初学者必备的7个备忘单!
如上所述的正态分布是一个简单的概率密度函数(PDF),可以应用到我们的数据。这个函数,我们称之为f,计算f(x)的均值中标准差x的个数。思考一下,我们需要均值的标准差,我们如何检查一个值离均值有多少个标准差呢?首先,我们要看它离均值有多远?然后求差值有多少个标准差。这就是我们在公式中所做的。每个x减去均值,差值除以标准差。在统计学中,小写的sigma(σ)表示标准差,小写的mu(µ)表示平均值。在下面的公式中,x bar (x̄)表示观测值(上方f(x)中的x)。
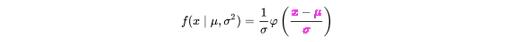
加入到编程语言中
在上一篇文章的末尾,我们将其引入编程语言——Julia。语言的选择完全取决于数据科学家,但也需要考虑权衡,考虑行业的使用情况也很重要。例如,R是一种相对较慢的语言,但它的分析包已经被优秀的开发人员和出色的仪表板工具改进和维护了多年。目前最流行的选择可能是Python,因为它可以快速连接到C库并且易于使用。Julia是一门新语言,但它是我最喜欢的编程语言,我认为大多数数据科学家都应该了解它。虽然Julia的受欢迎程度直线上升,但如果你同时了解这两种语言,就能获得更多的工作机会。幸运的是,大多数数据科学常用的流行语言往往有很多共同点,并且最终很容易相互引用。下面是分别用Python和Julia REPLs编写的正态分布代码。
python
>>> from numpy import mean, std
>>> x = [5, 10, 15]
>>> normed = [(mean(x) - i) / std(x) for i in x]
>>> print(normed)
[1.224744871391589, 0.0, -1.224744871391589]julia
julia> using Statistics: std, mean
julia> x = [5, 10, 15]
3-element Vector{Int64}:
5
10
15
julia> normed = [(mean(x) - i) / std(x) for i in x]
3-element Vector{Float64}:
1.0
0.0
-1.0这里还有每种编程语言的notebook。我将用这三种语言做开发,以使本教程不仅对每个人都易于理解,而且促进与多种语言互动的理念。这些语言较为相似且易于阅读,因此很容易比较和对比它们之间的差异,看看你喜欢哪种语言,也可以更深入地探索每种语言的优缺点。
notebook
Python:https://github.com/emmaccode/Emmys-NoteBooks/blob/master/Python3/Applying%20the%20normal%20distribution%20%28py%29.ipynb?source=post_page—–98f910629ba1——————————–
Julia:https://github.com/emmaccode/Emmys-NoteBooks/blob/master/Julia/Applying%20the%20normal%20distribution.ipynb?source=post_page—–98f910629ba1——————————–
设置函数
首先我们需要的是一个函数它能给出一个数字向量的正态值。这和求均值和标准差一样简单,然后代入公式。这个函数会有一个参数,我们的向量,然后它会返回我们的标准化向量。为此,我们当然还需要均值和标准差——我们可以使用依赖关系。在Python中,我们将使用Numpy的mean和std函数。在Julia中,我们将使用Statistics.mean和Statistics.std。然而,今天我们将从头开始做所有的事情,所以这里是我在Python和Julia中简单的均值和标准差函数:
# python
import math as mt
def mean(x : int):
return(sum(x) / len(x))
def std(arr : list):
m = mean(arr)
arr2 = [(i-m) ** 2 for i in arr]
m = mean(arr2)
m = mt.sqrt(m)
return(m)# julia
mean(x::Vector{<:Number}) = sum(x) / length(x)
function std(array3::Vector{<:Number})
m = mean(array3)
[i = (i-m) ^ 2 for i in array3]
m = mean(array3)
try
m = sqrt(m)
catch
m = sqrt(Complex(m))
end
return(m)
end现在我们有了一些函数来获取我们的函数所需的值,我们需要将这些都封装到一个函数中。这很简单,我只需要用上面的方法求总体均值和标准差然后用推导式从每个观测值中减去均值然后用差除以标准差。
# python
def norm(x : list):
mu = mean(x)
sigma = std(x)
return([(xbar - mu) / sigma for xbar in x])# julia
function norm(x::Vector{<:Number})
mu::Number = mean(x)
sigma::Number = std(x)
[(xbar - mu) / sigma for xbar in x]::Vector{<:Number}
end现在我们来试试我们的标准化函数。这个很容易检验,我们只需要给出一个已知均值的向量。这是因为向量的均值应该是0。在[5,10,15]的情况下,0是10 – [5, 10, 15]的均值。5大约是-1.5,距离平均值一个标准差(在这种情况下,我们的标准差等于数字2.5)。
norm([5, 10, 15])
[-1.224744871391589, 0.0, 1.224744871391589]正态分布的统计显著值通常在离平均值接近2个标准差时开始被注意到。换句话说,如果大多数人大约10英寸高,而有些人20英寸高,这离平均值有3个标准差,这在统计上很显著。
mu = mean([5, 10, 15])
sigma = std([5, 10, 15])
(15 - mu) / sigma
1.5811388300841895
(20 - mu) / sigma
3.162277660168379分析正常
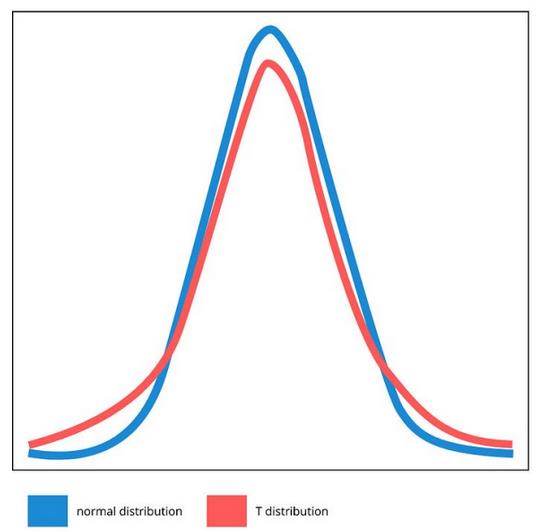
Z分布或正态分布在数据分析中也有许多应用。这种分布可以用于测试,但不像t检验那样常用。原因是正态分布的尾部很短。因此,它通常保留用于在已知方差的大样本量上执行的测试。将正态分布与T分布进行比较,我们会发现T分布的尾部要长得多。这意味着有一个更长的统计显著性区域-因此它变得更容易检测。
只是为了提供一个想法-随着自由度的降低,T分布的尾部会变长,平均值的权重也会变小。上面的t分布可能有大约8个自由度,但自由度为1的T分布会更平坦,尾部更宽。
这种类型的检验,即z检验,将检验总体均值的差异是否足以具有统计显著性。该公式也与我们之前从PDF中看到的公式非常相似,因此这里没有太多新内容。与使用每个观察值不同,我们只需将xbar更改为表示我们要测试的总体的均值。该测试将返回z统计量。与t统计量类似,它通过另一个函数运行,从而得到一个概率值。让我们创建一个快速的一维观察集,看看我们将如何执行这样的测试。
pop = [5, 10, 15, 20, 25, 30]
mu = mean(pop)
sigma = std(pop)我们将从中间抽取一个随机样本并计算z统计量:
xbar = mean(pop[3:5])现在我们把这个代入公式。
(xbar - mu) / sigma
0.5976143046671968这个新数字是z统计量。将这些统计值转化为概率值的数学运算相当复杂。两种语言中都有库来帮助处理这些事情。对于Julia,我推荐使用HypothesisTests,对于Python,我推荐使用scipy模块。对于本文,我们将使用这里提供的在线Z统计值到概率值计算器。把z统计量代进去:

正如我们所预料的,我们的一些样本与总体的均值非常接近,均值在统计上根本不显著。话虽如此,我们当然可以用更有统计学意义的东西进行实验,并拒绝我们的零假设!
xbar = mean([50, 25, 38])
(xbar - mu) / sigma
4.820755390982054
正态分布当然很适合测试。关键是要理解这种形式的测试需要很大的样本量,并且不能应用于所有数据。在大多数情况下,对于初学者,我建议从一个更容易测试的分布开始,比如T分布。数据对于z检验来说更加重要,对于初学者来说很难找到大量的数据来源,此外,即使样本在统计上是显著的,也很难得到统计上显著的结果。
正态分布也可以用于数据科学项目中的快速分析。能够将数据转化为与总体的关系是非常有用的,可以用于数据可视化,以及确定给定总体的变异程度。通过研究我们的观测值与均值的关系,我们可以了解到关于总体的很多信息。
数据归一化的常态
正态分布的另一个重要应用是利用正态分布对数据进行规范化。连续特征可能会受到一些不同因素的干扰,其中最重要的一个可能是异常值。我们需要从数据中剔除异常值以使我们的数据具有普遍性。记住,构建出色的数据的关键是构建出色的总体。我的意思是,我们希望总体数据,比如均值,能够代表数据在某种程度上符合正态分布的情况。这样,当数据有所不同时,就会变得非常明显。
考虑到正态分布告诉我们一个值与均值有多少偏差,我们很容易看到如何将其用于数据归一化。如前所述,2.0是事情开始变得重要的地方。话虽如此,我们可以制作一个mask,并使用它来过滤坏值!
# julia
function drop_outls(vec::Vector{<:Number})
normed = norm(vec)
mask = [~(x <= -2 || x >= 2) for x in normed]
normed[mask]
end通过这个简单的掩码过滤,我们可以判断值是否远离均值,并基于此将其排除。在大多数情况下,我们可能还想用平均值替换这些异常值,这样我们就不会失去对其他特征或目标的观察。
# python
def drop_outls(vec : list):
mu = mean(vec)
normed = norm(vec)
mask = [x <= -2 or x >= 2 for x in normed]
ret = []
for e in range(1, len(mask)):
if mask[e] == False:
ret.append(vec[e])
else:
ret.append(mu)
return(ret)标准缩放
数据科学中常见的正态分布的最后一个应用是标准缩放。这个缩放器非常有用,因为它可以帮助你将数据转换为与它所属的特性更密切相关的数据。这对机器学习非常有帮助,并且可以很容易地提高模型的准确性,特别是对于连续特征而言。使用标准缩放器是非常简单的;只需像以前一样使用我们的PDF并获得规范化特性。
myX = [1, 2, 3, 4, 5]
normedx = norm(x)这用于提供给机器学习的数据。在日常部署的许多机器学习模型中,正态分布通常用于处理连续特征。
最后
最后,正态分布是统计学和数据科学的基本组成部分,在数据科学的许多不同应用中都有广泛的应用。这个领域中有很多不同的主题都倾向于以这种方式展开。开始相对简单,最终演变成相当复杂。
深入研究一个主题当然很棒,正态分布也不例外,因为这个基本而简单的分布的能力确实令人着迷。谢谢大家的阅读,我希望这篇文章是有用的!
原文作者:Emma Boudreau
翻译作者:Dou
美工编辑:过儿
校对审稿:Chuang
原文链接:https://towardsdatascience.com/applying-and-using-the-normal-distribution-for-data-science-98f910629ba1





