
使用Python的schedule轻松管理定时任务
计划任务不仅是编程中的常见特征,而且是高效企业的基石和自动化的基本组成部分。以业务的月度报告生成为例。每个月依靠某人手工撰写这份报告不仅容易出错,而且是一种不必要的负担。
通过设置在每个月末自动执行的任务,你可以简化流程并降低人为错误的风险。现在,你不用再为最后期限而汗流浃背,你可以一边喝着咖啡,一边放心地知道你的自动化系统正在处理繁重的工作。
生成报告只是一个例子,还有许多其他的操作通常是定期执行的。例如:
- 备份数据库
- 执行健康检查
- 重新训练机器学习模型
- 将数据从一个服务移动到另一个服务,例如从热存储移动到冷存储
- 重新抓取网站以获取新信息
- 发送电子邮件
在本文中,我将深入探讨Python中schedule包的使用,并解释它如何简化你的任务调度需求。如果你想了解更多关于Python的相关内容,可以阅读以下这些文章:
Meta正在做上帝的工作:向世界发布令人震惊的优秀编程模型!
畅销编程书籍中的10个编码秘密
Mojo:比Python快35000倍的AI编程语言
作为一个数据科学家/分析师,不要重复这5个编程错误
为什么不只使用time.sleep呢?
我们已经讨论了许多不同的任务,这些任务通常是定期执行的。现在,我们如何编写一个程序来定期执行一个任务呢?
最简单的方法是在while循环中使用内置的time.sleep方法。以下是一个示例:
import time
def perform_task():
print("Performing task...")
...
print("Task completed!")
while True:
perform_task()
print("Sleeping...")
time.sleep(60)输出:
Performing task...
Task completed!
Sleeping...
Performing task...
Task completed!
Sleeping...
...程序立即执行任务,休眠60秒,然后重复该过程,简单。
有时这就是你所需要的,在这些情况下,我们不需要schedule或任何其他包。原因是time.sleep在这里的作用是,我们只需要控制任务相对于前一次运行的时间。在更复杂的场景中,我们将不得不添加更多的代码。以下是一些需要更多代码才能实现的功能示例:
- 把任务安排在特定的时间、特定的日子、特定的工作日等等。
- 并行安排多个任务
- 取消任务
- 以随机间隔运行任务
- 列出计划任务
- 在限定时间内运行任务
调试、测试和实现这些特性可能非常耗时,特别是如果你打算在将来扩展软件功能和复杂性。相反,使用经过实战测试且可读的库通常是一种更简单、更可靠的方法。
Schedule——用于人类的Python作业调度库
Schedule是一个Python包,用于简化在Python中描述和运行计划的任务。该软件包的核心是可读性和易用性。我们可以使用pip来安装它:
pip install schedule为了说明使用起来有多简单,让我们以创建一个程序为例,该程序将在每周一的00:00执行,并在那时写入hello world:
import schedule
import time
def task():
print("hello world!")
job = schedule.every().monday.at("00:00").do(task)
while True:
print("checking")
schedule.run_pending()
time.sleep(1)这将导致程序输出:
checking
checking
checking
...
hello world! <- at monday 00:00
...描述schedule的关键表达式是:
schedule.every().monday.at("00:00").do(task)正如你所看到的,即使你不懂Python或编程,也可以立即清楚任务将在何时运行,因为它读起来就像简单的英语。
你可能想知道为什么会有一个time.sleep在while循环中休眠。原因如下:调用schedule.run_pending()将检查一个作业是否应该运行,如果应该,则执行它。但如果没有任务,它会立即返回。为了防止while循环一遍又一遍地快速执行,从而占用大量CPU资源和时间。在两次循环判断之间用time.sleep引入1秒的延迟。你可以选择另一个睡眠时段,这将是进程可能偏离预定时间的最大时间错误。
更多的例子
让我们看几个例子,看看如何用schedule包来设置定期运行的任务。我假设每个例子都有一个while循环,就像上面那样。
每60秒运行一个脚本:
schedule.every(60).seconds.do(job)每天13:37运行:
schedule.every().day.at("13:37").do(job)每隔一周的周二下午13:00运行一次。
from datetime import datetime
def job():
# get current week number
current_week_number = datetime.now().isocalendar()[1]
# do not run on odd numbered weeks
# alternatively change to == 0
if current_week_number % 2 == 1:
return
# perform job here...
schedule.every().tuesday.at("13:00").do(job)每三小时运行一次:
schedule.every(3).hour.do(job)每30 ~ 60秒运行一次(每次随机选择):
schedule.every(30).to(60).seconds.do(my_job)每小时第五分钟运行一次;
schedule.every().hour.at(":5").do(job)你可以使用这个包做更多的事情,我将为你提供一个使用schedule的有趣示例。有关其所有功能的更详细信息,请参考此处提供的文档。
快速捕获异常
想象一下,你有一个传感器,正在从某种现象中收集数据。该传感器具有很高的采样率,但存储单个值既昂贵又不必要。但有时,当发生一些奇怪的事情时,你希望更频繁地保存数据以调查该事件。
计划是这样的,数据以3.33 Hz的常规频率保存(或每隔0.3秒保存一次),但当检测到异常时,将采样频率增加到20hz(或相当于每0.05秒保存一次),然后恢复正常,我们在Python中使用schedule进行编码。
首先,让我们导入包:
import schedule
import matplotlib.pyplot as plt
from datetime import datetime
import time
import random
import pandas as pd
import logging
import sys值得注意的是,除了schedule之外,我还使用了pandas和matplotlib。然后定义常数。它们用于决定我们采样的频率(根据采样之间的时间),采样的时间(总的和“快速采样”),以及如何定义异常。在这种情况下,异常被定义为偏离预期平均值0.15的平均值。
# how often to sample
NORMAL_SAMPLING_INTERVAL = 0.3
FAST_SAMPLING_INTERVAL = 0.05
ANOMALY_CHECK_SAMPLING_INTERVAL = 3
# how long to sample
FAST_SAMPLING_TIME = 10
STOP_IN_MINUTES = 1
# how to detect anomaly
DEVIATION_THRESHOLD = 0.15
LAST_N_VALUES = 10然后我定义了一个基本的日志记录器,它将使所有日志看起来像这样:
[hh:mm] <message>并将它们打印到stdout。
# logger "[00:00]"
logging.basicConfig(
level=logging.INFO,
stream=sys.stdout,
format="[%(asctime)s]: %(message)s",
datefmt="%M:%S" # minute:second
)现在,让我们定义任务。首先,有一种方法可以生成带有时间戳的模拟数据,然后有一种处理方法可以简单地保存数据并记录数据。当它在“快速模式”下进行采样时,它将更改日志信息。
# method to generate from a "hypothetical" data stream
def get_latest_value():
return (datetime.now(), random.random())
def process(store, fast=False):
time, value = get_latest_value()
logging.info(show_sample_message(value, fast))
store.append(dict(time=time, value=value))异常检查器是一个单独的任务,运行频率较低:
def check_for_anomaly(store):
# take the last n values
last_n_values = pd.DataFrame(store[-LAST_N_VALUES:])
# no mean when zero length
if last_n_values.shape[0] == 0:
return
mean = last_n_values["value"].mean()
# minimum for check
if len(last_n_values) < LAST_N_VALUES:
deviation = None
else:
# deviation from mean
deviation = abs(mean - 0.5)
# log the check nicely
logging.info(show_check_anomaly_message(mean, deviation, DEVIATION_THRESHOLD))
if deviation is not None and deviation > DEVIATION_THRESHOLD:
# if there is a deviation we:
# 1. clear normal data processing task
# 2. clear the current anomaly checker
# 3. start a faster data processing task
# 4. schedule a switch back to normal anomaly checking and sampling
schedule.clear("data_processing")
schedule.clear("anomaly_check")
logging.info("Anomalous mean detected!")
logging.info("Switching to faster sampling")
(schedule
.every(FAST_SAMPLING_INTERVAL)
.seconds
.do(process, store=store, fast=True)
.tag("faster_data_processing"))
# clear normal process
# Schedule to switch back to normal processing after FAST_SAMPLING_TIME seconds
schedule.every(FAST_SAMPLING_TIME).seconds.do(switch_to_normal, data=data)这里的重要部分是,当发现异常时,将停止旧任务并启动新任务。为此,使用.tag()标记每个任务。这使我们能够稍后使用.clear()停止它。此外,为了切换回来,即停止我们添加的新任务并重新启动旧任务,我们有一个名为switch_to_normal的“运行一次”计划任务。请注意,尽管此任务运行一次,但它仍然使用.every()进行调度。这是因为要停止一个任务,你需要从任务中返回值schedule.CancelJob。也就是说:
def my_task():
...
return schedule.CancelJob
然后它就不会再运行了。下面是switch_to_normal的实现:
def switch_to_normal(data):
schedule.clear("faster_data_processing")
logging.info("Switching back to normal sampling")
schedule_normal_job(data)
schedule_anomaly_check_job(data)
return schedule.CancelJob我们所要做的就是清除更快的采样过程并重新安排采样过程。我们也不会忘记通过返回schedule.CancelJob来取消切换任务。
现在,让我们看一下主程序:
def schedule_normal_job(data):
return schedule.every(NORMAL_SAMPLING_INTERVAL).seconds.do(process, store=data, fast=False).tag("data_processing")
def schedule_anomaly_check_job(data):
return schedule.every(ANOMALY_CHECK_SAMPLING_INTERVAL).seconds.do(check_for_anomaly, store=data).tag("anomaly_check")
def finish():
# as we clear it will only run once
schedule.clear()
if __name__ == "__main__":
data = []
schedule_normal_job(data)
schedule_anomaly_check_job(data)
# clear all jobs after STOP_IN_MINUTES
schedule.every(STOP_IN_MINUTES).minutes.do(finish)
while True:
schedule.run_pending()
# if it's finished, break
if len(schedule.get_jobs()) == 0:
break
# needs to be fast enough to not miss any scheduled jobs
time.sleep(0.01)
# plot
srs = pd.DataFrame(data).set_index("time")
srs.index = pd.to_datetime(srs.index)
srs.plot()
plt.show()由于正常作业和异常检查被多次调度,因此将它们包装在一个方法中以避免代码重复。添加一个列表来保存数据。然后调度初始作业,包括使用schedule.clear()清除所有任务的完成作业,这将导致while循环中断,因为它检查有多少任务正在运行。值得注意的是,由于任务以高频率运行,这里添加了短睡眠时间。
最后,绘制数据。
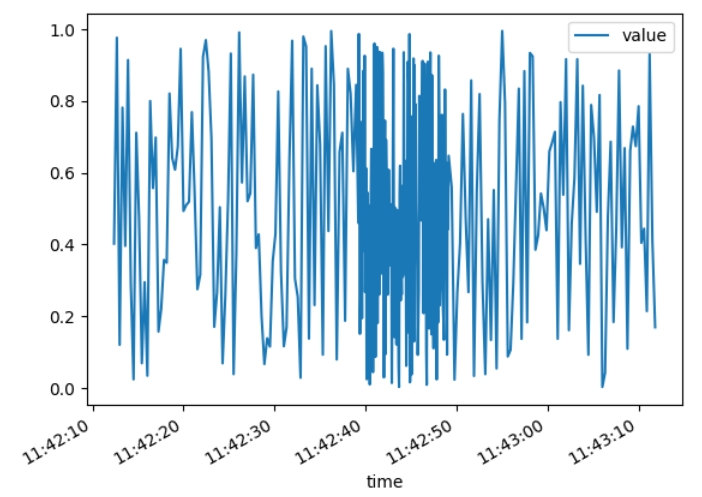
在结果图中,我们可以看到在检测到异常平均值后,中间的高频采样:
如果你对此代码感兴趣,它们如下所示:
# format messages nicely
def show_check_anomaly_message(value, deviation, threshold):
if deviation is None or deviation < threshold:
# green checkmark
status = "\033[92m✔\033[0m"
msg = "OK"
else:
# red x
status = "\033[91m✘\033[0m"
msg = "ANOMALY"
diff_string = f"{deviation:.2f}" if deviation is not None else "N/A"
return f"{status} {msg} [MEAN:{value:.2f} - DEVIATION:{diff_string}]"
def show_sample_message(value, fast=False):
if fast:
# lightning icon for fast sampling
msg = "\033[93m⚡\033[0m QUICK"
else:
# wave icon for normal sampling
msg = "\033[96m🌊\033[0m NORMAL"
return f"{msg} [VALUE:{value:.2f}]"总结
Python中的schedule 库是一个方便的工具,用于管理程序中重复出现的任务。与cron表达式或从头开始使用time.sleep()相比,它提供了许多特性和一种干净、易读的方法。下次你需要在Python中自动执行任务时,请尝试一下schedule。
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Jacob Ferus
翻译作者:过儿
美工编辑:过儿
校对审稿:Chuang
原文链接:https://itnext.io/automate-everything-effortless-task-scheduling-with-pythons-schedule-package-f75b891bd39b





