
Meta正在做上帝的工作:向世界发布令人震惊的优秀编程模型!
正如斯坦福大学和伯克利大学所证实的那样,在GPT-4编码能力正在失去准确性的传言中,Meta发布Code LLaMa,这是一系列专门用于代码补全的LLM(语言模型)。
但是除了令人印象深刻的性能之外,它们还包含了一系列令人兴奋的特性,这些特性将使Code LLaMa成为大多数程序员的默认选择。
最棒的是,无论是研究还是商业应用,它都是完全免费的,是来自人工智能之神的礼物。如果你想了解更多关于编程的相关内容,可以阅读以下这些文章:
数据科学家提高Python代码质量指南
10个很棒的开源AI项目——私人AI、代码修复等
ChatGPT代码解释器:这里有10个令人惊叹的用例!
动动小手,几行python代码让你的邮箱自动化又智能!
开源统治一切
自从Meta投身到生成式人工智能的狂热中,他们就决定采取与其他“大型科技”公司不同的做法。
开源方法
虽然微软为了获得对其模型的优先访问权,向OpenAI投资了100亿美元,并基本上将ChatGPT嵌入到现有的所有微软软件中,但Meta选择了一个更大胆的立场。
Meta的首席人工智能科学家Yann LeCun似乎对LLM的能力完全不感兴趣,他对这些工具及其最终成为我们所说的超级智能的能力的预测非常乐观,他也相信开源解决方案最终会战胜像ChatGPT这样的私人解决方案。
因此,Meta在人工智能方面的方法是将他们大部分的工作都公开发布。
官方的原因是什么?
因为他们觉得这种颠覆性的技术应该是开源的。
可能的真正原因是什么?
他们希望确保地球上没有任何公司在人工智能领域建立壁垒,确保构建这些高科技解决方案所需的知识对公众开放。
例如,如果你是微软或OpenAI,你发布了一个封闭源码的新模型,三周后Meta发布了一个在性能方面“足够接近”的开源版本,你的技术壁垒就没了。
当然,你还可以通过其他方式开发壁垒(关键专有数据、具有出色UI/UX体验的产品或网络效应),但有一点是肯定的:拥有一流的人工智能是不够的,因为你的大多数竞争对手也会拥有它。
现在,在一个月前发布LLaMa 2之后,他们将这种方法更进一步,将LLaMa 2模型微调为专门针对代码的新的大型语言模型(LLM)。
结果令人印象深刻。
伟大的微调
Meta发布了多达9个——是的,9个——专门针对编程应用程序的新LLM。但在解释需要这么多模型之前,Meta用一些明显出乎意料的东西让大家大吃一惊。
Code LLaMa模型可以执行多任务。
多任务模式
在第一次微调练习中,值得注意的是,他们针对两项任务训练了它们:
- 代码完成:与任何基于代码的LLM一样,该模型已经被训练成以自回归的方式预测高质量的代码
自回归模型是一种使用序列中的前一个文本或代码来预测下一个单词或代码标记的模型。他们不向前看,只向后看,因此有了“自回归”这个词。
ChatGPT、Claude,或者今天的任何会话AI,都是自回归模型的例子。
- 填充:Code LLaMa模型还能够进行代码填充,这意味着它们可以根据周围的上下文完成或预测代码片段中缺失的部分。
正如你想象的那样,这个填充任务不是自回归的,因为模型需要查看整个代码提示以找出缺失的内容。
当你想要检查代码或添加文档字符串(使代码更易于理解的注释)时,代码填充特别有用,使模型对程序员更有用。
但论文中最有趣的发现之一是他们在长序列建模方面取得了令人印象深刻的里程碑。
利用RoPE的强大功能进行长上下文建模
自从《变形金刚》出现以来,包括ChatGPT或Stable Diffusion在内的大多数人工智能解决方案背后的架构都有数百篇论文声称对其进行了改进。
但是为什么呢?变形金刚有两个大问题:
- 推断:变形金刚暴露在比他们在训练中看到的更长的序列中会受到伤害
- 训练非常长的序列也不可行,因为计算成本是序列长度的二倍(如果你把序列翻倍,成本翻四倍)。
在编码等情况下,提示可能非常长(例如,HTML网页每页的长度通常在7k到14k之间),这意味着我们今天所知道的标准LLM在复杂情况下并不是一个真正的选择。
事实是,虽然大多数提出的创新都没有解决任何问题,但两年前提出的一项特殊突破确实证明了它的有用性:旋转位置嵌入,或RoPE。
但首先,什么是“位置嵌入”?
顺序的重要性
由于Transformer一次性处理序列中的所有标记,并利用GPU的并行化能力,我们必须对每个标记进行编码,以表示其在序列中的绝对位置。
例如,“那只猪在追我们的狗”和“那只狗在追我们的猪”有完全相同的字,但意思完全不同。
为了确保保持这个结构,标准Transformer为每个标记添加了一个基于正弦函数的“位置编码”(PE),为模型插入所需的信息,以知道每个标记在序列中的位置。
可悲的是,基于正弦的PE是混沌的,当我们超过训练中使用的序列长度(前面提到的外推问题)时,它的表现很糟糕。
另一方面,Rotary PE提供了一个更结构化的解决方案,通过旋转每个嵌入极性形式的标记角度,使模型能够更好地理解较长序列中标记的位置。
事实证明,当用极坐标形式而不是直角坐标形式表示向量时,通过改变向量的角度,实际上是将其位置编码到Transformer中。
换句话说,正如你在下图中看到的,根据单词“dog”的位置,它的角度会有所不同。简单地说,“dog”的标记嵌入的角度将告诉模型“dog”在句子中的位置。
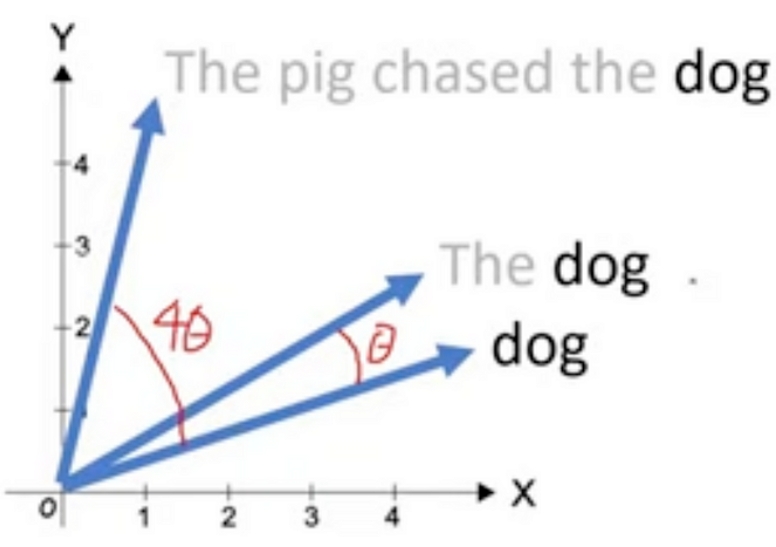
但更重要的是,RoPE还保留了单词之间的相对位置,这也是正确的文本建模的关键要求。
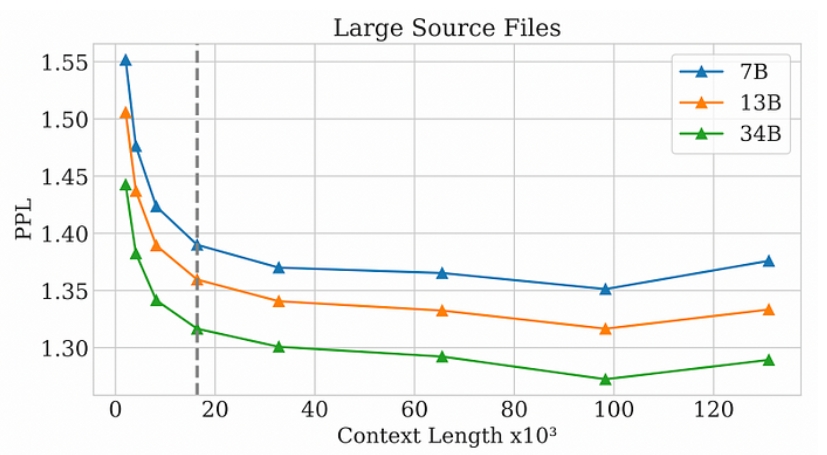
因此,使用RoPE的结果可以在下图中清楚地看到,因为困惑不仅不会随着序列的增加而增加,而且会持续下降到只有100,000个标记!
困惑度是衡量下一个象征性预测的确定程度。困惑度越高,模型就越“不确定”下一个符号应该是什么。
换句话说,越低越好。
通俗地说,这意味着你可以摄取含有多达100,000个令牌(或大约75,000个单词)的Code LLaMa模型,并且该模型仍然可以正常工作。
Meta能够同时处理多个任务以及在长序列情况下有出色的表现。
为什么是9个型号?
David 对 Goliath,Python版
Code LLaMa家族的整体情况如下图所示:

- 首先,他们发布了三个版本的Code LLaMa(右上),可以将其视为代码生成的基础模型。
根据LLaMa家族的原始尺寸,这三个类别都有70亿、130亿和340亿尺寸模型,因此总共有9个模型。
- 其次,他们添加了一个额外的基于指令的微调层来创建Code LLaMa – Instruct,这是一个专门针对遵循指令的模型系列(可能是编码人员的主要默认选择)。
- 第三,为了证明领域特异性的重要性,他们使用基于Python的数据集对Code LLaMa模型进行了微调,以创建Code LLaMa – Python,专门用于Python代码生成。
结果
就性能而言,Code LLaMa模型基本上优于任何其他公开可用的文本到代码LLM,并且肯定会成为大多数不愿意付费访问GPT-4和Claude模型的程序员的默认选择(特别是考虑到我们可爱的ChatGPT最近的质量损失)。
实际上,就在最近,Phind发表了一个模型,据他们说,该模型在pass@1的HumanEval中击败了GPT-4(该模型只进行了一次尝试),略微领先于著名的OpenAI模型。
更令人惊讶的是,Meta已经证明了专一性的巨大重要性,因为Code LLaMa Python的70亿参数模型在Python代码生成方面的整体性能优于LLaMa 2的700亿参数模型。
这句话有两层意思:
- 对特定于领域的数据进行微调对于LLM性能至关重要。
- 除了通用的代码生成器之外,训练特定语言的LLM似乎是一个很好的选择,除了比通用的非微调模型小十倍之外,还能产生更好的结果。
此外,遵循与以前版本相同的模式,Meta正在投入大量精力来确保模型最终可以安全使用。
例如,除了根据诸如Truthful QA等流行的安全基准来评估模型外,他们还有专门的团队对不同的模型进行“红队测试”,以确保不会满足生成恶意代码的请求。
开源又赢得了一场伟大的战役
总的来说,这对Meta来说是一次伟大的胜利,对AI社区来说也是一次伟大的胜利。
通过开源另一个表现最好的LLM,这次是代码生成和填充,Meta的研究团队再次普及了尖端技术,允许研究人员、开发人员和组织在此基础上构建各种应用程序。
此外,Code LLaMa模型最关键的特性之一是它使用RoPE(旋转位置嵌入)来支持长序列建模,这是复杂编码任务的关键要求。
传统的模型通常难以理解扩展序列的上下文,限制了它们在需要细致理解或复杂推理的任务中的适用性,因此长序列建模的良好性能是一个巨大的胜利。
Meta的研究团队关注安全和有益性的态度既及时又值得称赞。随着人工智能模型越来越多地融入我们的日常生活,围绕它们部署的伦理考虑不能再被忽视。
总之,Code LLaMa模型系列体现了现代人工智能研究应该努力实现的三个方面:性能、适用性和道德责任。
论文链接:
https://ai.meta.com/blog/code-llama-large-language-model-coding/
原文作者:Ignacio de Gregorio
翻译作者:过儿
美工编辑:过儿
校对审稿:Chuang
原文链接:https://medium.com/@ignacio.de.gregorio.noblejas/meta-is-doing-gods-work-releases-shockingly-good-coding-models-to-the-world-848975e7d1f0




