
2021倒数51天!数据应用学院陪你6个月转行数据科学
两天前,美国劳工部表示,8 月份离职的美国人人数飙升至 430 万以上,创下了 2000 年 12 月以来的最高记录。根据劳工部的数据,8 月份退出的人数从 7 月份的 400 万跃升。8 月份离职的 430 万人约占整个劳动力的 3%。

Covid-19 危机期间对劳动力产生巨大影响,从历史上看,辞职意味着人们对在其他地方找到工作有保障的信心。由于疫情带来的健康问题和儿童保育问题,很多工人选择了离职。
然而,科技公司的招聘行动却有增无减。Facebook,Amazon甚至出现了争夺人才的情况。在这个劳动力动荡的时刻,正是我们抓住机遇,进行转行或者求职的最佳时间。离2021年结束还剩最后的76天,数据科学求职火热度丝毫未减,各个专业的PhD、Master的同学都在前赴后继的转行数据科学,如果你也想加入数据科学大军,那应该如何行动,需要掌握哪些知识呢?数据应用学院的首席数据科学家——Jason老师,教你如何在6个月内成功转行数据科学!如果你想了解更多数据分析相关内容,可以阅读以下这些文章:
想转行数据科学,你需要做什么?
想转行数据科学吗? 这里有三种场景和方法
广告行业转行数据分析——Data Science在Digital Ads行业的求职与应用有哪些?
MBA转行商业分析师的四点建议
那就让我们开始吧!
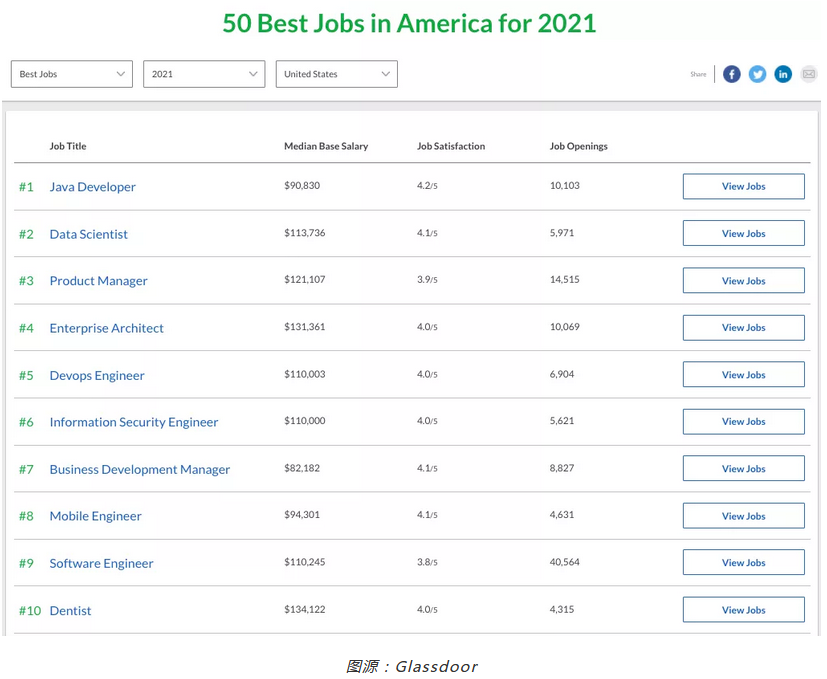
首先,大家可以去Glassdoor这个网站里看一下上图中的数据——2021年美国的五十项最佳工作,可以看到排在第一名的是Java Developer,工资是90830美元/年(这个数字一般是工资中位数);第二名是Data science,工资113736美元/年。
Glassdoor每年都会公布这个排名,对比去年的数据可以看到,今年的排名是有所提升的,所以说数据科学家现在仍然是市场上比较受欢迎的一个工作岗位。
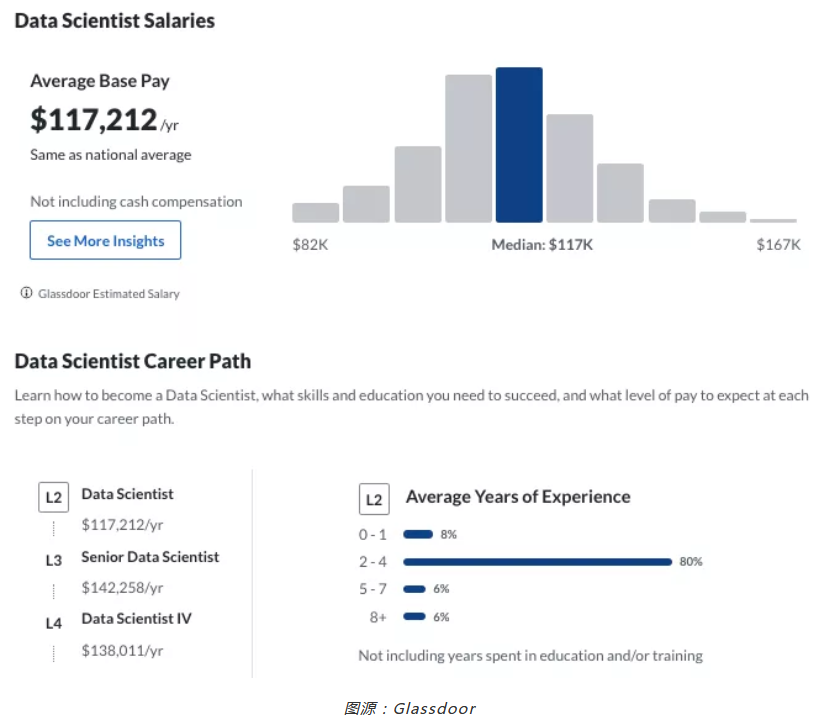
这张图同样来自于Glassdoor,是一张工资分布图,图上的Career Path,也就是职业路径,有一个数据非常有意思,数据科学家L2,工作年限是2-4年,很多同学觉得门槛太高。
其实不是的,这里大家需要稍微注意一点,很多数据科学行业都存在大量的转行现象,比如有的同学原本学习的是理工科,比如化工、物理、石油等专业,或者文科同学,学习心理学、语言学、经济学等等各种各样的专业,他们都有可能会考虑转行去做数据科学方面工作,但大家的工作经验从哪里来?实际上只要在研究生期间帮老师做过一些相关的工作,都可以算到这个2-4年工作经验的范畴里,所以大家不用觉得门槛很高。
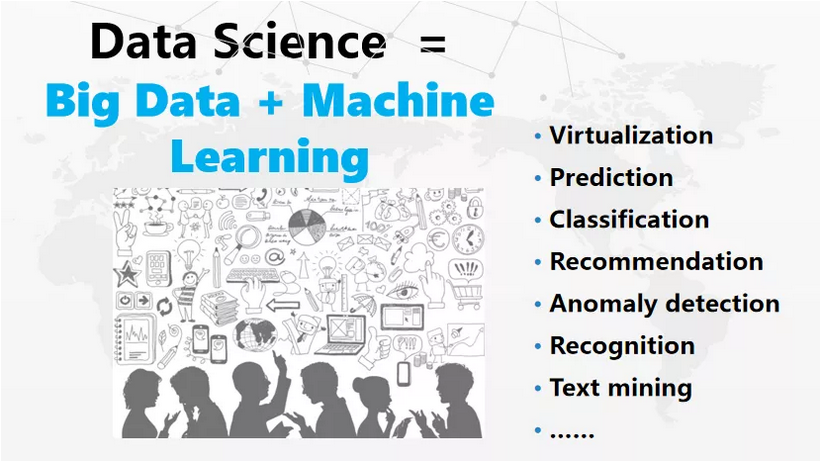
我们再来看看什么是数据科学,2014年秋季我在UCLA做了第一次关于数据科学的讲座,当时讲到,数据科学是什么呢,其实是Big Data+Machine Learning。数据科学首先要有大数据的基础和技术,从简单到复杂,我们可以看到,一些简单的Prediction、Classification、NLP、Recommendation、Anomaly Detection、Recognition、Test Mining这些都是包括在数据科学里边的。
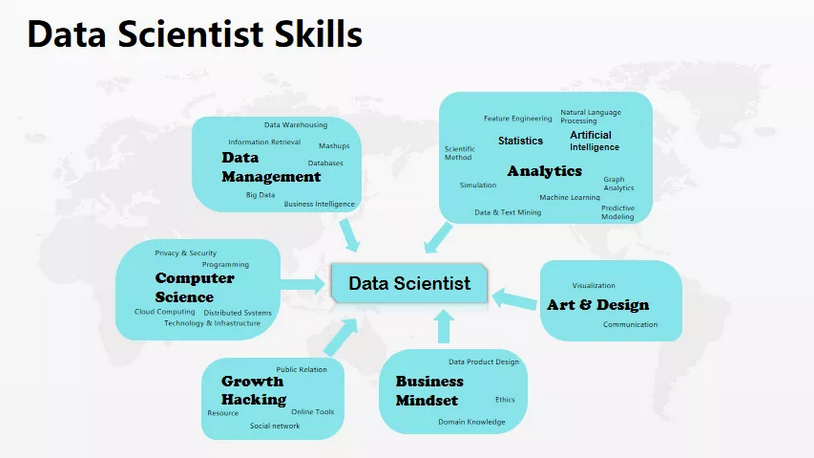
我们先总体介绍一下数据科学家应该具备的技能。
第一类:数据相关技能
包括Data Warehousing、Big Data、Database等在内,这些都是数据科学家的基本技能。
第二类:分析类
需要会概率统计(是做分析的基础)、人工智能相关(主要是机器学习方面的知识),因为我本人上学的时候学的是人工智能方面的研究,当时我们实验组分很多方向,每个组都很大,比如自然语言处理,计算机视觉、机器学习深度学习、搜索优化、机器人团队等等,数据科学方面我们主要用的是机器学习方面的知识。但现在有了一些变化,自然语言处理和计算机视觉也渐渐的被应用进来。
第三类:Growth Hacking方面
并不是每个数据科学家都会用到它,但有的公司需要。比如说,Facebook就非常注重这方面。最近闹的沸沸扬扬的Facebook前员工在国会作证关于他们公司内部的一些情况,有一些朋友来问我,为什么会是数据科学家来作证?
首先,数据科学家在Facebook这家公司的数据方面权限是很大的。在其他公司可能会需要自己写一些大数据的东西,但Facebook的Information Structure做的非常好,几乎可以实时的看到全世界范围的Facebook用户情况。
第二点是,他们的数据非常透明,很多前辈在过去几年写过的各种各样的数据,后面的员工可以直接拷贝过来修改一下,变成自己的研究,每个数据科学家想去做研究都非常powerful,这也就是为什么一个数据科学家可以去国会作证,因为他手里边确实是可以拿到这些相关信息的。
另外,还需要学习一些BI类的东西。所以,同学们需要有所侧重,想清楚自己想做哪方面的数据科学家。比如,你想做偏数据处理方面的工作,那么你的分析和数据库、大数据方面技术就需要加强。你也可以做偏分析类的,那就加强Business Mindset和分析类知识。或者做建模这一类,需要加强MLSE(Machine Learning Software Engineer),机器学习方面也需要努力的加强。选不同的方向,就要有不同的侧重,我们后面会看一些大公司的岗位,再具体分析。
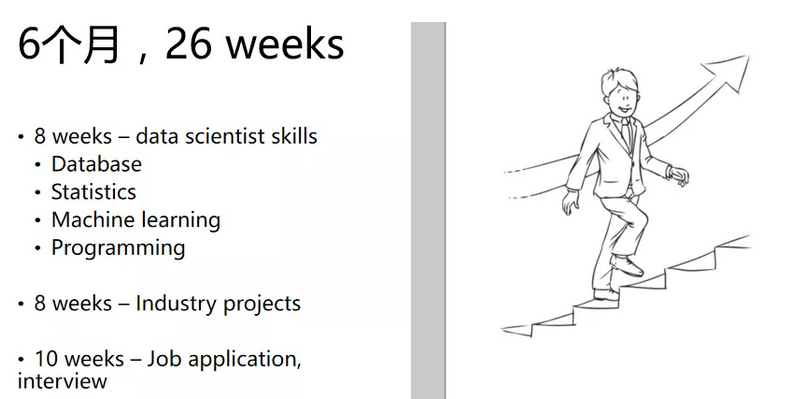
接下来,让我们看看时间的安排。学习数据科学需要付出大量的时间,每周的学习时间要保证有20-30小时,持续6个月的时间。首先,我们拿出8周的时间学习基本技能,接下来8周学习行业的项目,约10周的时间做岗位申请和面试(根据协会公布的数据,平均一个招聘周期大概是28天,那么Job申请至少需要6周时间,剩下的4周,需要刷一些数据科学的题),这是我们的目标,是我们大概的时间安排,每一项的安排我们下面会仔细的讲解,以及我们为什么花这么多时间在job申请这一部分。
我们学习中刷题这部分,是指数据科学(Data Science)的题。下面我们来看看前8周,这8周我们主要着手于数据处理(Data Processing)这一部分,包括数据库基础(Database Basic), SQL编程(SQL Programming),ETL,Data Pipeline,以及 “Best Practice in Data Processing”这本书;编程这一部分,主要会用到Numpy,Pandas。
我们为期16周的数据科学家求职训练营的安排也是这样的——前面8周主要是技能方面,后面8周主要是Project。分为两个部分:
- 数据处理
- 统计(Statistics)
目前,统计和概率(Probability)是分析的基础,而且在面试的过程当中,很多公司非常喜欢问一些基础问题。因为,数据科学领域存在一些“调包党”,这些人可能不是那么了解基本原理,但是他们可以迅速地调用packages,成功完成项目。Github上很多人check in一些代码,然后运行这些代码。这种操作其实都是可以的,但是我建议大家在基础方面下点功夫,做到知其然,知其所以然,这一点是非常重要的。
而数据部分就包括概率(Probability),Sampling,Tendency and Distribution of Data, Hypothesis Testing, AB Test, Regression。我认为,Regression是统计和机器学习(Machine Learning)的交叉,这两个知识领域都有一些重合。所以,Regression可以放在统计这部分,也可以放在机器学习这部分。现在,越来越多的人开始重视AB Test,因为很多大厂的许多数据科学家就是做AB Test。我们数据应用学院专门举办过关于AB Test的数据科学读书会,主要讲了两本书:2019年讲了一本《A/B Testing》,今年又讲了一本《A Practical Guide to A/B Testing》。
下一部分就是机器学习(Machine Learning)。这一部分主要以Python为主,我们主要可以把机器学习分为五大类:
- 第一,基于统计的分析,比如前面提到过的分布(Distribution)、Hypothesis Testing等
- 第二,分类器(Classification)
- 第三,Regression
- 第四,聚类(Clustering)——非监督式机器学习的一部分
- 第五:时间序列分析(Time Series Analysis)
这五大部分就是我们平时接触最多的数据科学所应用的知识。深度学习(Deep Learning)要单读判断,因为有些团队会用到,有些团队不会用到。在有限的时间内,你要根据自己的时间和经历,合理地安排学习计划。我知道,有些学生对Deep Learning一无所知,但是仍然可以找到数据科学家的工作,因为有些团队的确不使用Deep Learning。但有些团队可能不太使用传统的机器学习方法,所以,这类团队主要使用深度学习这类方法。大家需要适当地作出取舍。
下一部分主要是和Computer Science Algorithms有关。在学习这一部分内容时,无论转行之前你学习的专业是什么,都应该学习一些计算机基本算法以及数据结构。这样做的好处有很多。
一、可以提升你的编程能力
因为编程都是基于Computer Science,包括数据结构、编程语言,软件研发里的软件设计、编程、测试、发布等,这和数据科学家项目周期里的内容基本一致。因为这两者之间存在一定的关系。那么问题就来了,我们一共就6个月的时间,这对于转行Computer Science是不够的。比如,你本来是做物理的,你想转行做码农,你怎才能在有限的时间里打下一定的基础呢?
我个人认为,你可以花一周时间学习基本的数据结构,比如说什么是Site、List、双向链表、单向链表,算法方面的搜索和排序,了解其中的算法。这里面比较难理解的就是时间复杂度和空间复杂度。因为这部分和CS底层的东西比较相关。空间复杂度是指内存使用情况;而时间复杂度是指O(n)还是O(Logn)还是O(n2),即算法在数据成量级增加后的运行快慢情况。具体来讲,如果你能搞定Leetcode里面的100题,基本上也就达到了我们的标准,但如果只搞定了50题,也是可以的。因为Computer Science可以为几大方面作准备,包括你将来申请工作时可能会有OA,别人发来的OA可能会包括一些Pite方的题目;
二、面试过程当中,有一些面试官喜欢考察Scalability方面的功底
下一部分就是Big Data。Big Data其实和Computer Science有很多交叉。国内的Big Data被称为大数据,没有数据科学的概念,但是在美国会把这两部分区别开来。
大数据主要和数据存储、管理大范围的数据有关,而数据科学主要与分析有关。Big Data包括分布式算法,例如Map Reduce,平台操作系统,例如Hadoop、Hive、Spark,这三者我们至少需要掌握其中一项。我们学院办公室机房有自己的机柜,里面有三个大数据Cluster,其中有一个是面向学生开放的。这样你就不需要花钱买亚马逊的Cluster,直接登录即可学习Hadoop和Spark的应用。这部分其实是一个加分项,因为很多Job Description里都包含这几项加分的技能。
所以,大家要用8周的时间学习这些技能方面的基础知识,后面8周主要和Project有关。
为什么Project很重要呢?主要有以下三个原因:
第一,转行之前你没有做过此类工作,因为你不是该专业的学生,或者你之前做的一直是自己领域里面的分析,现在的数据分析越来越多的与E-Commerce、Finance、Health Care、Government有关。最近,一家专门致力于大数据分析的公司正在和微软(Microsoft)竞争,这个公司叫做Prantir。两家公司正在争抢一个为期8年的政府数据项目,该项目价值10亿美金。该公司的业务领域主要就是在政府这一部分,包括防恐等。
大家也可以看到,政府也越来越重视大数据这一领域。大数据已渗透至多个行业,如果你在转行之前没有这方面经验,你是否需要开始接触project这方面的知识,获得相关经验?我们之前学过的知识其实都要应用至project。
第二,你的简历项目可能一片空白。我曾经看过一些学生的简历,大部分PRT的学生的学术水平都非常高,内容可达三四页,其中论文就能占到两页左右。但是简历中没有数据的项目,这就意味着如果改行做码农,就必须要刷题;如果改行做数据科学家,必须做项目,为你的简历增加和项目有关的内容。
第三,转行之前你的工作和E-Commerce无关,但转行之后,你要去Amazon、Ebay这样的公司工作,这时就要求你要获得行业的知识。你要大概了解你做的这些项目,对这些项目有一个基本分析,比如什么是销售渠道、SalesFinal、User Lifetime Value、转换逻辑,什么是RFM,即通过用户在平台购物的频率,以及该用户最近一次购物的时间,从而分析用户的忠实率,RFM就是一个重要的indicator。
所以,刷项目就有以上三个好处,第一,获得一些hands-on的经验;第二,简历里面有一些加持;第三,你要获得一些行业垂直的经验。
下面举了我们数据科学家求职训练营的一些项目,同学们可以根据个人兴趣做适当的取舍。

Project 1是一个房地产的项目,大家可以练习pandas的数据处理,Project 2也使用了房地产项目练习数据清洗,Project 3是FinTech信用卡的项目分析做Default的分析。
请注意,Default和fraud分析不一样的,fraud指的是欺诈,欺诈的人本来没想着要还钱,申请信用卡就是为了骗钱,default是本来想还钱但是还不起了,本来申请信用卡每月都还,但是比如最近因为失去工作而还不了。这里是建立一个feature组,根据某一点向前去推的基于时间序列,与传统时间序列分析不太一样。用到的只是比如Classification(分类器)。
How to handle imbalanced dataset,这又是一个大的topic,imbalanced data其实是在我们建立分类器里比较有挑战的一个training。举一个简单的例子binaray分类器,0特别多,1少的情况,大部分都是正常地使用信用卡,进行欺诈的人,不管是账户级的还是transaction级的都是非常少的,但是机器学习不一样,机器学习是在数据集里通过machine learning算法去找到这个pattern,更倾向于提取majority多的部分,相反就忽略了minority较少的部分,所以需要一种技术去处理这部分,也就是分类器。
也可以用Resampling方法,Resampling又包括up-Resampling和down-Resampling,up-Resampling把minority—少的部分增多,比如,有n-fold cross validation,n-fold是n组的分组时候,可以每一组把所有少的集合都放入进去,把多的部分进行分组,这样就能平衡。或者使用smote,smote是在现有的样本里产生一些新的样本。还有在算法部分使用penalty函数对minority加权,去适应前面说的问题。
Project 4是Insurance保险,一般情况下,医疗类的保险较多,但是我们有同学拿到了有家auto公司的这个offer,像kaggle一样有许多在车辆保险方面的应用数据分析。

- Project5是教育数据分析的项目,同学们可以考虑学校的工作,因为学校不属于盈利单位,可以解决H1B抽签问题。
- Project 6是Airbnb New User Bookings。Airbnb是一个酒店/民宿,是一个progressive项目,预估一个user去到什么地方去旅行,哪些民宿适合他。
- Project 7是HR人力资源方面的一个项目。
- Project 8,Store Item Demand横跨supply chain和E-commerce两个领域,如果知道需求,supply chain的优化就会非常方便。
这里,我们使用的是Time Series Analysis方法,Time Series Analysis和我们刚刚讲的分类器和regression不同,它有它自己的特点。它是一个sequence data,样本之间的时间窗口一致的,比如股票数据,周平均值和每天开盘价是无法使用时间序列预测的,一般以周为窗口看股票的长短期趋势。有家量化投资公司就是日交易为准,使用计算机做好的软件,每分钟进行一次计算,捕捉短期变化的indicators,进行交易,比如今天买明天卖,上午买下午卖,其特点就是高频、短期、计算机辅助。

- Project 9是Diabetes Readmission,糖尿病人治疗结束后30天后重新入住,医院和疾控中心对这些项目较为感兴趣,一旦你build一个模型预估重新入住,对整个医疗行业的提升有很大的帮助。
- Project 10是怎么优化Facebook Ads,这和优化Amazon广告是很类似的。
- Project 11,FinTech是build一个的P2B的App,是一种风控的模型。
- Project 12是Life Time Value分析,包括RFM和MBG model。

- Project 13推荐系统,它是数据科学较大的分支,搜广推—即搜索、广告和推送,是大厂主要的数据科学的应用,一个综合性的系统。
- Project 14是一个customer churn prediction,前面有提到。
- Project 15 是NLP自然语言处理。
- Project 16,Alexa是Amazon为智能家具准备的语音控制设备,例如无人机可以通过过系统远程操控,查看家里的情况,这里是做一个自然语言的处理。
总而言之,搜广推是一个重要应用,在技术方面,NLP作为基础底层技术越来越得到广泛的应用。
面试准备
在项目和题目准备好之后,我们就可以开始申请工作了,现在我会以Facebook,Amazon,Google等几个大厂为例介绍一下。Facebook有大量的Data Scientist,偏Product分析还是Business,具体需要看一下具体的岗位要求。我们同学在Onsite的一些情况,Quantitative其实就是数据分析这一块的,然后还有一些数据库,Data Transformation,这也是数据科学的考核内容。

首先让我们来看Facebook。Facebook非常重视case的题目,比如,他们会给你一个商业场景,用Data Driven的方法对商业场景背后的一些问题来进行相关性和因果性分析,提供一个解决方案;还有就是Applied Data,实际上就是怎么用数据去解决一个商业问题;接下来,还有一些Quantitative分析,它包括一些应用统计问题、因果分析、相关性分析。他们比较喜欢问的问题包括 Estimation、逻辑分析、分布等等。技术方面包括structuring and articulating a solution based on data,还有一些coding的问题,主要是SQL。
接着是Edge Case,面试官给一道SQL题,紧接着有一些Follow Up,例如,你怎么去分析一些边缘情况,比如分布为0,一些特别的case怎么理解为他是让你问题更有鲁棒性,你这个程序怎么能稳定,怎么能不要运行出错等等。Data Transformation主要是数据库方面。
第二个,我用LinkedIn为例。相对来说,LinkedIn数据分析的分量也很大,特别是被微软收购之后,他们在持续地发展。面试第一轮是HR的面试,两轮技术面,接着是onsite。常见的问题有:你为什么对这个岗位有兴趣?在Phone Interview中,Facebook会问Why Facebook?亚马逊也会问Why Amazon?你为什么对这个岗位有兴趣?为什么对这个公司有兴趣?最后,还需要花一些时间去准备behavior的一些问题。
技术面试基本是SQL、Python,大部分的数据科学家都会问这两个方面的问题,除非你面试比较特别的岗位,比如MLSE(Machine Learning Software Engineer),就是机器学习软件工程师,可能会有一些Machine Learning算法的推导,比如分析Linear Pearson correlation基本的公式、方法是什么,SVM、Classification它的基本的方法,如画两条线,让你算有几种距离。技术面试很多公司都有Product Sense问题,包括Facebook、LinkedIn、Amazon、Capital One,但比如你要去Capital One,就不叫Product Sense,叫role play,你是这个角色,你在公司做这个工作,你有这个责任,面试的过程中被放到这个角色中,然后去提问一些面试的题目。
假设你到公司从事这个工作,给你几个这样的Case,和Product Sense一样,有一些问题可以是:你想去提升某个feature,应该怎么做?设计一些metrics,还有比如How would you classify job seekers among LinkedIn users?常见就是两种方法,Supervised和Unsupervised,Unsupervised要做Clustering,而Clustering有自己的一套东西,比如N值。把N值计算出来之后做聚类分析,聚类分好簇之后你对每个簇的feature进行分析。
Onsite基本5-6轮,有偏重编程的,有偏重Product Sense的,之后可能会有一些Behavior。

第三个是Amazon。可能比LinkedIn简单,基本现在面试是很快的,两轮三轮解决,HR只负责Email,不参与面试,最多打电话通知情况,基本上来就是HM 技术面,可能一轮,也可能两轮;接着就是Onsite,大概2-5天出结果,Amazon是非常有效率的。如果要面试Amazon,面试之前会给很多相关资料,给你一个PDF介绍如何去准备面试,比如,他们告诉你会涵盖哪些topic,例如Machine Learning Algorithms、Data-Driven Modeling、Programming Languages、Coding、Databases怎么考,会给一个instruction;
这里给大家一个建议,如果你去面试Amazon的话,最好学习一下亚马逊的商业逻辑,他会有一些垄断方面的东西,Selection、Sellers、Customer Experience、Lower Cost Structure、Lower Prices、Traffic等,大家可以稍微研究一下。
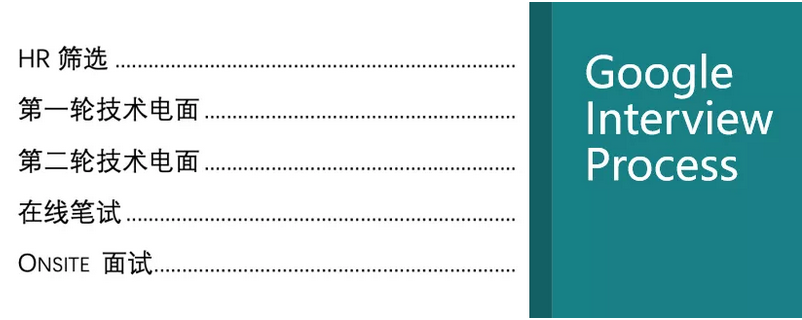
第四个是Google。中规中矩,如果去Google面试的话,建议刷200-300道题,因为Google的企业文化就是一堆码农,所以更愿意考编程的题。面试流程也是HR面,技术面两轮,现在比较流行在线笔试,很多公司都有,Google因为比较重视coding,所以加了一个这个。接下来是onsite。Phone Interview大体也是Why Google、Why leave current company、Tell me about your experience,还有一些商业型的问题,比如 What if Gmail start charging $20。Onsite也包括统计、编程、Product、纯数据的一些分析和一些behavior问题。
以上就是这个6个月转行数据科学的方法。讲到这里,相信你对转行数据科学已经有全面的了解!你还可以订阅我们的YouTube频道,观看大量数据科学相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
Recap 作者:明慧
美工编辑:过儿
校对审稿:佟佟





