
如何在方差和偏差中取舍,找到平衡点?
了解这些预测误差是如何产生的,以及如何使用它们,将帮助你构建准确且性能良好的模型,而且还可以避免过拟合和欠拟合。如果你想了解更多关于数据科学的相关内容,可以阅读以下这些文章:
如何准备娱乐/游戏行业数据科学家面试
如何成为FAANG自驱式数据科学家的一员?
Data Science如何刷题?怎么刷?数据科学求职新趋势!
谷歌数据科学家面试真题
你可能听说过偏差-方差权衡并想,“嗯?”或者,也许你根本没有听说过它并且在想,“那到底是什么?”
无论哪种方式,偏差-方差权衡都是监督机器学习和预测建模中的一个重要概念。当你想训练预测模型时,可以选择各种监督机器学习模型。它们都是独一无二的,有相似之处——但最大的区别是它们的偏差和方差程度。
当涉及到模型预测时,你将关注预测误差。偏差和方差是在许多行业中广泛使用的预测误差类型。当涉及到预测建模时,在最小化模型中的偏差和方差之间存在权衡。
了解这些预测误差是如何产生的,以及如何使用它们,将帮助你构建准确且性能良好的模型,而且还可以避免过拟合和欠拟合。
从二者的定义开始。
什么是偏差?
偏差是由于从数据集学习信号的灵活性有限,导致模型结果出现偏离的因素。这是模型平均预测值与试图预测的正确值之间的差异。
当你遇到具有高偏差的模型时,这意味着该模型在训练数据上没有很好地学习。这进一步导致了训练数据和测试数据的高误差,因为模型由于没有学习任何关于特征、数据点等而变得过于简单。
什么是方差?
方差是模型在使用不同的训练数据集时的变化。它告诉我们使用不同数据集时数据的传播及其敏感性。
当你遇到一个具有高方差的模型时,这意味着该模型在训练数据上学习得很好,但是它不能在测试数据上很好地预测。因此,这将导致测试数据的高误差率,并导致过拟合。
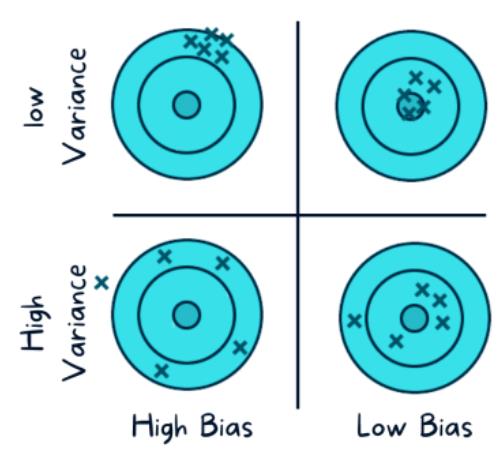
那么什么是偏差和方差权衡?
谈到机器学习模型,这也是在方差和偏差中找到平衡点。
如果模型太简单,可能会导致高偏差和低方差。如果模型过于复杂,包含多个参数,可能会导致高方差和低偏差。因此,我们的目标是找到不会发生过拟合或欠拟合的完美点。
低方差模型(如朴素贝叶斯、回归等)通常不太复杂且结构简单,但是存在高偏差的风险。这会导致欠拟合,模型无法识别数据中的信号,从而无法对测试数据进行预测。
低偏差模型(决策树、K近邻等)通常更复杂且结构更灵活,但是存在高方差的风险。当模型太复杂时,会导致过拟合,因为模型记住了数据中的噪声,而不是信号。
如果你想了解更多关于如何避免过拟合、信号和噪声的信息,请单击此链接。
这就是方差和偏差权衡发挥作用的地方。我们需要在Bias和Variance之间找到合适的中间值,以最小化总误差。让我们深入了解总误差。
数学知识
从一个简单的公式开始,预测的是“Y”,其他变量是“X”。两者之间的关系可以定义为:
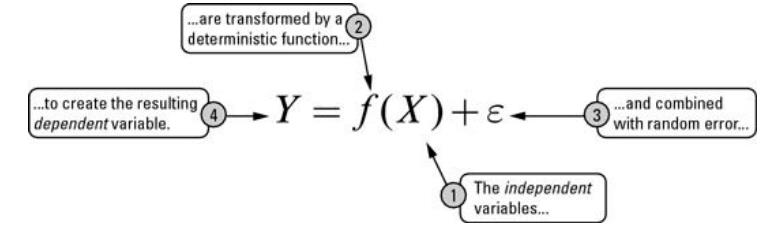
‘ε’ 指的是错误项。
然后可以将点x处的预测平方误差定义为:
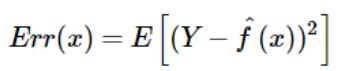
然后:
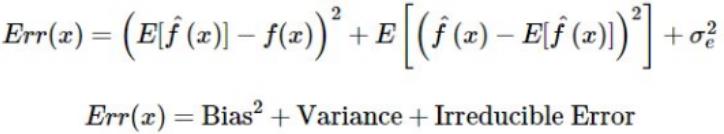
Irreducible Error意味着无法通过模型来消除“噪音”——减少它的一种方法是数据清理。
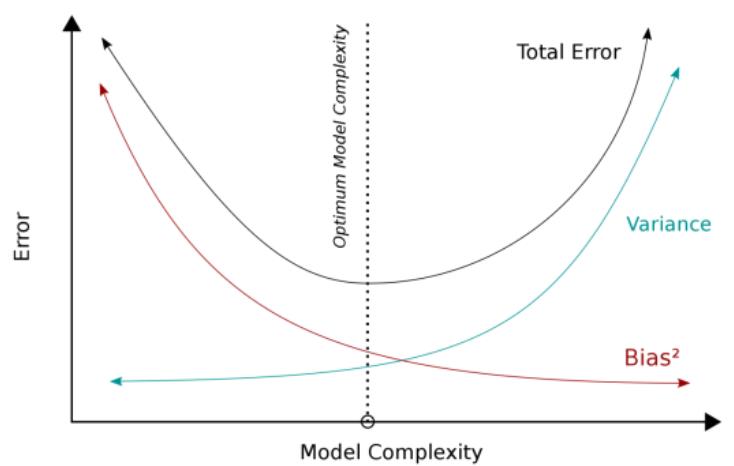
但需要注意的是,无论你的模型多么出色,数据总是有一个无法消除且不可减少的误差元素。当你在偏差和方差之间找到最佳平衡时,你的模型将永远不会过拟合或欠拟合。
结论
希望在本文中,你能够更好地理解什么是偏差、什么是方差以及它们如何影响预测建模。你还将了解两者之间的权衡,以及找到合适的平衡点来生成不会过拟合或欠拟合的最佳性能模型,感谢阅读。你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
Nisha Arya是一名数据科学家和自由撰稿人。她对提供数据科学职业建议或指导以及数据科学相关的理论知识特别感兴趣。她还希望探索人工智能是可以有益于人类寿命的不同方式。她是一位敏锐的学习者,在帮助指导他人的同时,努力拓展自己的技术知识和写作技能。
原文作者:Nisha Arya
翻译作者:明慧
美工编辑:过儿
校对审稿:Miya
原文链接:https://www.kdnuggets.com/2022/08/biasvariance-tradeoff.html




