:对现在Netflix-最受欢迎的电视剧的分析.jpg "Bridgerton(布里奇顿):对现在Netflix 最受欢迎的电视剧的分析")
Bridgerton(布里奇顿):对现在Netflix 最受欢迎的电视剧的分析
本文使用了 Python 和 Tableau 中的 NLP 技术,分析针对Bridgerton(布里奇顿)电视剧的 300,000 多条推文。如果你想了解更多数据分析相关内容,可以阅读以下这些文章:
数据分析的Regression算法到底是什么?
Meta问世——他们会开放哪些数据分析岗位?
假期将近——旅游行业是如何应用数据分析的?
数据分析新工具MindsDB–用SQL预测用户流失
Bridgerton(布里奇顿)系列剧在圣诞节上映后,火爆全国甚至全世界。几乎所有电影爱好者都在讨论这部电视剧,因为网上铺天盖地的宣传,我“被迫”在 Netflix 上看了这部剧。最近,美国有线电视新闻网(CNN)报道称,Bridgerton是“Netflix史上最成功的电视剧”,其播放量已超过8200万户。
然而,真正引起我注意的是 Twitter 上的Bridgerton(布里奇顿)官方标签,这些标签为该节目增加了更多的热度。正如你在下图中看到的那样,电视剧名称后边都附有一个特殊的标志。如果你问我这些标签有什么用,我会说这是一个很棒的营销策略!

(图片来自 Jessica Uwoghiren)
介绍
对于该项目,我决定在我上一个情绪分析项目的基础上,根据 Twitter 用户对Bridgerton评价,进行分析。项目中用到的是2020 年 12 月 27 日至 2021 年 1 月 28 日期间的推文。此外,这个分析只包含了英语的推文。我可以说,如果你在那段时间使用过任何 Bridgerton 的话题标签,或在你的推文中提到过“Bridgerton”,那么你的推文就会在这个分析里。
关于这部电视剧,我想了解以下几点:
- 最受欢迎的Bridgerton话题标签
- 最受关注的Bridgerton角色
- 普通观众对Bridgerton的看法
- Twitter中有关Bridgerton的常用词汇
项目策略
我的项目步骤如下所示。我之前详细讨论过一些重要概念。因此,在本文中,我将主要展示用于实现一些分析结果的部分 Python 脚本。
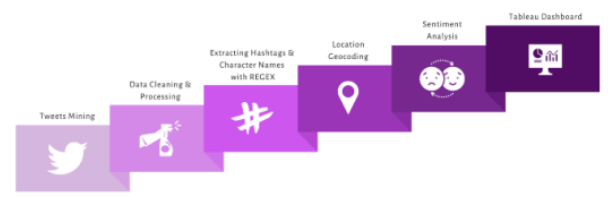
(图片由 Jessica Uwoghiren 通过 Canva 生成)
本项目中用到的 Python 库包括 Pandas(用于数据清理/操作)、Tweepy(用于推文挖掘)、NLTK(用于文本分析的自然语言工具包)、TextBlob(用于情感分析)、Matplotlib 和 WordCloud(用于数据探索)、Emot(用于emoji的识别)、Plotly(用于数据可视化)和其他内置的库。
推文挖掘
过去一个月,我用平台自带 API 和 Python 库 Tweepy,收集了Twitter推文。如果要用 Twitter 的 API,你只需要在创建 Twitter 开发者帐户后获得一些凭据。你还可以查看我的上一篇文章,了解如何使用 Twitter 的 API。在搜索查询中,我使用了“Bridgerton”和所有Bridgerton的官方标签。我甚至添加了错误的拼写,例如,为拼错电影标题的用户添加了“Brigerton”标签。详见下方代码。
# Access keys and codes you need from your Twitter Developer Account
consumer_key = 'XXXXXXXXXXXXXXXXXXXXX'
consumer_secret = 'XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX'
access_key= '##########-XXXXXXXXXXXXXXXXXXXXX'
access_secret = 'XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX'
auth = tweepy.OAuthHandler(consumer_key, consumer_secret) # Pass in Consumer key and secret for authentication by API
auth.set_access_token(access_key, access_secret) # Pass in Access key and secret for authentication by API
api = tweepy.API(auth,wait_on_rate_limit=True,wait_on_rate_limit_notify=True) # Call API module on tweepy and sleep when limit is reached
# Create a fucntion to mine tweets and its attributes
def get_tweets(search_query, num_tweets):
# Collect tweets using the Cursor object
# Each item in the iterator has various attributes that you can access to get information about each tweet
tweet_json = [tweets for tweets in tweepy.Cursor(api.search, q=search_query, lang="en",
tweet_mode='extended').items(num_tweets)]
# Parse through your returned json file to return only attributes you require:
for tweet in tweet_list:
tweet_id = tweet.id # get Tweet ID result
created_at = tweet.created_at # get time tweet was created
text = tweet.full_text # retrieve full tweet text
location = tweet.user.location # retrieve user location
retweet = tweet.retweet_count # retrieve number of retweets
favorite = tweet.favorite_count # retrieve number of likes
with open('tweets_bridgerton.csv','a', newline='', encoding='utf-8') as csvFile:
csv_writer = csv.writer(csvFile, delimiter=',') # create an instance of csv object
csv_writer.writerow([tweet_id, created_at, text, location, retweet, favorite]) # write each row
# Parameters to Mine from Twitter API
# Specifying exact phrase to search for. This is not case senstitive
search_words = "Bridgerton OR Brigerton OR #bridgerton OR #brigerton OR #bridgertonnetflix OR #brigertonnetflix OR #BridgertonLiveTweet"
search_query = search_words + " -filter:retweets AND -filter:replies" # Exclude retweets, replies
get_tweets(search_query,50000) # Call your function and pass in your search query and number of tweets you want to get
Bridgerton推文挖掘的 Python 脚本
(本代码由Jessica Uwoghiren编写)
数据清洗与处理
我一直说,大概80% 的数据科学或分析项目都是围绕这一步展开的。想象一下,你要处理 300,000 多行数据,你不可能检查每一行的正确性或完整性。在所有数据项目中,缺失值始终是一个大问题。在本项目中,Location 列有很多缺失值,因为只有少数 Twitter 用户在个人简历中添加了正确位置。我还需要使用“Tweet ID”确保没有重复的推文,这是我的数据集的Primary Key。详见下方 Pandas 数据框。
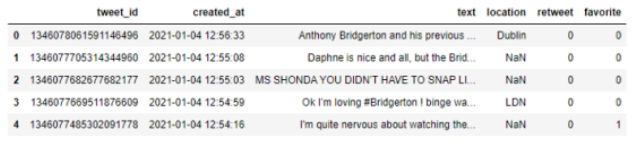
(截图来自Jessica Uwoghiren的Jupyter Notebook)
使用正则表达式(REGEX)从推文中提取标签和字符名称
我非常喜欢这部分的分析内容。我想看看哪些官方推特中的“Bridgerton”话题标签和角色名最受欢迎。我必须找到一种方法,从每条推文中提取这些信息,并将这些信息返回至我的数据框中的新列。我是怎么做到的?答案是REGEX,即“正则表达式”,用于指定你想要匹配的字符串模式。经证明,这种方法是有用的。对于字符名称,我用 REGEX 更正名称拼写错误的地方,详见下方代码。
# Created a function "getHashtags" to extract all hashtags from each tweet
def getHashtags(tweet):
tweet = tweet.lower() #has to be in place
tweet = re.findall(r'\#\w+',tweet) # Remove hastags with REGEX
return " ".join(tweet)
# Return all hashtags to a new column in my data frame
tweets_df['Hashtags'] = tweets_df['Tweet'].apply(getHashtags)
#Extracting Movie Characters
# Full list of first names of all characters in the Bridgerton TV series.
# Note that I did not use their last names to avoid duplication
# In cases where their First name starts with "Lady" or "Prince", I used their last name
bridgerton_characters = ['daphne','dapne','simeon','simon','anthony','siena','sienna','whistledown','danbury','eloise',
'gregory','phillip','philip','marina','colin','collin','hyacinth','penelope','benedict',
'portia','francesca','charlotte','charlote','philipa','phillipa','prudence','cressida','cresida',
'nigel','reine','wilson','colson','humboldt','rose','jefferies','brimsley','henry','cowper',
'violet','lucy','genevieve','mondrich','varley','friederich','harry']
# Created a function "getMovieCharacters" to extract names of Bridgerton Characters from each Tweet
def getMovieCharacters(tweet):
tweet = tweet.lower() # Reduce tweet to lower case
tweet_tokens = word_tokenize(tweet) # split each word in the tweet for parsing
movie_characters = [char for char in tweet_tokens if char in bridgerton_characters] # extract movie characters
return " ".join(movie_characters)
# Extract Movie characters to a new column in my data frame
tweets_df['Movie_Characters'] = tweets_df['Tweet'].apply(getMovieCharacters)
# Created a function "correctNames" and used REGEX to replace wrongly spelled character names
def correctNames(movie_characters):
replacements = [('dapne','daphne'), ('simeon','simon'), ('sienna','siena'), ('philip','phillip'),('collin','colin'),
('charlote','charlotte'),('phillipa','philipa'),('cresida','cressida')]
for pat,repl in replacements:
movie_characters = re.sub(pat, repl, movie_characters) # Replace characters names with correct spellings where applicable
return movie_characters
# Extract Correct Movie characters to a same column in my data frame
tweets_df['Movie_Characters'] = tweets_df['Movie_Characters'].apply(getMovieCharacters)
从 Bridgerton 推文中提取标签和字符名称的 Python 脚本
(代码由Jessica Uwoghiren编写)
根据上述分析,最流行的 Hashtags 如下所示。
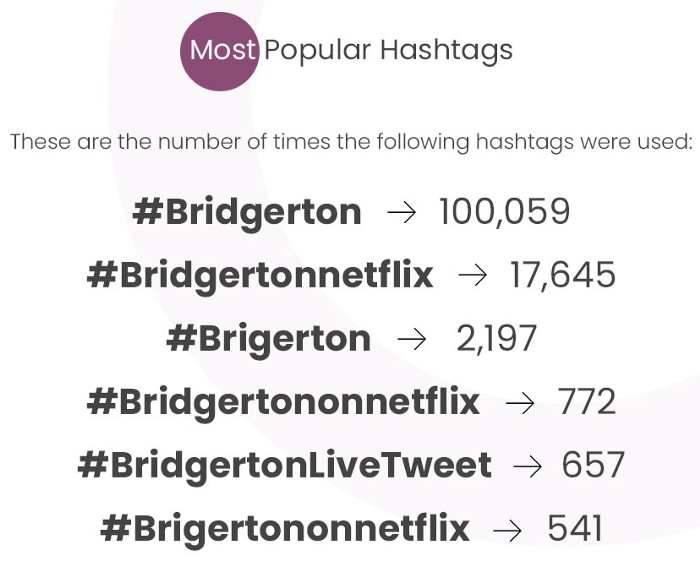
Bridgerton 推特标签出现的频率。
(图片由Steve Uwoghiren通过Adobe Photoshop生成)
Bridgerton推文中的词频
对于这部分分析,根据推文中使用的单词频率,我使用 WordCloud 库生成了Word Cloud 图像。Matplotlib 库中的 Pyplot 模块被用于显示下图。WordCloud中的字体越大,表示该词出现频率越高。
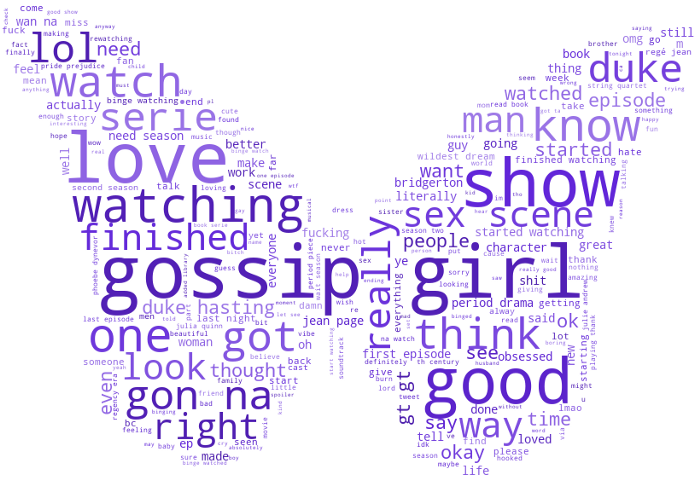
关于Bridgerton(布里奇顿)电视剧的推文中最常用的词
(图片由Jessica Uwoghiren使用WordCloud和Matplotlib库生成)
位置地理编码
为了确定哪个国家/地区发布的关于布里杰顿电视剧的推文最多,我使用了位置地理编码(Location Geocoding),这是一种返回至给定城市、地点、州或国家的精确坐标的特殊方式。我这样做是因为,大多数 Twitter 用户只在他们的简历中使用“州”或“城市”,而我需要检索国家名称。我使用了 Developer Here API 返回每个推文位置的国家代码(Country Code)和国家名称(Country name)。
情绪分析
最后,我想看看大家对Bridgerton的整体看法。为此,我使用了自然语言处理 (NLP) 的机器学习技术。这是处理人类文本或文字的另一种特殊方式。NLP 有几个方面,其中最重要的是“情绪分析(Sentiment Analysis)”。
对于本文的分析,我使用了Python TextBlob 库中的 Sentiment Analyzer 。该算法通过给每个句打分,分析句子中的情绪。根据极性分数(Polarity scores),我们可以定义推文的情绪类别。在本项目中,我将负面推文定义为极性得分 < 0,而≥ 0 为正面推文。情绪类别的分布如下所示。点击此处查看 Tableau 仪表板中按国家/地区的情绪类别分布。
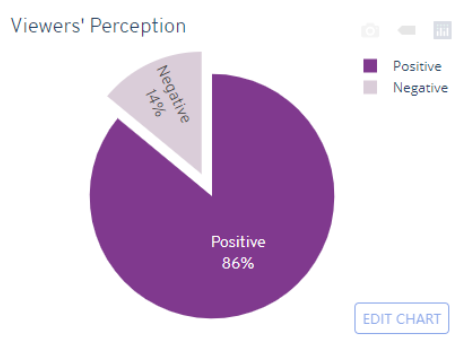
基于 2020 年 12 月 27 日至 2021 年 1 月 27 日推文的观众对Bridgerton的整体看法
(本图表由 Jessica Uwoghiren 使用 Python 的 Plotly 库生成)
结语
感谢你的阅读!你可以关注我们各个平台账号,了解更多数据科学相关知识。
原文作者:Jessica Uwoghiren
翻译作者:Lia
美工编辑:过儿
校对审稿:Jiawei Tong
原文链接:https://towardsdatascience.com/bridgerton-an-analysis-of-netflixs-most-streamed-tv-series-c4c9e2926397





