
Classification Algorithm 101: 一小时学会机器学习的分类算法
分类算法(Classification Algorithm)是一种机器学习算法, 主要为商业问题中的示例分配并且标签。一个易于理解的示例,是将电子邮件分类为“垃圾邮件”或“非垃圾邮件”。今天我们会带领大家学习机器学习中的分类算法,主要内容包括:Classification Overview、Basic Models、Evaluation、Applications.
今天的内容不会涉及太多技术细节,技术细节的内容大家可以在一些论文和教材里找到。今天,我们主要讨论应该怎样使用算法,这是我们在论文和教材里很难直接查阅到的知识;如何把一个商业问题转换为数据问题,甚至是数学问题,是数据科学家们面临的挑战。如果你想了解更多数据分析相关内容,可以阅读以下这些文章:
5种机器学习的分类器算法
Python机器学习库:pycarets新增时间序列模块
机器学习VS深度学习:有什么区别?
如何回答ML机器学习的面试问题?
从技术层面上看,算法究竟是怎么工作的?在实际工作中,我们认为某个东西是对的,那需不需要知道它为什么是对的呢?如果想要成为一个高级别的数据科学家,你需要知道为什么,只有知道为什么,才知道为什么可以用这样的算法或模型,去做预测。
对于越高级别的数据科学家来说,仅仅了解技术细节是远远不够的,更多的时候我们是要取得经验,了解应对各种问题时应该用的算法和模型,为什么这个模型可以用,以及怎样向非技术人员把这件事情解释清楚,是数据科学家去提升自己的最好办法。今天我们主要讲一些案例和模型,以及如何使用这些模型。
什么是分类算法?这个问题涉及到了两个机器学习基本概念,监督式学习与非监督式学习。在有标签、有真实值的情况下,是监督式学习;在无标签的情况下是非监督式学习。在监督式学习里又分为两种情况,一种分类(Classification),一种回归(Regression)。
另外,分类不仅仅可以做二分类(binary classification),也可以做多类分类(multi-class classification)。多类分类可以叠加成不同的二分类,然后一起解决。

Classification的算法是要远远多于非监督式学习的,这里列举的算法也不是全部,最简单的可以先从朴素贝叶斯Naive Bayes、支持向量机Support Vector Machine (SVM) 开始,然后还会有最近邻算法K-NEAREST NEIGHBOUR (KNN)——我们会找到一些中心,把这个点sign到与它相近的中心点上。还有Decision Tree、Random Forest、XGBoost、Light GBM、Voting Classifiers、Artificial Neural Network 这些算法。

对于任何算法来说,都有不同的优缺点,我们需要衡量究竟用哪个算法。那么具体需要权衡哪些呢?首先是它的假设强不强,会有一些很强的假设模型(Assumption model),也有很弱的假设模型。一般来说,越靠上的假设会越强,反之靠下的会更弱,还有模型的可解释性,往往和预测的精确度是相反的。一般来说,预测越精准的模型,模型本身就更难被解释。那么,什么是模型的可解释性呢?也就是说,如果有一个分类算法,区别到底是桌子还是椅子,如果我的算法可以从他的形状、截面、高矮以及其他方面特征对它进行分类,这种情况相对来说是一个可解释性算法。而我们如果把它扔到一个黑箱里面,这个黑箱会自动生成一个结果,这种一般来说是不可解释模型;模型可解释性也是从上往下变得越来越不可解释,而精确度会变得越来越精确。
逻辑回归(Logistic Regression)
我们先来看一个最简单的模型,逻辑回归(Logistic Regression). 虽然叫回归,但其实是一个分类模型,为什么要用这个模型呢?
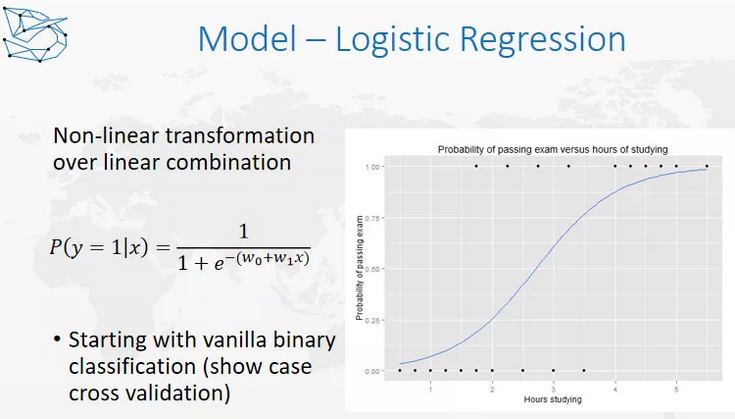
这个问题和之前的线性模型问题有关系,我们为什么能用线性模型呢?因为y轴是一个连续变量,它和x轴是线性关系,我们还要保证残差是符合正态分布的,方差是不变的,x之间不要有任何的贡献性,这个是线性模型的基本的假设。这就是我之前讲的,在做这些假设强的模型时,需要去检查的部分。
对于这种y是0-1分布,显然Y和X之间的关系就不可能是线性关系,因为Y只能取0和1,对于这样的问题应该怎么做呢?去考虑一个新的值,叫Log odds ratio,什么是Log odds ratio呢?我们把最后取值取1的概率叫做P,取值为0的概率是1-p,odds ratio是p/1-p,这个叫赔率,在赌场中会经常听到,比如1赔5,1赔8。

所谓赔率,就是用赢的概率除以输的概率,就是优势率(odds ratio),优势率本身是一个从零到正无穷的值,如果想要达到线性关系,还需要再做一步转换,这时候y才会符合正态分布,虽然逻辑回归是一个分类模型,但在实际的使用中,它是一个线性模型或者说广义的线性模型,这就是原因所在了。
决策树(Decision Tree)
我们在做决策树(Decision Tree)的时候和平时做决策是一个非常相似的过程,如果训练完模型,想知道一个汽车的行驶里程,首先需要知道这个车有多重,一般来说车越重,就越费油。如果这辆车不重,但马力大的话,就会比较费油。如果车本身很轻,马力也小,这辆车就不会费油。决策树(Decision Tree)在做出决策时和人类的思考方式是非常接近的。
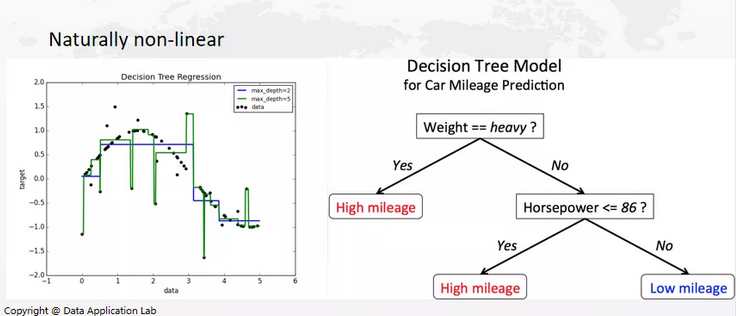
那么下一步是,如何构建决策树?决策树中最重要的是什么呢?作为分类算法,我们希望决策树的叶节点是越纯越好,还是越杂越好?我们可以想一些极端情况,如果叶节点是50%的情况,对于我们来说,这其实是不是一种特别不好的情况。在这种情况下,我们最难做出判断,所以这个时候是最混乱的。那什么时候最容易做出判断呢?叶节点全部属于一类,那我们就可以直接猜这一类,这就是叶节点纯的地方。所以,从我们的直觉出发,我们希望决策树不断分类,从而出现非常纯的叶节点。这也是我们希望看到的现象。

那怎样才能保证叶节点越来越纯呢?这里就需要引入一些优化指标(Optimization Metrics)。我们经常使用Gini inpurity和Information gain这两个指标。两者表述形式非常类似,差别就是一个有log,一个没有log。

以Gini impurity为例,我们可以来算一下,如果我们只考虑两个分类的情况(即只有0和1的情况),当P=0.5,结果为0.25,是最大值;而当P=0/1时,结果为0,是最小值。所以我们希望Gini impurity的值越小越好。

而Information gain借用了信息熵的概念。信息熵是什么呢?信息熵其实是借用了一个物理热力学定义,即混乱度。熵越大,就表示模型本身越混乱;熵越小,表示模型本身越纯。信息熵也是借用了这样一个概念。叶节点越混乱,信息熵越大;叶节点越纯,信息熵越小。
那么信息熵到底是什么呢?我们用新的叶节点的纯度减去旧叶节点信息熵纯度,如果纯度有所增加,表明信息也有所增加,这就是information gain的概念。那么我们什么时候做分组呢?我们需要找到information gain或Gini impurity最大的情况(具体取决于你使用的优化方法)。以上就是决策树中基本的分类概念。
那么,我们什么时候停止?这一点非常重要。当我们希望叶节点越纯越好,或者我们无法增加纯度时,其实就代表模型运营良好。但是决策树本身存在什么问题呢?——决策树非常容易过度拟合。

过度拟合,即拟合过多干扰信息。例如,我们想区分样本中的桌子和椅子,但是由于过分类过多,这有些样本恰好和桌子、椅子本身没有关系。如果这个样本中很多桌子都是黑色的,而椅子大多都是白色的,这时,我们很有可能将颜色作为一个分类特征,这就会导致该模型在训练集中运行良好,但在普通的样本中,颜色本身就成为了干扰信息。所以,一般情况下,我们希望不要包含太多干扰信息。因为过多的干扰信息会导致速度变慢,准确度也会下降。
怎样评估分类模型?为什么要评估模型呢?原因有很多。首先,我们需要选出最佳模型。训练模型的方法有很多,包括逻辑回归(Logistic Regression)、决策树、深度学习等。那怎样才能知道哪个模型的性能最佳呢?这时就需要我们做跨模型评估。即使是同样的模型,我们也需要知道哪个超参数更好,以及决策树中的切入标准是怎样的。
如果是通过逻辑回归训练模型,我们是在P>0.5的时候,预测结果为1还是P>0.6的时候预测结果为1?这些都是决策树中的切入标准。那么,如何评估模型呢?在现有数据集中,首先将决策树分为三部分——训练数据集,验证数据集以及测试数据集,占比分别为8:1:1(该比例可以动态调整,但training data set的占比越高,评估的效果也就越好)。验证数据集(Validation data set)用于发现最佳模型,以及如何选择该模型的超参数。测试数据集(Test data set)用于衡量分类是否正确。以上就是常用的评估方法。

衡量分类的分数也有很多(Score),例如ROC、AUC、F1 score、prececion-recall loss等。具体参考上面表格。

对于二进制结果来说,评估如下:
如果把横轴视为真值——分为positive以及negative,纵轴视为预测值——分为positive以及negative,那么我们一般将左上角和右下角视为真值,及预测值为positive,结果也是positive,即True Positive,这也是我们希望看到的结果。右下角是我们预测为negative,结果也是negative,即True Negative,这也是我们希望看到的结果。而对于右上角和左下角,是我们不希望看到的结果。右上角为结果是negative,但我们预测为positive,即False Positive,一般叫做第Ⅰ类错误(TypeⅠError);而左下角是结果为positive,但我们预测为negative,即False Negative,一般叫做第Ⅱ类错误(TypeⅡError)。这里存在一个问题。对我们来说,究竟是第Ⅰ类错误更严重还是第Ⅱ类错误更致命?
答案是,要结合实际情况判断。我们实际上都能找到特例,第一类错误什么时候更严重呢,我们以法官断案为例,什么是真positive呢?这个人真的做了这件犯罪的事,什么是negative呢?这个人没有做这件犯罪的事,而模型训练出来的positive是指法官认为这个人有罪,negative就是法官认为这个人无罪。那False Positive和False Negative我们可能存在的问题是什么?False Positive是本来没有犯罪但是错误地把他关进了监狱,而False Negative是他本身犯了罪却错误地把他放掉了。对于一个法治社会来说,其实False Positive会更可怕,这样会把无辜的人进行审判,尤其是如果恰好把他判了一个极刑,这个损失是难以估量的,无法把他的生命或者时间挽救回来。而对于False Negative,他既然是一个坏人的话,如果他后面继续犯案,我们还是有机会把他绳之以法,找到更多的证据把他抓进来。
一般对于法庭断案来说,是False Positive比False Negative更严重。那什么时候False Negative更严重呢?我们可以简单用COVID Test,什么是Positive呢?真值Positive是你感染了COVID,而Negative是你没有感染COVID,而模型是检测你是否感染了COVID,False Positive是你本来没有感染COVID,但检测错误地认为你感染了COVID,False Negative是检测错误地认为你没有感染COVID,而实际上你感染了COVID。这种情况下,False Negative会更严重,如果你感染了COVID但是没有检测出来,你可能会出去传染给更多的人。如果是False Positive,你需要隔离一天,第二天重新检测一下,如果连续几天negative,还是会被放出来,这可以减少病毒在社会上的传播。所以这就是为什么会发现新的pass case,比如说Abbott(雅培)新出的BinaxNOW ,15分钟可以出来检测结果,实际上False Positive rate远远高于PCR,这是为了降低False Negative做出来的取舍。
既然讲到这,我们讲一个Business Case——信用卡欺诈的问题,我们来判断用户用信用卡是不是欺诈,这个是False Positive更严重还是False Negative更严重?——这个也是False Negative更严重。再来用同一个想法定义一下Positive和Negative,什么是实际上的positive和negative呢?实际上Positive是你的卡被盗刷了,Negative是你自己的消费,没有被盗刷,模型的Positive是模型认为你的卡被盗刷了,Negative是模型认为你的卡没有被盗刷。False Positive是你的卡没有被盗刷,但是模型认为盗刷了,False Negative是你的卡被盗刷了,但是没有识别出来。False Positive对我们的影响是可能你这笔消费被银行取消了,你需要给银行发个短信或打个电话说这是你的消费,把你的卡解锁,会给你增加一些麻烦。而False Negative对我们的影响是这个消费确实发生了,你、银行、保险公司或商家这四方总有一方会损失掉这笔钱,这是我们不希望看到的,对于信用卡模型来说,也是False Negative比False Positive更严重。
所以,我们一般在做评估的时候不能只看精确度,实际上也要看一下其他的指标,比如recall,它能解决多少False Positive和False Negative。为什么我们不能只看精确度呢?举个例子,如果一个分类模型,它有99%的概率预测都是正确的,那这个模型一定是个好模型吗?这个也是不一定的,比如信用卡欺诈情况,我们知道信用卡欺诈概率较低,应该是一个低于1%的概率,如果我们把所有的消费都认为是negative的话,那你预测准确率也是高于99%的,那这样一个模型是没有用的,因为,我们所需要达到的要求都没有达到,如果我们想要更多的positive,这样会导致 Precision下降,但是对于模型本身来说,我们更在乎False Negative,我们不希望False Negative产生,这种情况下,我们需要更多的减少False Negative,我们不能只看精确度帮助我们做决策。
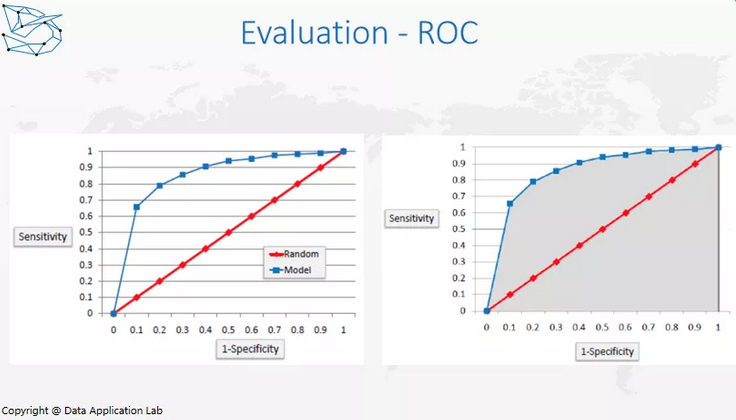
对于分类模型,我们怎么做评估?我们可以用ROC和AUC来帮助我们做判断。如图所示,横向是True Positive Rate,纵向是False Positive Rate。一般,我们会选择不同的值,如果对于每一个不同的False Positive Rate都会有一个True Positive Rate,这样就会在上面做出很多点,把这些点连起来就会得到一个弧线,它覆盖的面积越大,说明模型本身效果越好。模型本身覆盖的面积叫做AUC(Area Under Curve),我们可以这样来评估比较哪个模型的预测效果会更好。ROC和AUC这样的评估方法只适用于binary分类情况。那么, AUC范围是什么?AUC的范围一定是0.5-1,因为random是0.5,你只要比random好,那就大于0.5。如果我们做了一个AUC小于0.5,说明了什么?说明我们把label搞反了,我们把Positive变成了Negative,把Negative变成了Positive,只需要把label换回来,这样就大于0.5了。
接下来,让我们讲讲下列这些应用,以及模型在什么时候用,是怎么用的。

文档分类(Document classification)
它是监督学习还是无监督学习,取决于Document 是否有标签(label)。一般来说,Document 可能是有标签,比如说Google News,我们可以知道这是体育、财经、还是社会方面的新闻,这些已经被作者分类好了,如果有一篇新的News,要怎么把它归到这个类别里呢?实际上我们也可以用分类器分类。我们训练一个机器学习模型,无论模型是怎么样的,我们都需要想四个问题。第一:我们的label是什么,这个案例中,label可以是文档的类别;下一步:特征(feture)是什么,feature 是我们可以用哪些已知信息来帮助我们去预测label;然后,我们要考虑用什么样的模型来拟合数据;最后,我们要想如何评估模型,如果有时间,还可以讨论如何演示这个模型。实际上,一般在数据科学里面有一个非常热门的考法,Machine Learning Design,不论是在Data Scientist面试中,还是在Machine Learning Engineer面试中,都可能会涉及。一般来说,可能会让你设计一个系统,比如我们现在有很多新闻,需要给新闻做一个基于机器学习的文档分类,这个时候你会怎么做。
标签可以是新闻的类别,特征有时间、地域,可能会有一个Word Bag。Word Bag是在某个领域或行业里的专业名词,比如金融行业中的Stock、Risk、Marketing,体育行业中的球员的名称、运动项目、赔率等。所以,我们可以有一个word bag,每一个词的词频是多少,作为一个feature,当然还需要对词牌进行处理,去掉一些虚词(a、the、it、this等)。更好地,我们还可以有一些deep learning的方法,比如Word Embedding。
当然如果更好的话还可以用一些机器学习的办法,比如说Word Embedding可以知道每个Word大概的词义是什么,根据Word Embedding的结果去做feature generation,然后再去训练模型。
下一步是怎么做模型, 我们可以从逻辑回归开始,不断的改善,比如说用一些UNsample model、XGBoost、lightLGB,甚至还可以用一些机器学习的模型,也可以用CNN、RNN,最近还有一些新的Google的forward learning model都是可以用的。
最后,我们要怎么测试呢,可以用Hold-Out Group去测试性能,再想怎么去做生产,这涉及到考虑模型的等待时长、刷新时间、标签需要多长时间进行改变,这些都是真正投入生产时,需要考虑的问题,是一般的机器学习设计题目的基本论法。当然,这里每一个问题都没有讲的很细,如果要详细讨论的话,需要讨论每一个想法,如特征是怎么提取的,需要怎样的算法,优化的目标是什么,怎么提高结果,模型之间的权衡是什么,如果有这样的权衡怎么去选择这些模型,投入使用之后还有什么需要考虑的,刷新时间、甚至涉及到一些系统设计用什么样的框架去部署,究竟是用一个状态模型,还是两个状态模型,用线下 还是 线上训练,这些实际上都是需要考察的。
另外,classification还有以下这些用处:
广告点击率预测(Ad click-through rate prediction)是广告行业非常重要的一个部分,因为广告行业最关注就是互动,这也取决于是什么样的广告,一般来说,广告有几种商业模式,最简单一种就是pay-per-click,像Google、Twitter上这种广告,如果不点击广告商是不会对这些展示收费的,只有点击了才会收费。所以对于平台来说,是需要充分利用点击率,把高点击率的放上面,把低点击率的放下面,以此来吸引用户,这样才能收入最大化。当然,最后的收入和等级不仅仅是通过点击率来算的,但是点击率是重要的预测方法。如果我们预测出来点击率就可以把结果拿点击率从高到底排列,现在的规则一般是根据第二高的排名去收费,这个就可以说是简单的广告点击率预测。
一般来说,最开始点击率模型都是逻辑回归,那为什么这样一个复杂的东西要用逻辑回归去做呢?这个里面主要是等待时间的考虑,而且这个需要在线学习,因为广告商的广告每天可能会在不同的时间上线,要不断的抓取趋势,所以模型要随时更新。如果我们训练过于复杂的模型可能就会导致等待时间得不到保证。当然,在实际操作中也会有神经网络,因为回归是被很多东西限制住的,所以一些新的神经网络甚至一些快速机器学习的办法也在逐渐的被采纳到广告领域,所以广告这个领域实际上也是分类算法用的非常多的一个领域。
产品分类(Product categorization)
和文档的原则类似,只不过是从文档变成了产品,比如,对于Amazon来说,它是属于运动、还是属于衣着,这个就是产品分类。
恶意软件分类(Malware classification)
Malware指的是一些网络进攻、木马、病毒这些恶意软件,这些是我们不想看到的,而他们的行为和正常的访问是有很大的区别的,我们可以通过训练数据集来找到并且成功的拦截那些恶意软件。
图像情感分析(Image sentiment analysis )
这个分析主要是看图像里面到底有哪些内容,也是,目前非常热门的话题,比如,可以通过机器学习的算法得知这个里面到底是有一只狗还是一只猫,甚至我们可以知道这个里面有哪些名人,他们的表情是什么,他们在干什么,这些都是现在深度学习算法在研究的一个方向。
客户流失预测(Customer churn prediction)
这是一个很热门的方向,尤其在一些和分析、客户相关的领域很受欢迎,流失(Churn)就是客户离开我们的平台,我们需要预测哪些客户更可能不使用我们的产品,我们在他离开之前对他进行一些engagement来防止他流失,比如给他发一些优惠券、延长一些使用时间、发一些邮件等。
促销优惠的顾客行为评估(Customer behavior assessment for promotional offers)
比如要发推广折扣,要找到哪些人值得发。我们需要这些人不只在有折扣时才会购买,而且是给他发了折扣之后,他们也会持续的去用,这种客户往往是最优的客户。
推理验证分类(Deduction validation classification)
是我们在减掉一些产品的时候,去验证减掉的这一部分是不是正确的。
信誉评估(Credit-worthiness assessment)
这个更多的是我们要不要给某个人批准信用卡,这个是信用卡批卡过程的评估,这里面有可能会跟信用分数,信用记录,银行的忠诚度,还有一些其他信息,包括职业、收入都是息息相关的。
拦截订单释放建议(Blocked Order Release Recommendation)
这里是指,有一些订单被拦截了,我们要释放哪些被拦截的订单,这些也是一个分类的算法。

最后给大家推荐一些有趣的书,包括:
– Machine Learning(周志华)
– Pattern Recognition and Machine Learning (Christopher M. Bishop)
– 统计学习方法(李航)
– The Elements of Statistical Learning.
这些书对于机器学习算法的学习会很有帮助,感兴趣的同学可以找到这些书籍,深入了解。
以上就是本文的全部内容,感谢大家的阅读~!你还可以订阅我们的YouTube频道,观看大量数据科学相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
Recap 作者:数据应用学院
美工编辑:过儿
校对审稿:佟佟
公开课回放链接:https://www.youtube.com/watch?v=fNa_EK2InDQ&t=159s





