
50⾏python爬⾍代码, 带你正确打开知乎新世界!
拥有了爬虫技能,你就拥有了全世界。
1. ⾸先,你要在电脑⾥安装 python 的环境,我会提供2.7和3.6两个版本的代码,
但是本⽂只以python3.6版本为例。
我建议不管是Win还是Mac⽤户,都最好下载⼀个 anaconda,⽤于管理python库和环境。
-
(Anaconda下载链接)www.continuum.io/downloads
-
(用户手册)conda.io/docs/test-drive.html#managingconda
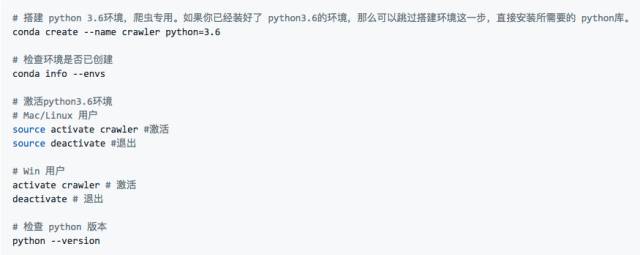
安装完成后,打开你电脑的终端(Terminal)执⾏以下命令:
2. 因为知乎⽹站前端是⽤ react 搭建的,页⾯内容随着⽤户⿏标滚轴滑动、点击
依次展现,为了获取海量的图⽚内容,我们需要⽤selenium这个 lib 模拟⽤户对浏览
器进⾏滑动点击等操作。
- https://pypi.python.org/pypi/selenium
# 利⽤ pip 安装 selenium
pip install -U selenium下载安装完成后,我建议⼤家打开上⾯的链接,阅读⼀下 selenium 的使⽤⽅法。意思⼤致为,为了运⾏ selenium,我们需要安装⼀个 chrome 的 driver,下载完成后,对于 Mac ⽤户,直接把它复制到/usr/bin或者/usr/local/bin,当然你也可以⾃定义并添加路径。对于 Win ⽤户,也是同理。
-
Chrome: https://sites.google.com/a/chromium.org/chromedriver/downloads
-
Firefox: https://github.com/mozilla/geckodriver/releases
-
Safari: https://webkit.org/blog/6900/webdriver-support-in-safari-10/
3. 在爬⾍的时候我们经常会发现⽹页都是经过压缩去掉缩进和空格的,页⾯结构会很不清晰,这时候我们就需要⽤ BeautifulSoup 这个 lib 来进⾏html ⽂件结构化。
pip install beautifulsoup4代码解释

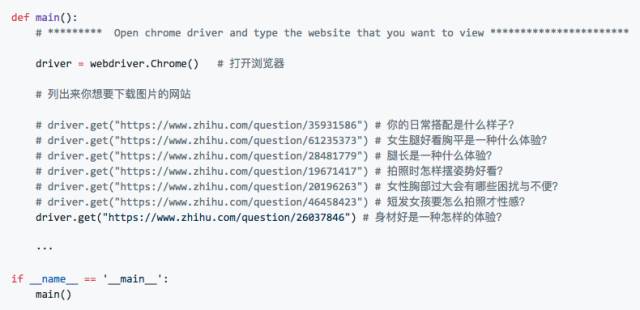
2.1 确定目标URL
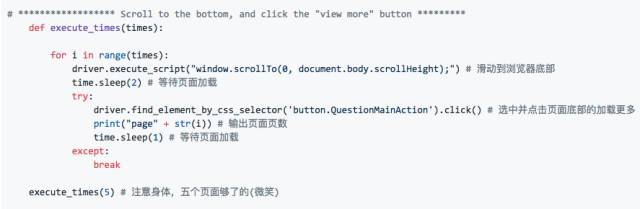
2.2 模拟滚动点击操作
在 main 函数⾥我们定义⼀个重复执⾏的函数,来进⾏滚动和点击的操作。⾸先我们可以⽤driver.execute_scrip来进⾏滚动操作。通过观察,我们发现知乎问题底部有⼀个“查看更多回答的”的按钮,如下图。因此我们可以⽤driver.find_element_by_css_selector来选中这个按钮,并点击。为了爱护⼩朋友们的⾝体,我们这⾥只爬取五个页⾯的图⽚。其实,五个页⾯,100个回答,往往都能有1000张图⽚了。。。
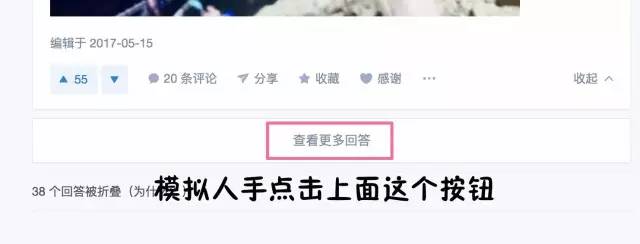
仔细看下图高亮处:

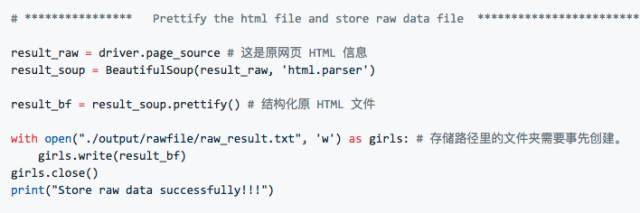
2.3 结构化HTML页面并保存
我们每次爬取页⾯信息,要做的第⼀件事就是把页⾯ HTML 存储下来。为了⽅便我们⾁眼浏览,这时候就需要⽤beautifulSoup把压缩后的 HTML ⽂件结构化并保存。
2.4 爬取知乎问题回答里的<img> nodes
要知道,在我们每次想要爬取页⾯信息之前,要做的第⼀件事就是观察,观察这个页⾯的结构,量⾝⽽裁。⼀般每个页⾯⾥都有很多个图⽚,⽐如在这个知乎页⾯⾥,有很多⽤户头像以及插⼊的图⽚。但是我们这⾥不想要⽤户头像,我们只想要要回答问题⾥的照⽚,所以不能够直接爬取所有 <\img> 的照⽚。通过观察,我发现每⼀个图⽚附近都会有⼀个<noscript>的node,⾥边不仅有缩略图 URL 还有⾼清原图的 URL。因此,我为了偷懒,就直接把所有<noscript>给爬了下来。仔细观察,你会发现每个<noscript>的<>都是被 escape(HTML entity 转码)了的,所以要⽤html.parser.unescape进⾏解码。


转码后,结果如下(琳琅满目的高清无码大图URL):

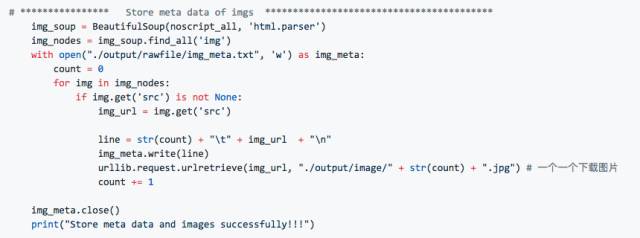
2.5 下载图片
有了 img 的所有 node,下载图⽚就轻松多了。⽤⼀个 urllib.request.urlretrieve就全部搞定。这⾥我又做了⼀点清理,把所有的 url 单独存了⼀下,并⽤序号标记,你也可以不要这⼀步直接下载。
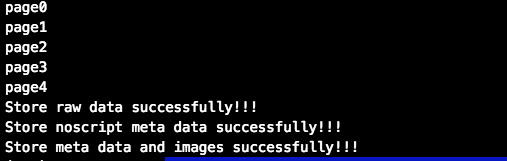
2.6 您好,您的小H图大礼包已送达!
成功后,你会看到以下消息。然后你就可以孤身一人躲在被窝里嘿嘿嘿了。。。
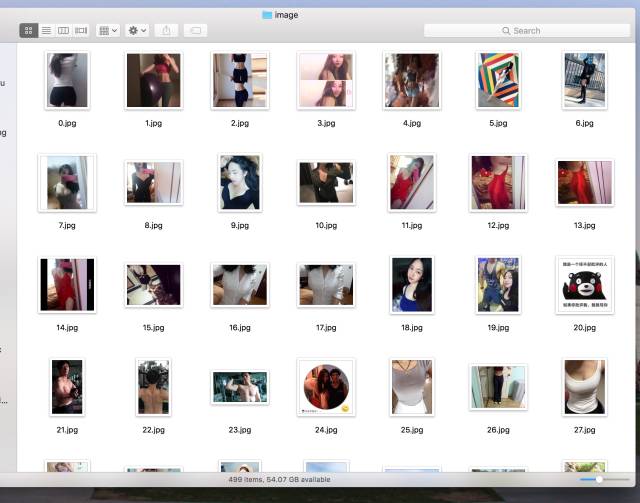
因为考虑到肖像问题,只展示图库的冰山一小角(不露脸的),随便给吃瓜群众们展示一下:












