
理论上说,什么是数据工程师,什么是数据科学家
Data Engineer vs. Data Scientist

这么多公司需要大数据人才,小伙伴们也纷纷跃跃欲试投身这场数据革命中。可到底大数据有哪些岗位需求呢?对用人的要求是怎样的呢?我们今天来仔细看一看。
数据行业里面,跟数据有关的岗位一般有三种:1. Data Analysis, 2. Data Engineer, 3. Data Scientist.
Data Analysis
Data Analysis是比较entry level的数据分析师,也指传统的数据分析岗位,用用regression model,做做回归分析,或者拿Excel处理一下几页的数据,出一张QQplot的图,甚至就算用的是Tableau画出很高大上的效果图,其实岗位也还是Data Analysis。这种岗位的需求存量较大,但不是本文的重点。
本文重点介绍后两种,Data Engineer 和Data Scientist。
Data Engineer
Data Engineer主要职责是经营,维护数据仓库。在岗位上做的很多是“我吃的是草,挤出来的是奶”的活儿。对,就是数据的ETL (Extraction, transform, Load),将所需的数据从不同来源不同格式的数据源中提取出来,转换类型以方便使用,然后归档入数据仓库。传统的Data Engineer使用很多SQL的工具,包括MySQL,Oracle SQL等来协助完成这项任务。一般来说,Data Engineer需要有一定的CS背景,需要能够编程,而且指不定什么时候服务器又down了,你还得会修。现在不会?学嘛~。

However, 在“大数据”时代,面对动辄每天几百G的数据规模,仅仅掌握传统的数据工具,最终结果只能是“臣妾不能够”。于是越来越多的Data Engineer需要掌握新的技能,利用分布式的系统来完成对数据的ETL。 现在用得最广泛的就是Hadoop和Spark。分布式架构的Hadoop生态系统包含很多组件和应用工具,分布式文件系统HDFS,分布式SQL工具Hive,流处理工具Storm,消息分发工具Kafka,系统资源管理工具Yarn等。Data Engineer们需要利用这些工具配合程序开发来完成数据处理的工作。

有了可用的高质量的数据,那么Data Scientist就可以出场了。
Data Scientist
Data Scientist在公司里面的责任,是从数据中挖掘价值,为公司的商业决策提供依据,职位比Data Analysis高,薪水当然也很可观,年薪12万刀以上妥妥的。

当然,由于现在人才市场短缺以及大数据也刚刚兴起,很多公司可能连ETL这部分东西都要让Data Scientist去干,充分展示出资本主义国家对劳动人民的无情压榨。
需要强调的有两点:
首先,Data Scientist的未来,应该是闪耀于各行各业之中,甚至IBM提出了CDO这样一个“首席数据官”的概念。数据科学家并不是一种新兴的独立的行业,而是强调利用各种工具在现有行业的数据中去挖掘价值,让数据来引导决策。会使用各种machine learning的models,像Random Forest,Support Vector Machine等,还不够,一定要结合到相关行业的数据中去,才能发挥其价值。

其次,Data Scientist应该怎么看待相关性和因果性(correlation and causality)。现在很多人,包括畅销书《大数据时代 生活、工作与思维的大变革》作者维克多等人,都在呼吁放下因果性,让相关性来指引数据结果。然而也有一些人对此表示严重的忧虑,包括Support Vector Machine的发明者Viladimir Vapnik,他在最近的一次演讲中,将深度学习成为‘蛮力’,并警告‘魔鬼往往出自于蛮力’。
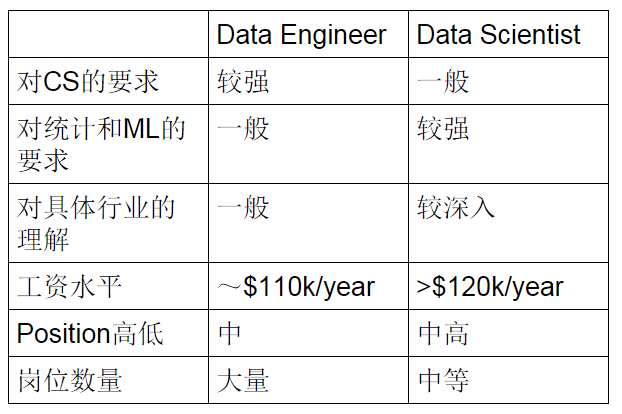
虽然这两种岗位对人才的要求不尽相同,但从上面的介绍中你一定会发现,如果有相关的工作实习,或者项目经验,那么你会变得非常抢手。这就是现在大数据就业市场的特点。





