
将深度学习应用于国际象棋
关于英文原文作者:埃里克·贝恩哈兹森(Erik Bernhardsson)——纽约一家金融科技创业公司创始人。Better Mortgage首席工程师。前Spotify主管工程师。拥有自己的专属网站,喜欢撰写博客文章。
应用深度学习于… 国际象棋
我有意向学习 Theano* 有一段时间了,同时我又想设计一个可用于下国际象棋的人工智能。所以,为什么不将他俩个合并起来呢?这就是我的想法并在此上花了大量的时间。
(*Theano是Python语言中的Library之一。用来定义、优化、高效评估包含多维阵列(Array)数学公式)
理论依据?
象棋是一种只存在有限状态数量的游戏,这意味着只要你有无限的计算能力,你就可以找到玩国际象棋的最佳策略。游戏局面要么是白方胜,要么是黑方胜,或者是双方的平局。我们可以通过函数 f(position) 来描述。如果,我们有一台计算无限快的计算机,我们可以通过以下步骤来计算:
1. 给所有最终的局面赋值-1,0,1
2. 依据递归规则
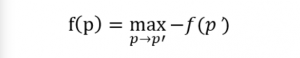
在这里 p → p′ 表示 p 开始的合法走子。这里做减法是因为玩家在交替走子,如果在 p 步是白方走子,那么在 p′ 则是黑方走子,反之亦然。这和决策论中的极小化极大算法相同。 游戏中有大约 10^43 种局面,所以要计算是不太可能的。我们需要求助于 f(p) 的近似。
应用机器学习的意义何在?
机器学习真正解决的是简化近似数据。假设我们得到了大量的数据来 学习,我们可以通过学习的得到 f(p)。一旦我们得到模型,目标,和训练数 据,我们就可以解决问题了。 我从免费互联网国际象棋游戏数据库 (FICS Games Database)下载了 100M 大小的游戏,然后开始训练机器学习模型。我的函数 f(p) 是从一下两个原则中从数据中学习得到的:
1. 玩家将会选择最优或者近似最优走子。这意味着在接下来的 p → q 的 两步中,我们将会得到 f(p) = −f(q)
2. 基于以上原因,从 q 出发,但当到达随机位置 p → r,我们必将得到 f(r) > f(q),因为随机位置对对手而言是更佳的。
模型
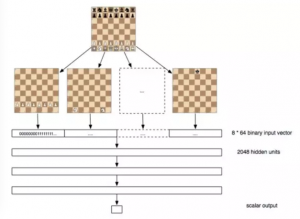
我们构造了一个 f(p) 模型,使用了三层、2048 单元的人工神经网络, 并在每层用线性整流函数修正。输入层是 8 ∗ 8 ∗ 12 = 768, 这里的每一个点 (总共有 12 种)出现在棋盘的每一个方格中(总共有 8 x 8 个方格)。在三轮矩阵乘积之后,将最后的点乘积与一个 2048 大小的向量相乘得到一个数值。
总共有大约 10M 左右的未知参数在这个网络中。为了训练网络,我提 供了一个参数组 (p, q, r)。并将其不断训练。其中 S(x) = 1/(1/exp(−x)) 是 sigmoid 函数,总体目标为:
这是一个“宽松”不等式 f(r) > f(q),f(r) > −f(q) 以及 f(r) < −f(q) 的对数概率。最后两项仅仅是表达了“宽松”等式 f(q) = −f(q)。我也使用了 κ 来使不等式成立。我将其设为 10.0。我认为所得结果对 κ不太敏感。
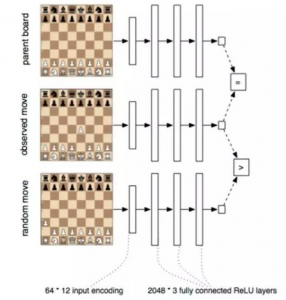
注意这里的学习函数并不了解象棋规则。我们甚至不告诉他每一步是 怎么移动的。我们保证每一步都是正确的移动,但是我们并不对游戏规则本 身解释。模型通过对大量的象棋游戏的观测值进行学习。
注意这里我们也不尝试去从胜利的一方进行学习。原因是训练数据是来源于大量的业余玩家中得到的。如果一个专业玩家来参与其中,那么他的结果很有可能会相反。也就是说最终的得分是一个弱标签。而且,业余玩家很可能在大部分时 间进行近似最优解。
模型训练
我从亚马逊网络服务系统(AWS)租了一个图形处理器(GPU)来训练 100M 大小的游戏,并用引入 Nesterov 动量的随机梯度下降法计算了 4 天。我将所有的参数组 (p, q, r) 放入一个 HDF5 数据文件。开始我对学习速率忙了一阵子,但当我意识到我 仅仅是要在几天之内得到结果。我开始使用一个非正统学习速率:0.03 ∗ exp(−timeindays)。因为我有太多的训练数据,所以正则化是没必要的,我 就没有使用 dropout 或者 L2 正则化。这里我用的一个技巧是将棋盘解码为 64 个字节然后再将棋盘转化为一个 768 位的浮点型向量。因为简化了 I/O, 极大的提高了运行效率。
象棋人工智能如何运作?
人工智能每次都用 f(p) 函数来近似这一步的值,这被称作为评估函数。这个函数和将决策树的深度搜索结合。结果证明 f(p) 仅仅是把棋下好的一小部分。所有的人工智能都要专注于最佳搜索算法,但是每一步随着决策树的伸展呈 指数增长,所以实际上你只能往决策树下5-10步就会停止。你使用的只是一些叶节点的近似估计然后在使用大量的负极大算法来聘雇决策树。通过运用一些智能搜索算法,我们可以得到相对表现较好的 p 结果。人工智能都从一些简单的评估函数开始:卒是一分,马是三分等等。我们将学习得到的每一个函数评价决策树中的所有叶节点。然后尝试往深度搜索。这样我们可以先从数据中得到 f(p),然后我们再插入搜索算法。
能运行吗?
我创造了我的象棋 人工智能 Deep Pink 作为对深蓝的致敬。事实证明,我们学习得到函数绝对可以下棋。它打败了我,每次。但我是一个可怕的棋手。
Deep Pink 能打败现有的象棋 人工智能 吗?有时候能。
我把它和另一个象棋引擎对弈——Thomas Dybahl Ahle 的 Sunfish。Sunfish 完全由 python 写成的。我选择用相同语言编写的引擎的原因是,我不想让这场对弈成为一个无休止的快棋练习。Deep Pink 很大程度上还依赖于快速走子,我不想花几个星期来处理极端情况和 C++ 中的位图,从而去与最先进的引擎竞争。那样一来只会变成军备竞赛。所以为了能够建立一些有用的东西,我选择了一个纯 python引擎。
事后诸葛亮地讲,有一件事是显而易见的:精确性不是你想从 f(p) 评估函数中得到的主要内容,而是单位时间中的准确性。无关紧要的是,如果运算速度慢十倍可以使一个评估函数结果比另一个稍微占优,因为你可以采取高速的评估函数(但是略差的结果),并且在决策树中获取更多的节点。所以,将引擎花费的时间考虑进来。话不多说,这里是引擎对弈的结果:
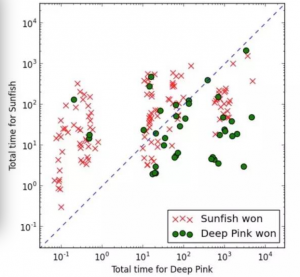
注意到这时一个 log 坐标系统。x 轴和 y 轴并不是很关联,要注意到的都是到对角线的距离,因为这告诉我们引擎画的超过 CPU 的时间。每一局我都将随机化参数:Deep Pink的最大深度,和 Sunfish 的最大节点数。
不出所料,任何一方的时间优势越多,它发挥的越好。总体来说,Sunfish 是更好的,赢得了大多数的游戏,但 Deep Pink 赢得大约 1/3 的游戏。我实际上很受鼓舞。我认为通过一些优化,Deep Pink 实际上可以发挥更好:
• 更好的搜索算法。我现在正在使用带 α 和 β 剪枝的负极大算法(Negamax),相比Sunfish用的是MTD-f算法。(Memory enhanced Test Driver,即记忆增强测试驱动)
• 更好的评估函数。Deep Pink 的表现将会更加激进,但会犯很多愚蠢的错误。 通过生成“更难的”训练样本(理想情况下从错误中获得),它应该生成一个更好的模型
• 更快的评估函数:它可能训练出一个规模更小(或许更深入)版本的相同神经网络。
• 更快的评估函数:我没有使用 GPU 来进行对弈,仅仅是用来训练
总结
受到以上结果的鼓舞,有两个结论使我感到很有意义:
1. 从没有预处理的原数据中直接得到评估函数是可能的
2. 一个相当慢的评估函数如果更加准确,同样可以在对弈中表现出色
我很好奇这种算法能否在其他游戏中表现相当。无论如何,结论告诉我们很多值得注意的地方。其中最大的就是我还没有挑战一个真正的国际象棋引擎。我不知道我是否有时间在象棋引擎上继续发展,但是如果任何人有兴趣的话我的源代码在Github 上。(链接:erikbern/deep-pink)





