
质问灵魂:为什么别的小朋友,都有三页纸的工作项目经验可以写成简历?
昨天的文章中,点这里看昨天的文章,我们学会了如何获取和清洗数据,并通过数据来获取一些基本的信息。那么今天,我们就要直接进入机器学习了吗?作为一个谨慎的人,我必须说,在获取数据之后,机器学习之前,我们还有很多事情要做。
下篇知识点
• 注意并检查机器学习的常见错误
• 根据特征重要程度找出租金的主要影响因素
• 建立机器学习模型
Common mistakes
When carrying out machine learning and data science
我们需要将每个变量都可视化来观察它们的分布,找到极端值,并了解这些极端值出现的原因。
如果有某些特性的数据缺失怎么办?怎样把类属特征(categorical features) 转化成数值特征?这些问题层出不穷,下面我总结了 6 个容易出现的问题:
01 Visualization
可视化的方式有很多,比如 box plots,histograms,cumulative distribution functions,以及 violin plots。我们需要选择能给出最多数据信息的视图。Histograms 能很快帮助我们辨别分布,而 box plots更高级,能帮我们找出极端值和中间值。我经常看 Python’s seaborn gallery 和 Kaggle kernel 来观察哪种视图会包含更多的数据信息。
从这些图里,我们要问的问题是:这是我们预期的吗?然后我们会发现insights 或者 bugs。租房价格图我画的是柱状图,我的预期是右侧会有一个很长的尾巴,并且尾巴的面积逐渐减小甚至消失。如下图👇
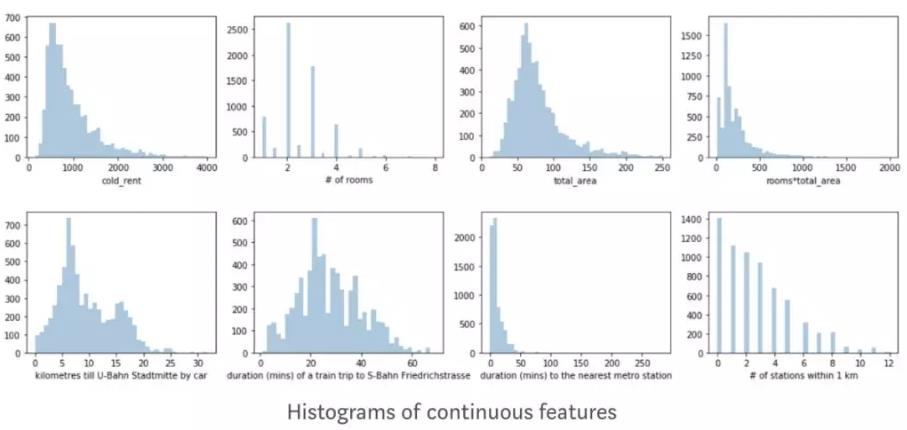
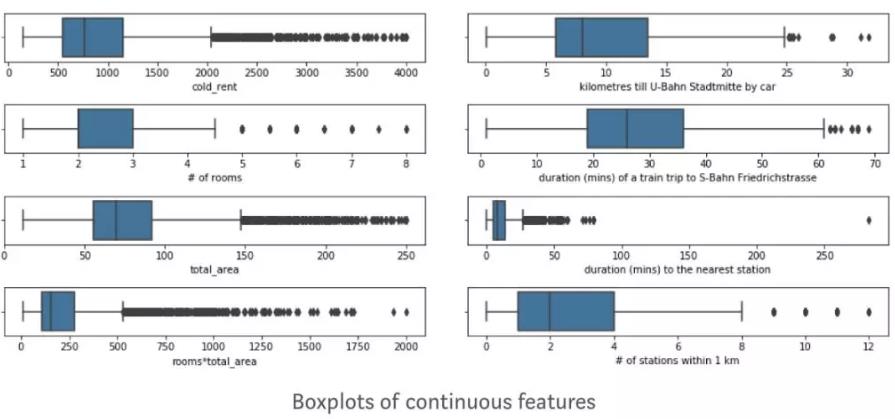
Box plots 帮助我发现了极端值。大部分公寓的极端值出现在 200 平以上的画室或者租金极低的学生公寓。
02 Impute values based on the whole dataset?
有很多原因都会导致数据缺失,如果我们删掉每一个有特征缺失的数据,我们最后拿到的数据集可能非常小。归责统计的方法很多,但我们需要注意的是,仅使用training data 进行归责统计,避免 test set 的数据泄漏。在租金数据中,我同时抽取了公寓描述。当某些特征数值缺失时,我会从描述中寻找这些数值。
03 How do I transform categorical variables?
很多算法都不能直接运用到类属特征上,因此我们需要将这些类属特征转化成数值。我们使用的方法有 Label Encoder,One Hot Encoding,bin encoding,和 hashing encoding 等。 需要注意的是,很多人在应该用 Hot Encoding 的情况下使用了 Label Encoding。
比如在我们的租金数据中,公寓类型征包含了[ground floor, loft, maisonette, loft, loft, ground floor] 这些类属特征。LabelEncoder 将这些类属特征转化成 [3,2,1,2,2,1],表示 ground_floor>loft>maisonette。对于 decision trees 这样的算法来说,这种转化是可行的,但对于回归算法和 SVM 来说,这种转化可能就没有意义了。
在我们的租金数据中,我将房子的 condition 进行了以下数值转化:

04 Do I need to standardize variables?
标准化可以使数据处于同一范围,意思是如果有一个变量的范围是 1k 到 1m,另一个是 0.1 到 1,在标准化之后它们可能变成同一范围。L1 或 L2 正则化是减少过度拟合的常见方法。但是在执行 L1或 L2 之前要将特征标准化。比如租金是 Euros 时的系数就比租金是美分时的系数可能要大100倍。L1 和 L2 会对较大的系数比较不利。另一个标准化的理由就是,你的算法使用了梯度下降。梯度下降在特征范围后收敛更快。
05 Derive logarithm of the target variable?
这个问题没有普遍适用的答案,因为它的回答取决于很多因素,比如,你想要相对误差还是绝对误差,还有你使用的算法等。
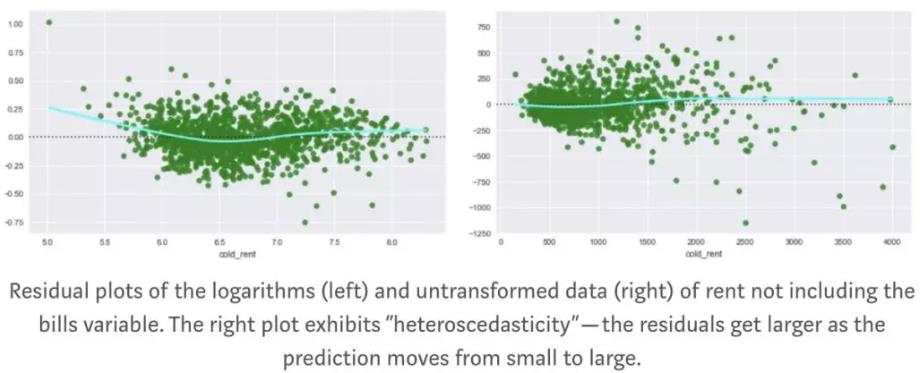
在回归模型中,首先注意剩余图和度量标准。有时候将目标变量对数化可能会是会得到一个更好的模型,并且使它的结果简单明了。当然也有一些其他的转换很有用,比如开根号。Stack Overflow 上有很多关于这个问题的答案。
在我的租金数据里,我对数化了租房价格,并用剩余图表示。
06 Some more important stuff
有些算法,比如回归,可能会因为系数不稳定而出现共线性 (collinearity) 的问题。根据内核的选择,SVM也可能出现共线性的问题。
决策为核心的算法可能不会出现多重共线性的问题,因为它们可以在不同的树之间交换特征。然而,对于特征重要性的解释就会变得更难,因为在这种情况下,相关变量可能会显得不那么重要。是不是很复杂?
Machine Learning
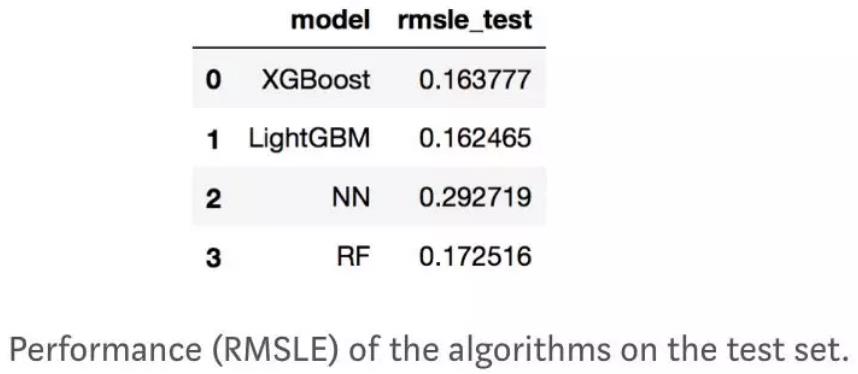
当我们对数据足够熟悉,并且清洗了极端值之后,就要开始进行机器学习了。我想初步探索三个算法,对比它们的表现和速度。这三个算法分别是不同实现下的梯度提升树,XGBoost and LightGMB, Randon Forest (FR, scikit-learn) 以及 3-layer Neuronal Networsk (NN, Tensorflow). 我选择了 RMSLE (root mean squared logarithm error) 作为优化时度量标准,因为我对数化了我的目标变量。
XGBoost and LightGBM 表现得差不多,RF 稍差一些,NN 最差。
Feature importance:
Finding the drivers of the rental price
决策树算法能够很好的解释特征,比如它们能够计算出一个特征重要性的分数。在建立了一个决策树模型以后,我们可以观察哪些特征更能做出好的预测。Feature importance 提供了一个分数来描述每个特征的对与决策的影响程度。这个分数有很多中计算方式,其中一种就是计算这个特征在整个树中分离数据时被使用了多少次。
从 Feature importance 可以看出影响租房价格的主要因素。在租金预测中,我们发现房子的整体面积时影响租金的主要因素,这也符合常理。有些通过外部界面分析的特征,比如到达地铁站的时长,也是主要因素。租金的分析如下图。
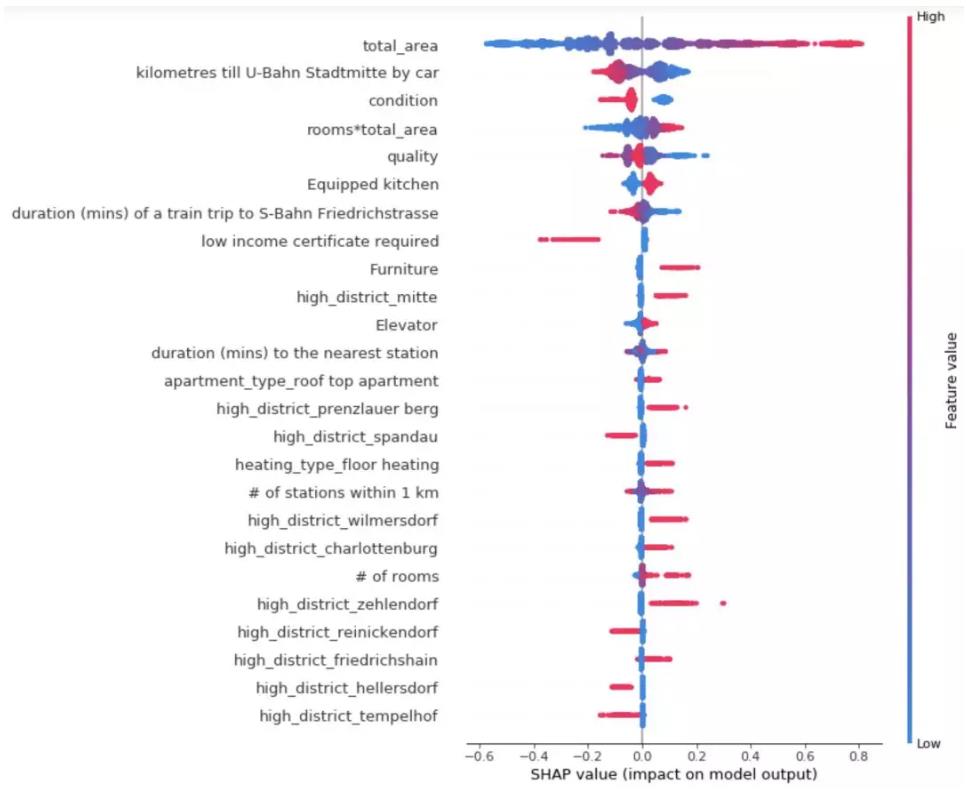
我们可以从这张图👆中获取很多有效信息:
- 到城市中心的距离越近,公寓租金越高。
- 房子的面积是影响租金的最主要因素。
- 如果房东要求租客有低保证明,这种房子的租金一般会很低
- Mitte, Prenzlauer Berg, Wilmersdorf, Charlottenburg, Zehlendorf 和 Friedrichshain 的租金最贵。
- Spandau, Tempelhof, Wedding 和 Reinichendorf 的租金最便宜。
- 房子现状越好,室内有厨房和电梯的会更贵
需要注意的是,数据都是2018年初的,每个地区的租金可能会发生一些变化。另外,我发现,到地铁站的时间和1km内地铁站数量这两个因素非常矛盾。在郊外的富人区,可能会发现到地铁站的时间越长,租金越贵。到地铁站的时长可能使房价下降,因为地铁站附近的噪音和振动非常扰民,同时也可能时房价上涨,因为它意味着离公共交通更近。我们可以进一步分析这个原因,观察是否离巴士站近也可能导致房租上涨。一千米以内地铁站数量也因为同样的原因可能使房租上涨或下降。
Ensemble averaging
在对比了不同模型的表现以后,我们可以将这些结果做成一个集成。通过不同算法的预测结果最后再计算一个结果,这样能有效方式过度拟合,同时减小差异。我通过RMSLE选出了最优模型。
Stacked models
我们还可以做一个平均集成或加权集成,甚至可以将模型通过不同方式堆栈。基本的原理就是将不同的基础模型构建成一个复合的集成模型来预测最后的结果。但是如何train这个集成模型是不确定的,因为它包含了所有基础模型的偏见。在我的租金模型中,集成模型没有减小RMSLE。
Final Thoughts
• 聆听周围的人在谈论什么,将他们的抱怨作为研究问题的一个切入点
• 让人们自己通过交互式仪表板发现自己需要的信息
• 不要局限于两个变量相乘,试着寻找别的数据来源或解释
• 使用集成模型或堆栈模型来优化模型
• 学习数据应用学院的课程
原文作者:Jekaterina Kokatjuhha
翻译作者:喝豆奶的Narcia
美工编辑:喝豆奶的Narcia
校对审稿:卡里
原文链接:https://medium.freecodecamp.org/how-to-build-a-data-science-project-from-scratch-dc4f096a62a1
点击阅读原文,带你开启你的数据科学生涯!👇阅读原文





