
SQL查询语句应该避免的五个错误
SQL和机器学习有一些相似之处。它们都不需要大量的编程,所以上手比较容易,而且代码也很少会崩溃。
我认为,SQL很难崩溃会让数据分析变得更加困难。比如从数据库中提取数据集,结果却发现了数据错误或缺失数据,这种情况出现的次数有多少呢?答案是:相当多!
但如果SQL在错误时直接崩溃,我反而很容易知道自己犯错了。因为SQL查询一定会返回结果,而这些结果就需要数据科学家花费大量时间进行数据的验证。
所以在编写SQL查询时,以下五种错误是你应该注意的。
01 不清楚SQL执行的顺序
SQL的使用门槛很低。在你编写查询时,如果能用JOIN进行一些分组,很多人都会觉得你已经是专家了。
但是,这些所谓的专家知道SQL查询是按什么顺序执行的吗?
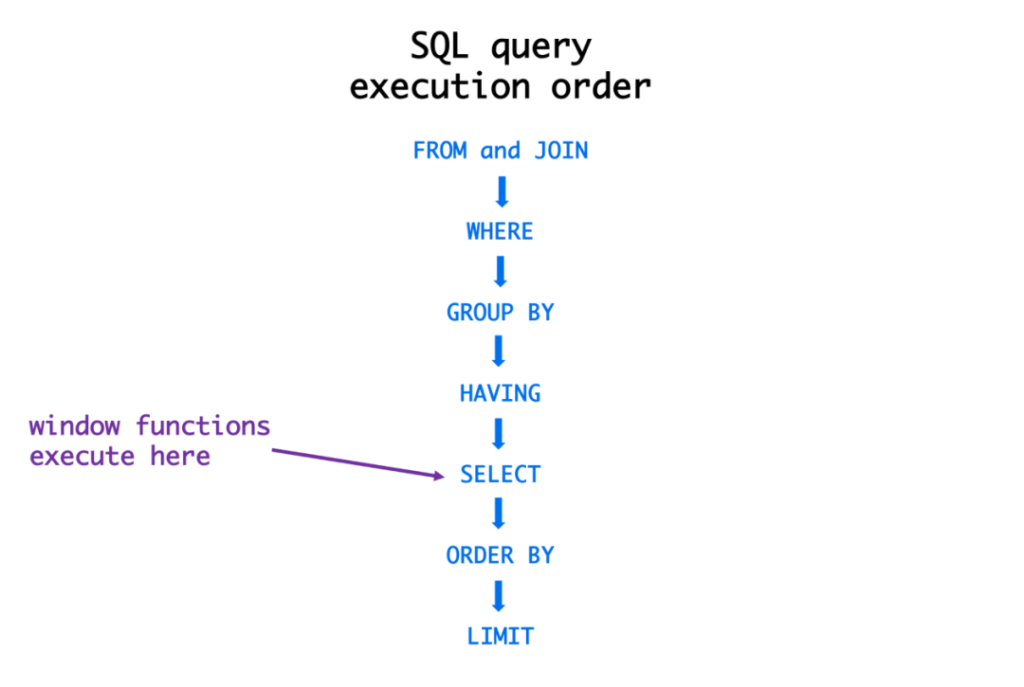
SELECT是在编写时在编辑器中执行的,但数据库并不是这样,所以SQL查询其实并不是从SELECT开始的。
数据库是从FROM和JOIN开始执行查询的。这也就解释了为什么我们可以用WHERE来使用已经JOIN过的表格。
那为什么我们不能过滤掉WHERE中的GROUP BY呢?这是因为,GROUP BY是在WHERE之后执行的,所以我们还需要下一步:HAVING。
最后,运行SELECT。它选择了要包括的列,定义了要计算的聚合函数。另外,Window Functions也在这里执行。
这就是为什么当我们尝试在WHERE中使用Window Function的输出进行过滤时,会出现错误。
请注意,数据库是利用查询优化器(query optimizer)来优化查询执行的。优化器可能会改变某些操作的顺序,让查询运行更快。但这是一些幕后的高级概念。
02 Window Functions的实际功能
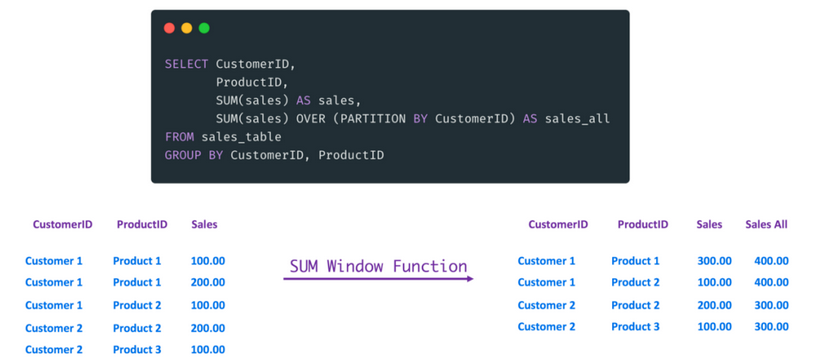
第一次遇到Window Functions时,我觉得很神奇。为什么把Window Functions作为GROUP BY用的时候,可以聚合数据呢?
其实,在设计查询时,Window Function(WF)简化了很多操作:
- WF能访问当前记录前后的记录,具体参见Lead和Lag函数。
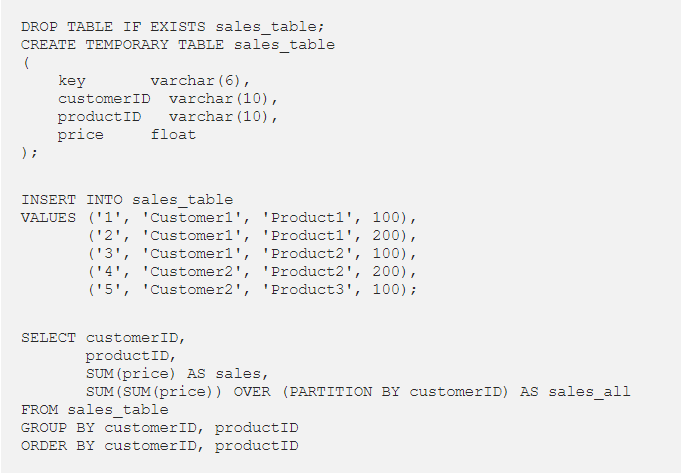
- WF可以用GROUP BY对已经聚合的数据执行额外的聚合。请看上图中的例子,我用了WF计算销售额。
- ROW_NUMBER WF可以列举行(row)。还可以用它来删除重复的记录,或者随机抽取样本。
顾名思义,WF还可以在窗口里计算统计数据:

上述的WF,可以计算第一条记录到当前记录的累计总和。那在这一过程中,我在哪里出错了?
我没有花时间去了解Window Functions的基础知识和功能教程。所以,我的查询过程变得过于复杂,还出现了bug。
运行以上查询:
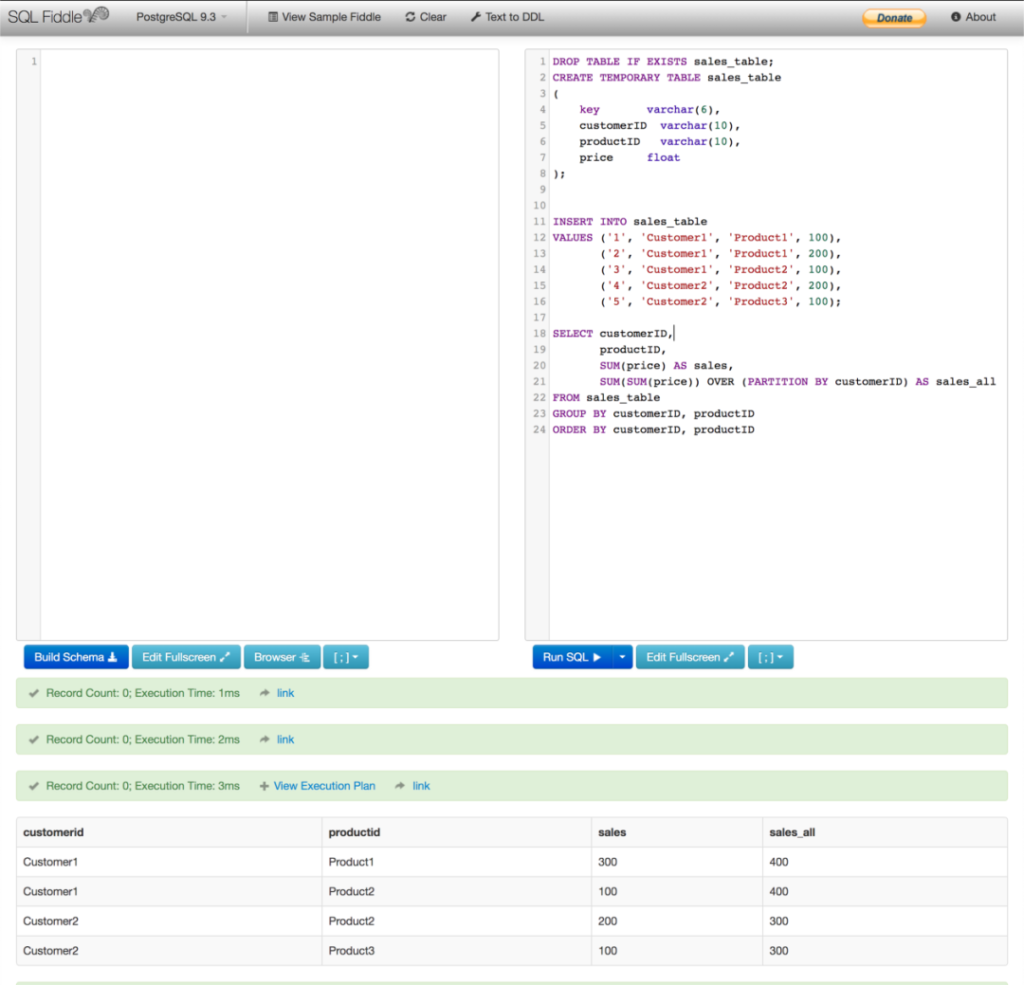
如果你想在本地数据库中跟着练习,可以尝试这个代码(与PostgreSQL 9.3一起使用):
03 用CASE WHEN计算平均值
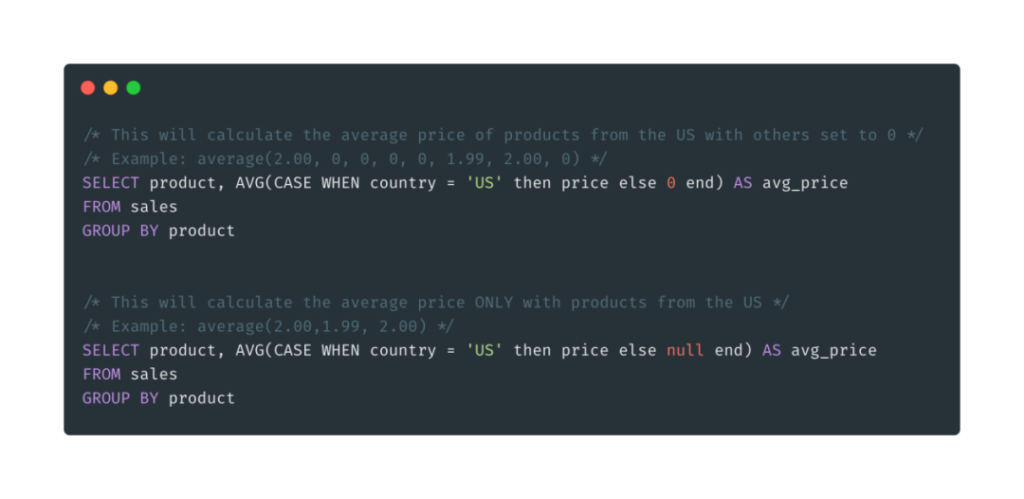
CASE WHEN就像是编程语言中的IF语句。当我们需要计算某个数据子集的统计数据时,它会很有用。
上图中,我计算了美国销售产品的平均价格。在CASE WHEN中,我使用ELSE的时候没有特别注意。
在第一个例子中,我用0表示了所有的非美国产品价格,而这导致了总体平均价格降低。如果有很多非美国的产品,那么平均值可能接近于0。

在第二个例子中,我只计算了在美国销售的产品的平均价格,这也是我们想要的结果。
请注意,使用CASE WHEN时,不是必须包括ELSE的,它的默认值是NULL。

重点是,使用CASE WHEN时,应该小心使用“else 0”。虽然它对SUM没有任何影响,但对AVG影响很大。
04 用Join连接缺少值的列

SQL中有4种不同的连接:内连接(inner join)、外连接(outer join)、左连接(left join)和右连接(right join)。当我们直接使用JOIN时,默认是INNER连接。
之前,我花了时间去阅读一些JOIN相关的教程。但我还是犯了一个低级错误。
我写了一个与上面类似的Join查询。但是当我执行数据验证时,发现很多记录不见了。这只是一个简单的JOIN函数,为什么会出现这种情况呢?
结果表明,表1和表2中都有许多带有NULL值的string_field列。我以为JOIN会保留NULL值的记录,因为NULL值与NULL应该是一样的,不是吗?
所以我做了以下尝试:

返回结果为NULL。
如果想要返回所有条目,就需要处理COALESCE中所有的string_field,它会把所有NULL转换为空字符串。

但要注意的是,这个Join会把table1中的每个空字符串与table2中的每个空字符串连接起来。
删除这些重复项的一种方法,是使用ROW_NUMBER()的窗口函数(window function):
- 我假设你每一行的“ some_id” 都有唯一的标识符和一个时间戳。
- 只需进行整体查询,并留下每个标识符的第一行,就可以删除重复项了。

05 没有在进行复杂查询时使用临时的表

如果我们能够调试查询,那SQL会很好用。那如果我告诉你真的可以调试它们呢?
你可以把一个复杂的查询分解成多个临时的表。然后可以对这些表运行“完整性检查(sanity check)”,确保它们包含了正确的条目。特别是,在设计新的重要查询或报告时,我强烈推荐这种方法。

临时表的唯一缺点,就是查询优化器不能优化临时表里的查询。
需要提升性能时,我会用 WITH 语句重写一条查询。

感谢你的阅读!希望以上内容可以帮助你解决一些SQL中的常见错误。你还可以订阅我们的YouTube频道,观看大量数据科学相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Roman Orac
翻译作者:Lea
美工编辑:过儿
校对审稿:Jiawei Tong
原文链接:https://towardsdatascience.com/dont-repeat-these-5-mistakes-with-sql-9f61d6f5324f




