
四条SQL准则:提升你的数据科学技能
毫无疑问,具备编写SQL的能力是在任何数据科学领域获得成功的必要条件。目前没有任何证据表明这种情况会发生变化,所以,掌握SQL技能是一项非常值得的投资。
无论你是想找数据科学领域的第一份工作,还是要在下一轮就业市场中提高自己的SQL技能,或者是想要提高自己的职业水平,以下有四个原则,可以帮助你在这些方面取得成功。如果你想了解更多数据分析相关内容,可以阅读以下这些文章:
SQL查询语句应该避免的五个错误
初学数据科学常犯的三个SQL错误
如何在Pandas里写SQL查询语句?
数据科学家面试必须掌握的十个SQL概念

那我们直接开始吧。
01 确定正确的粒度(the Right Grain)
这里提到的“粒度(Grain)”是什么意思呢?
SQL查询的粒度,其实就是你想要输出的数据集的聚合级别。
假如你正在找一个汇总日常用户操作的数据集,那么你的“粒度(Grain)”就可以描述为“用户日级别(the user-day level)”(即,每一行代表每个用户每天执行一次操作)。
提前考虑到这点是很好的,主要有以下两个原因:
首先,它能帮助你规划你的查询结构。
当你步入数据科学工作市场时,这一点就显得尤为重要。因为在此过程中,通常要求应聘者对SQL进行实时编写。所以,在开始查询之前构造一个思想框架,能够帮助你更清晰、有效地找到答案,进而给面试官留下深刻的印象。
其次,它能帮助你识别到代码中的错误。
通常,你会对自己编写的sql查询的返回行数有一定的了解。比如,假设我计划的粒度在“用户”级别,而且我还知道我们有大约1,000个用户。当我的查询返回结果中有一个100,000行的数据集时,我就能立刻知道查询中存在一个或多个join的问题。
02 格式很重要
SQL是一种语言,所以我们用SQL建立的查询就是在讲述一个故事。我们要把它写成在未来,自己和同事们都可以轻松阅读的故事。一些快速检查的查询是不需要太在意格式的,但是任何有可能被其他人或者将来的自己读到的查询,都应遵循统一的格式。下面是一个简单但格式很好的查询例子。

以下是一些我深思熟虑后选择的格式:
- 所有关键字都大写(CAPS)
- 新行上的关键字全部右对齐,后续的表达左对齐
- 每个表格都有一个简单又有意义的别名
- 在GROUP BY和ORDER BY子句中使用那个列的数。
我知道有些人会觉得这很“偷懒”,但不得不说,这会节约很多成本,速度很快,而且还可以通过列的别名进行干净的group by。比如,如果我想在GROUP BY子句中使用列名,就必须执行以下操作(大部分情况下这是正确的,某些数据库在GROUP BY中允许使用别名)。
关于SQL格式的观点有很多,但我认为不一定非要分出胜负。你只需要选择其中一个,然后保持一致即可。
03 使用CTE,而不是子查询(Subquery)
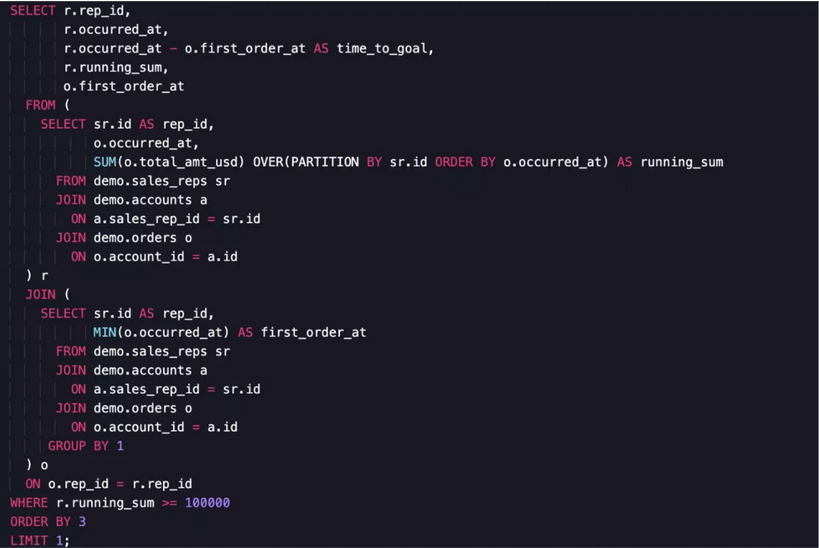
公用表表达式(CTE或Common Table Expressions)是一个临时的数据集,可以在后续的查询中的SQL语句中引用。让我用一个例子来说明CTE,下面的查询找到了从第一笔订单到100,000美元的订单发展最快的销售代表。

让我们来分解一下这个查询的各个部分:
- 首先,你会注意到关键字WITH。使用CTE的所有查询必须在第一个CTE之前包含这个语句。
- first_order_day是我们的第一个CTE。它定义了一个数据集,用于查找销售代表完成订单的第一天。First_order_day还可以在后续表达式中被引用,就像在数据库中引用任何其他表格一样。
- 接下来,我们来定义另一个CTE,running_order_value。它可以用来计算每个销售代表的连续销售总额。
- 最后,我们用两个CTE来返回对应最短time_to_goal的行。
用子查询编写的查询还可以用CTE写,我更建议你这样做,因为这对你的同事还有未来的自己而言,既简洁明了又很容易遵循。而且,我们还可以使用子查询来查看上面的查询。这听起来很颠覆之前的认知,对吧?
总之,通过CTE,在达到相同结果下,还能够提高整体的可读性与逻辑流程。
04 用代码的注释讲故事
虽然说,SQL现在也被看做软件工程中的一种编程语言,但它为什么不像其他语言(比如python)那样,按照标准做法去注释呢?我认为,这很大程度上取决于人们学习SQL的方式。虽然在软件工程中,大多数编程语言在教学过程都会强调这个做法,但在教SQL时,往往是事后才会想到的格式。因为,通常我们只把它当作达到目的的一种手段(即数据集→分析)。
但是,我们在SQL查询分析中做出的一些关键的决定,都取决于我们自己、我们的利益相关者、以及那些审看我们代码(通过注释理解我们意图)的人。
特别是在更为复杂的查询中,注释对于透彻的分析非常有用。
在未来,注释也可以帮助你和查看你代码的人了解你的原始意图。
这大大节省了我们自己和同事重新阅读、审查代码的时间。当我们生成一个用来分析的数据集时,数据科学家会在脑海中确立一个最终目标(比如,我们想看到过去6个月登录的用户访问帮助页面的次数)。记录我们的查询意图,都有助于指导我们编写查询,并帮助审核员判断工作的准确性。
注释能记录相关的数据假设
垃圾进,垃圾出(GIGO:Garbage in Garbage Out)是我们分析时应该优先注意的。简而言之就是,如果你输入了一个无意义的分析或模型数据,你会得到无意义的结果。
这很重要,因为原始数据在被用于分析之前需要建模和聚合。在某些程度上,这也会发生在SQL中(尤其是随着dbt等工具的出现)。所以,当你对你的数据做出假设,或者选择某种类型的集合(例如使用中位数vs.平均值)时,你要在代码的注释中解释你为什么要这样做。如果无法向同事或利益相关者解释,为什么你在查询中包含某个表达式的话,会非常糟糕。
一切源于信任
其实,这四个原则都是基于信任的,而信任是数据科学家拥有的最重要的资产。学习或编写SQL时,遵循这四个原则可以帮助你建立你在面试官、同事和利益相关者中的信任。
感谢你的阅读!你还可以订阅我们的YouTube频道,观看大量数据科学相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Nate Coleman
翻译作者:Lea
美工编辑:过儿
校对审稿:Jiawei Tong
原文链接:https://towardsdatascience.com/4-principles-to-learn-sql-for-data-science-781520c0e983





