
疫情期间大火的Instacart是如何使用数据科学来解决复杂的业务问题的?
Instacart
有一半的美国家庭甚至不用出门就能从他们最喜欢的杂货店(如Costco, Wegman’s, Whole Foods, Petco等)购买食品杂货。
此外,该公司独特的商业模式使其成为一个令人着迷的案例研究,研究如何将数据科学应用于行业,解决棘手的商业问题。
作为一名数据科学家,你已经学习了算法和技术,但是如何将它们应用到可能带来或损失数百万美元的企业世界中呢?在本文中,我们将了解Instacart如何使用数据科学方法来解决其极其复杂的后端系统背后的导入业务问题。
01 Instacart的商业模式
首先,介绍一下Instacart作为一家企业是如何运作的。Instacart做了很多工作来确保用户的体验是顺畅的。这很简单。
- 下载Instacart应用程序。
- 选择一个商店。有很多商店——Whole Foods, Costco, Petco, Wegman’s等等。
- 从商店的库存中,选择您想要添加到购物车中的商品。
- 选择一个小时的时间窗口,你的食品可以在接下来的一个小时内送达。
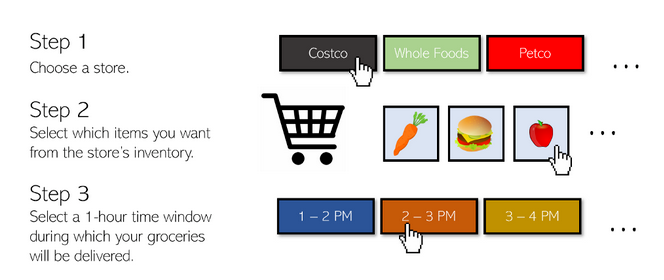
一小时之内,你的食品就送到了你的门前。用户体验难以置信的简单和容易操作。
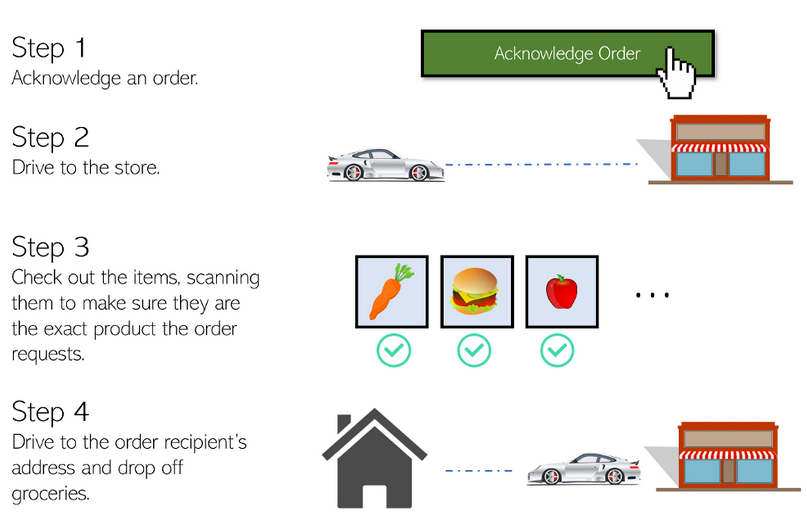
购物者的体验要复杂一些。
- 在Instacart应用程序中,购物者正在换班,当订单进入系统时,他们有机会确认订单。
- 他们开车去订购的商店,并看到你想购买的商品的清单。
- 当他们找到商品时,就会把它们拿起来,然后扫描条形码,以确保这就是你想要的产品。
- 他们会结账,然后开车到你的地址给你送货。
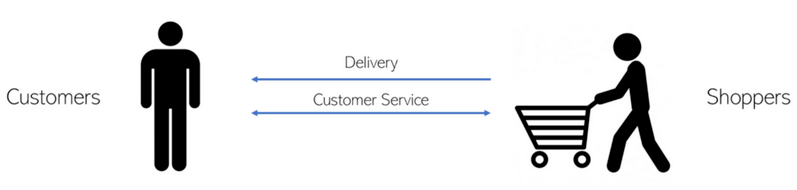
这个市场有两个明显的方面——顾客和客户。然而,Instacart实际上是一个四面市场(你能说出另外两个吗?)
Instacart还与产品广告商和商店合作。这四个方面中的每一个都以某种方式与其他三个进行交互。每一个箭头都是一个给数据科学加强它的机会。
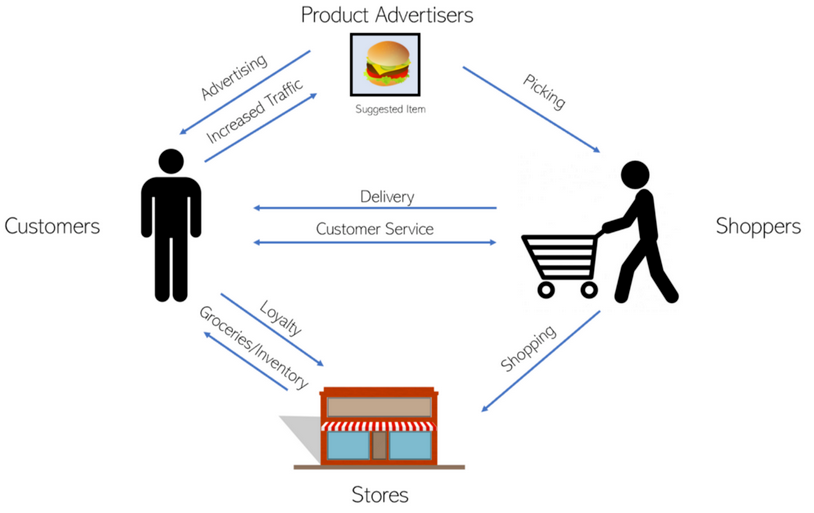
Instacart通过快递费赚钱——例如,支付几美元就能得到快递服务,或者购买快递会员资格(每年150美元,无限快递)。小费和服务费是付给顾客的,这有助于支付人工成本,但这还不够。Instacart也通过与宝洁等公司和广告商的合作来赚钱——Instacart上大约30%的购买都是广告产品。这是数据科学的一条丰富脉络。
该公司也从商店中获得了相当大的一部分收入——如果Instacart能够大幅提升某一家商店的流量,该商店可能会愿意为此支付一定的费用。
然而,Instacart有很多成本,比如交易、信用卡处理和保险。最大的成本是购物者购物和开车所花费的时间,所以Instacart的主要目标是让系统运行得更高效更快,这样就能获得更多利润。
- Instacart说,他们的效率比开始专注于优化后端效率之前提高了40%。
- 快递的客户平均每月花费500美元——使用这项服务的人经常使用它。
- 90%的客户是回头客。
Instacart独特的商业模式让数据科学成为焦点,帮助提高利润,让四方市场的各方都更开心——让我们来看看Instacart面临的一些数据科学问题和挑战。
02 与预测不一致
Instacart是在公路上运营的,所以当像旧金山或纽约这样的大城市出现道路堵塞时,购物者就会被耽搁。当货物到达晚时,顾客会更不高兴。
天气变化非常大——天气冷的时候,顾客不愿意到外面去买杂货,所以他们可能会更多地使用Instacart(更高的需求)。然而,作为一名购物者,你不会想在寒冷的天气外出,所以更少的购物者可能会打卡上班(需求减少)。如果天气好,情况正好相反——更多的人可能想自己去购物(需求少,供应多)。
Instacart——以及全国50%的食品杂货——都受到天气的影响,而他们对此无能为力。
不仅是天气问题,特殊事件以及名人或皇室成员的到访也会造成道路拥堵,影响Instacart的效率。这些不能被当作异常值而不予考虑,因为它们已经发生而且将来还会发生——它们需要被考虑在内。然而,这意味着数据中存在巨大的差异,这使得数据预测变得困难。
收银台排队的可变长度和送货地点可停靠的停车位是另外两个变量,它们因一些可分割的因素(如日期、温度、给定商店的库存等)的组合而变化很大。
在许多数据科学应用中,均值是最重要的——但在Instacart的例子中,方差和均值一样重要。方差会影响预测,使估计的时间难以置信。(你将如何处理这个问题?)
由此,Instacart面临两个主要挑战。首先是如何平衡供求关系?就像之前的天气所证明的那样,供给和需求经常相互作用,而不是朝着有利的平衡发展。需求过多而供应不足会降低客户的满意度和保留率,供应过多而需求过少,对于依赖紧迫感和效率来获取利润的公司来说,意味着生产力的低下。
第二个挑战是,一个供给、一个需求已经达到平衡,如何将购物者的路线安排得尽可能有效率?哪些购物者应该按什么顺序去哪些地点,以最大限度地提高效率,同时确保送货准时?
衡量需求是困难的。
对任何企业来说,度量需求都是评估其执行情况的必要条件。然而,在Instacart的例子中,做到这一点相当困难。
当用户使用Instacart时,他们会指定自己想要的商品到达的送货窗口。由于在某些时段(比如高峰时段)订单会累积,购物者不可能同时处理所有订单,因此Instacart实施了“繁忙定价”,这提高了配送价格。
Instacart使用机器学习模型来预测何时时段会被填满,从而在实际时段被填满之前实施繁忙定价。当时段全满时,Instacart将从可用交付时间列表中删除该时段。该公司还利用销售定价来填补空时段。

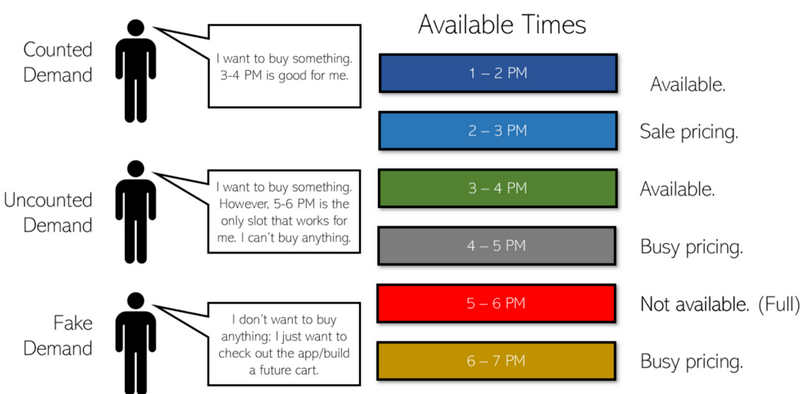
对于每个Instacart用户,有三种结果:
- 他们可以直接结账。
- 他们想要结账,但却离开了,因为没有他们想要的送货方式。
- 他们只是想探索这个应用程序,并没有购买任何东西的意图,也没有为未来构建篮子的意图。
在所有这些场景中,访问者都将访问此页面。你如何区分真正的购买/结帐需求和那些为未来建造篮子的需求,或者只是想探索Instacart的需求?
注:“计算需求”是指计算或已知的需求数量。购买商品的顾客有他们的交易记录。然而,想要购买食品杂货(有需求)但没有留下任何购买记录(没有购买任何东西)的顾客被认为是“未计算需求”。
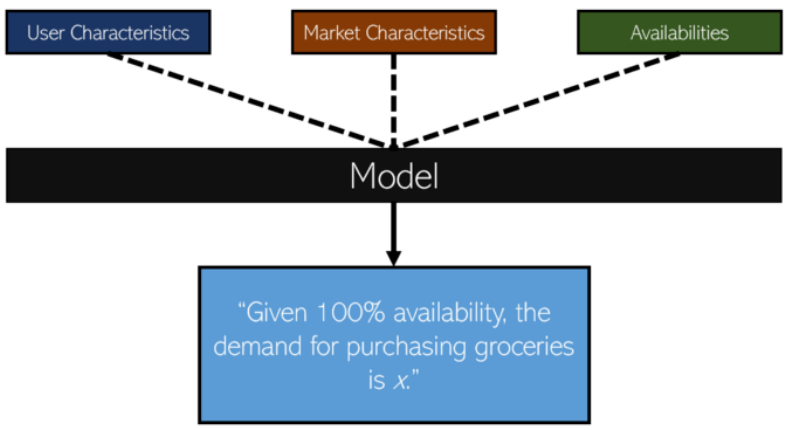
Instacart建立了一个概率模型来预测一个访客在某种情况下购买商品的机会。它考虑了市场和用户的特点,以及他们看到的可用性——哪些窗口是打开的,他们是繁忙价还是销售价,等等。
运行一个对每个人都有100%可用性的预测,这个模型可以估计需求——如果每个人都看到了100%可用性,会有多少交付?计算和未计算的需求都将被考虑,但虚假的需求不会-这是一个聪明的过滤器。
使用这种方法,Instacart用橙色来估计需求量以及“丢失的交货量”(需求量-成功购买的数量)。
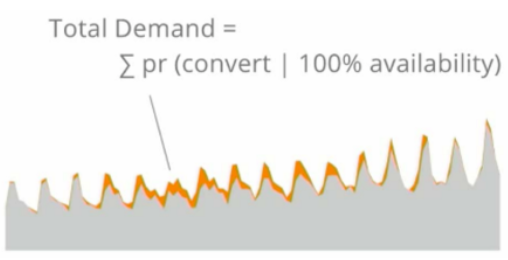
如果Instacart要做任何安排、人员配备或预测,他们希望在正确的需求下进行。现在,他们不仅可以计算,还可以估计损失的交货数量。
03 预测交付完成时间
在一个小时的时间内,Instacart的工作就是在这段时间内送货。否则,顾客的幸福感就会下降——事实上,早一点买到东西会让顾客的幸福感更高。
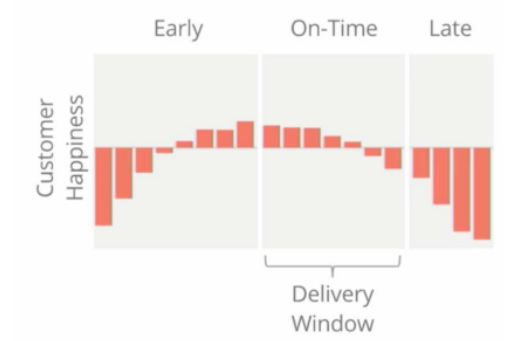
考虑到顾客的快乐是特别重要的,能够估算给定顾客的完成时间,以便他们能够得到最有效的路线是必要的。
你可能会认为Instacart可以使用谷歌地图的出行时间——但Instacart建立了自己的模型,比谷歌地图的出行时间更好。该公司需要建立自己的旅行时间估算器,因为他们的顾客不是传统的司机——他们经常要重复去同一家商店,需要下车,进入商店等等,谷歌地图没有包含这些组件,但Instacart的模型可以。
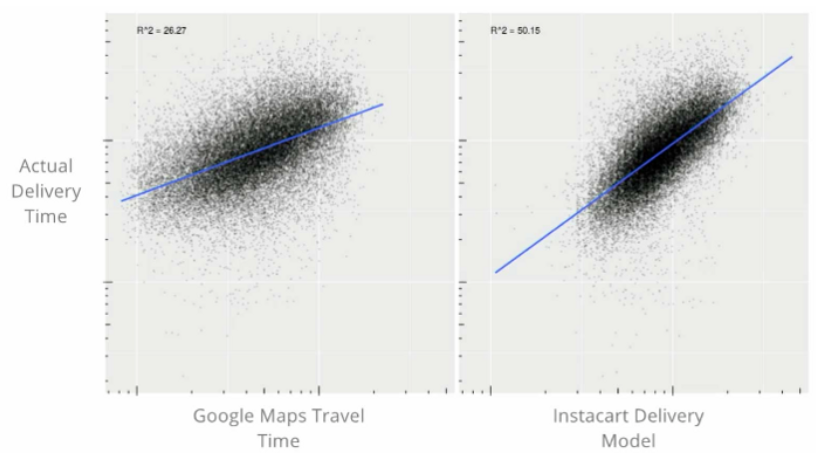
谷歌Maps API不适合Instacart的另一个原因是,它们必须为用户预测Instacart考虑的所有路线组合。有一组候选路径,需要在系统内部进行优化。在估计数万亿路由的执行时间时,等待100毫秒来检查谷歌API是不可行的。
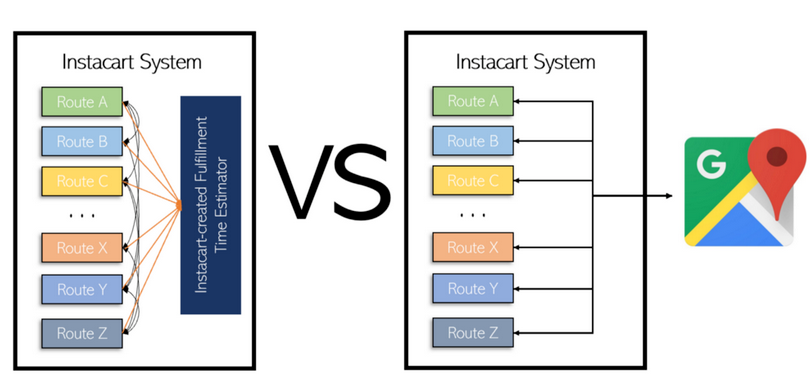
一个内部组件相互通信的系统,一个调整到Instacart特定数据类型的估计器,还是一个需要缓慢外部API的系统?图案由Andre Ye创作。
Instacart使用分位数回归进行预测。而不是找出平均时间,95百分位可能的时间是多少?或者可能是第5个百分点?Instacart的系统考虑了所有步骤中方差的相关性,从而在未来积累方差。
对于模型,Instacart使用梯度增强决策树——它们有过度拟合的倾向(倾向于偏方差尺度上的方差),这对于Instacart的高方差需求是完美的。
他们[梯度增强决策树]可以或多或少地记忆数据,这基本上是我们想要在这里发生的事情。当我们计划所有不同的组合时,我们可以将它们扩展到每分钟数百万次的预测。
——杰里米·斯坦,Instacart
Instacart有一个估算完成时间的好方法——现在它是如何为所有的购物者规划路线的呢?
04为购物者绘制路线
假设你要处理300个订单和100个购物者。尽管每次只有三个订单,但总共有4.45亿次配送组合和100个不同购物者的3组配送组合。Instacart每时每刻都在处理这些问题——这只是一个小例子。
凭直觉,你知道Instacart不会搜索所有的4.45亿个组合,然后选出最重要的一个。
Instacart的目标是最大化所找到的项的数量。
在许多主要城市,有许多相同的商店,只是在不同的位置。如果他们都有相同的产品,购物者可以选择最接近的一个。
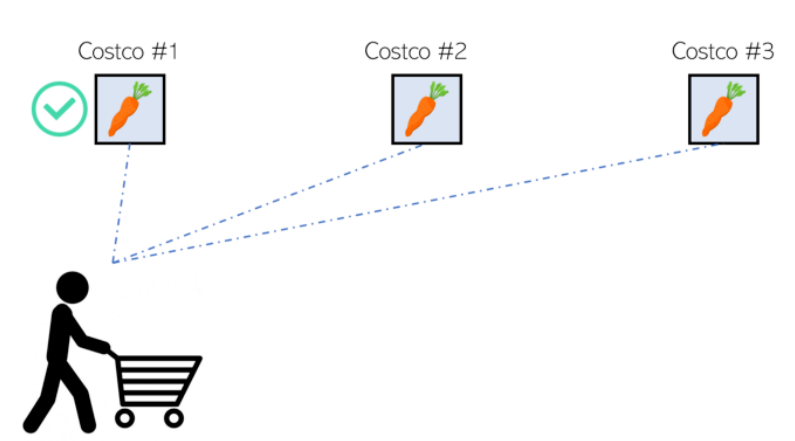
然而,库存并不总是最新的。这意味着,在评估了顾客清单上的产品出现在几家商店库存中的概率后,Instacart可能会用额外的距离来换取顾客满意,因为顾客想要的产品出现在库存中的概率更高。
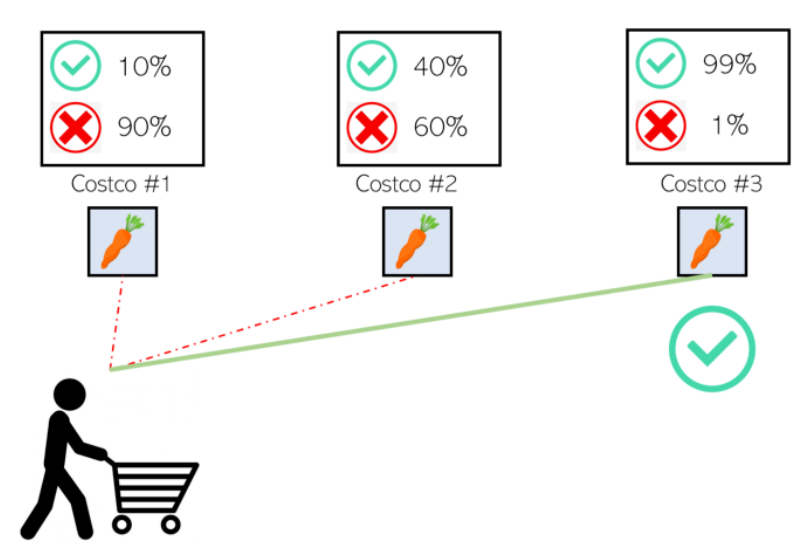
然而,如果事实证明,Costco #1确实有顾客想要的产品,那么Instacart只是把额外的时间浪费在了去更远的商店的路上——同时,顾客也会因为产品准时到达而感到珍贵的快乐。
对Instacart来说,第二秒,从字面上来说,就是钱。

Instacart使用了贪婪启发式——一种聚合可能的交付并对聚合排序的简单方法。事实上,Instacart的第一个算法甚至更简单,它基于一个问题。
05 下次最有可能迟到的交货时间是?
无论答案是什么,算法都会派遣一个购物者来处理它。如果在第一次投递还在及时完成的情况下,列表中还有另一个投递,那么它就会被添加进去——算法就会像这样不断地往下添加。
从那以后,Instacart通过使用高效的机器学习方法对算法进行了巨大的改进——延迟交货减少了20%,损失的交货稳定了,购物速度提高了,忙碌时间增加了20%。
它是复杂的。Instacart每秒进行无数次模拟,以找到在计算上可行的最优路径。
06 结论
后台有很多事情要做。用户体验简单、干净、可靠——如果用户熟悉Instacart应用程序,用户可以在不到一分钟内订购食品杂货。然而,在简洁易用的用户界面背后,是一个由智能机器学习和数据科学决策和应用程序驱动的大型系统,它能让你的日常用品既能让你感到快乐,又能让购物者、商店和广告商感到高兴。
这篇文章是对前Instacart的Jeremy Stan 40分钟演讲的总结。如果你对整个演讲感兴趣,可以在这里访问。所有被认为是“杰里米·斯坦,Instacart”的图片都是从他的幻灯片中提取出来的。
我希望本文能够让您了解看似简单的ui背后的复杂系统,并通过Instacart独特的业务模型作为案例研究,探索和理解如何智能地应用数据科学和机器学习方法来解决实际的业务问题。
原文作者:Andre Ye
翻译作者:过儿
美工编辑:过儿
校对审稿:Dongdong
原文链接:https://medium.com/dataseries/how-instacart-uses-data-science-to-tackle-complex-business-problems-774a826b6ed5





